Terjemahan disediakan oleh mesin penerjemah. Jika konten terjemahan yang diberikan bertentangan dengan versi bahasa Inggris aslinya, utamakan versi bahasa Inggris.
Amazon DocumentDB: cara kerjanya
Amazon DocumentDB (dengan kompatibilitas MongoDB) adalah layanan database yang dikelola sepenuhnya. MongoDB-compatible Dengan Amazon DocumentDB, Anda dapat menjalankan kode aplikasi yang sama dan menggunakan driver dan alat yang sama yang Anda gunakan dengan MongoDB. Amazon DocumentDB kompatibel dengan MongoDB 3.6, 4.0, 5.0, dan 8.0.
Topik
Saat Anda menggunakan Amazon DocumentDB, Anda mulai dengan membuat klaster. Sebuah klaster terdiri dari nol atau lebih instans basis data dan volume klaster yang mengelola data untuk instans tersebut. Volume klaster Amazon DocumentDB adalah volume penyimpanan basis data virtual yang mencakup beberapa Availability Zone. Setiap Availability Zone memiliki salinan data klaster.
Klaster Amazon DocumentDB terdiri dari dua komponen:
-
Volume klaster—Menggunakan layanan penyimpanan cloud-native untuk mereplikasi data dengan enam cara di tiga Availability Zone, menyediakan penyimpanan yang sangat berdaya tahan dan tersedia. Cluster Amazon DocumentDB memiliki tepat satu volume cluster, yang dapat menyimpan hingga 128 TiB data.
-
Instans—Menyediakan kekuatan pemrosesan untuk basis data, menulis data ke, dan membaca data dari, volume penyimpanan klaster. Klaster Amazon DocumentDB dapat memiliki 0–16 instans.
Instans melayani salah satu dari dua peran:
-
Instans primer—Mendukung operasi baca dan tulis, dan melakukan semua modifikasi data ke volume klaster. Setiap klaster Amazon DocumentDB memiliki satu instans primer.
-
Instans replika—Mendukung hanya operasi baca. Setiap klaster Amazon DocumentDB dapat memiliki hingga 15 instans replika selain instans primer. Memiliki beberapa replika memungkinkan Anda untuk mendistribusikan beban kerja baca. Selain itu, dengan menempatkan replika di Availability Zone terpisah, Anda juga meningkatkan ketersediaan klaster.
Diagram berikut mengilustrasikan hubungan antara volume klaster, instans primer, dan replika di klaster Amazon DocumentDB:
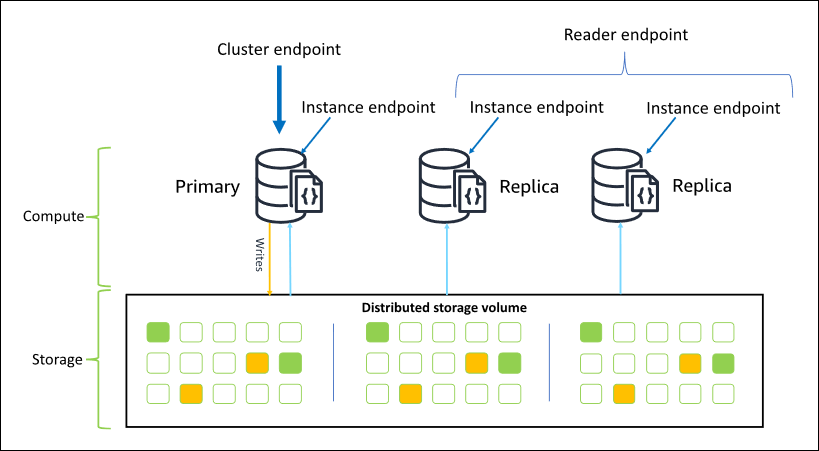
Instans klaster tidak harus dari kelas instans yang sama, dan mereka dapat disediakan dan diakhiri sesuai yang diinginkan. Arsitektur ini memungkinkan Anda menskalakan kapasitas komputasi klaster Anda secara independen dari penyimpanannya.
Saat aplikasi Anda menulis data ke instans primer, yang primer mengeksekusi penulisan yang tahan lama ke volume klaster. Itu kemudian mereplikasi status penulisan itu (bukan data) ke setiap replika aktif. Replika Amazon DocumentDB tidak berpartisipasi dalam pemrosesan tulis, dan dengan demikian replika Amazon DocumentDB menguntungkan untuk penskalaan baca. Pembacaan dari replika Amazon DocumentDB pada akhirnya konsisten dengan jeda replika minimal—biasanya kurang dari 100 milidetik setelah instans primer menulis data. Bacaan dari replika dijamin akan dibaca sesuai urutan penulisannya ke yang primer. Jeda replika bervariasi tergantung pada kecepatan perubahan data, dan periode aktivitas tulis yang tinggi dapat meningkatkan jeda replika. Untuk informasi lebih, lihat metrik ReplicationLag di Metrik Amazon DocumentDB.
Titik akhir Amazon DocumentDB
Amazon DocumentDB menyediakan beberapa opsi koneksi untuk melayani berbagai kasus penggunaan. Untuk terhubung ke instans di klaster Amazon DocumentDB, Anda menentukan titik akhir instans. Sebuah titik akhir adalah alamat host dan nomor port, dipisahkan oleh titik dua.
Kami merekomendasikan Anda terhubung ke klaster menggunakan titik akhir klaster dan dalam mode set replika (lihat Menghubungkan ke Amazon DocumentDB sebagai set replika) kecuali jika Anda memiliki kasus penggunaan khusus untuk menghubungkan ke reader endpoint atau titik akhir instans. Untuk merutekan permintaan ke replika Anda, pilih pengaturan preferensi baca driver yang memaksimalkan penskalaan baca sekaligus memenuhi persyaratan konsistensi baca aplikasi Anda. Preferensi baca secondaryPreferred mengaktifkan pembacaan replika dan membebaskan instans primer untuk melakukan lebih banyak pekerjaan.
Titik akhir berikut tersedia dari klaster Amazon DocumentDB.
Titik Akhir klaster
Titik akhir klaster terhubung ke instans primer klaster Anda saat ini. Titik akhir klaster dapat digunakan untuk operasi baca dan tulis. Sebuah klaster Amazon DocumentDB memiliki tepat satu titik akhir klaster.
Titik akhir klaster menyediakan dukungan failover untuk koneksi baca dan tulis ke klaster. Jika instans primer klaster Anda saat ini gagal, dan klaster Anda memiliki setidaknya satu replika baca aktif, titik akhir klaster secara otomatis mengalihkan permintaan koneksi ke instans primer baru. Saat menghubungkan ke klaster Amazon DocumentDB Anda, kami merekomendasikan Anda menghubungkan ke klaster Anda menggunakan titik akhir klaster dan dalam mode set replika (lihat Menghubungkan ke Amazon DocumentDB sebagai set replika).
Berikut ini adalah contoh titik akhir klaster Amazon DocumentDB:
sample-cluster.cluster-123456789012.us-east-1.docdb.amazonaws.com:27017
Berikut ini adalah contoh koneksi string menggunakan titik akhir klaster ini:
mongodb://username:password@sample-cluster.cluster-123456789012.us-east-1.docdb.amazonaws.com:27017
Untuk informasi tentang menemukan titik akhir klaster, lihat Menemukan titik akhir klaster.
Titik akhir pembaca
Beban reader endpoint menyeimbangkan koneksi baca-saja di semua replika yang tersedia di klaster Anda. Titik akhir pembaca cluster akan tampil sebagai titik akhir cluster jika Anda terhubung melalui replicaSet mode, artinya dalam string koneksi, parameter set replika adalah. &replicaSet=rs0 Dalam hal ini, Anda akan dapat melakukan operasi penulisan pada primer. Namun, jika Anda terhubung ke klaster yang menentukandirectConnection=true, maka mencoba melakukan operasi penulisan melalui koneksi ke titik akhir pembaca menghasilkan kesalahan. Sebuah klaster Amazon DocumentDB memiliki tepat satu reader endpoint.
Jika klaster hanya berisi satu instans (primer), reader endpoint terhubung ke instans primer. Saat Anda menambahkan instans replika ke klaster Amazon DocumentDB, reader endpoint membuka koneksi baca saja ke replika baru setelah itu aktif.
Berikut ini adalah contoh reader endpoint untuk klaster Amazon DocumentDB:
sample-cluster.cluster-ro-123456789012.us-east-1.docdb.amazonaws.com:27017
Berikut ini adalah contoh string koneksi menggunakan reader endpoint:
mongodb://username:password@sample-cluster.cluster-ro-123456789012.us-east-1.docdb.amazonaws.com:27017
Beban reader endpoint menyeimbangkan koneksi baca-saja, bukan permintaan baca. Jika beberapa koneksi reader endpoint lebih banyak digunakan daripada yang lain, permintaan baca Anda mungkin tidak seimbang di antara instans di dalam klaster. Direkomendasikan untuk mendistribusikan permintaan dengan menghubungkan ke titik akhir klaster sebagai set replika dan menggunakan opsi preferensi baca secondaryPreferred.
Untuk informasi tentang menemukan titik akhir klaster, lihat Menemukan titik akhir klaster.
Titik akhir instans
Titik akhir instans terhubung ke instans tertentu dalam klaster Anda. Titik akhir instans untuk instans primer saat ini dapat digunakan untuk operasi baca dan tulis. Namun, mencoba melakukan operasi tulis ke titik akhir instans untuk replika baca akan menghasilkan kesalahan. Klaster Amazon DocumentDB memiliki satu titik akhir instans per instans aktif.
Titik akhir instans memberikan kontrol langsung atas koneksi ke instans tertentu untuk skenario di mana titik akhir klaster atau reader endpoint mungkin tidak sesuai. Contoh kasus penggunaan adalah penyediaan beban kerja analitik baca-saja secara berkala. Anda dapat menyediakan instans replika yang lebih besar dari biasanya, menghubungkan langsung ke instans baru yang lebih besar dengan titik akhir instansnya, menjalankan kueri analitik, lalu menghentikan instans. Menggunakan titik akhir instans menjaga lalu lintas analitik agar tidak memengaruhi instans klaster lainnya.
Berikut ini adalah contoh titik akhir instans untuk instans tunggal di klaster Amazon DocumentDB:
sample-instance.123456789012.us-east-1.docdb.amazonaws.com:27017
Berikut ini adalah contoh string koneksi menggunakan titik akhir instans ini:
mongodb://username:password@sample-instance.123456789012.us-east-1.docdb.amazonaws.com:27017
catatan
Peran instans sebagai primer atau replika dapat berubah karena peristiwa failover. Aplikasi Anda tidak boleh berasumsi bahwa titik akhir instans tertentu adalah instans primer. Kami tidak menyarankan menghubungkan ke titik akhir instans untuk aplikasi produksi. Sebagai gantinya, kami merekomendasikan Anda menyambungkan ke klaster menggunakan titik akhir klaster dan dalam mode set replika (lihat Menghubungkan ke Amazon DocumentDB sebagai set replika). Untuk kendali lebih lanjut dari prioritas failover instans, lihat Memahami toleransi kesalahan klaster Amazon DocumentDB.
Untuk informasi tentang menemukan titik akhir klaster, lihat Menemukan titik akhir instance.
Mode set replika
Anda dapat terhubung ke titik akhir klaster Amazon DocumentDB Anda dalam mode set replika dengan menentukan nama set replika rs0. Menghubungkan dalam mode set replika menyediakan kemampuan untuk menentukan opsi Perhatian Baca, Perhatian Tulis, dan Preferensi Baca. Untuk informasi selengkapnya, lihat Konsistensi baca.
Berikut ini adalah contoh koneksi string yang menghubungkan dalam mode set replika:
mongodb://username:password@sample-cluster.cluster-123456789012.us-east-1.docdb.amazonaws.com:27017/?replicaSet=rs0
Saat Anda terhubung dalam mode set replika, klaster Amazon DocumentDB Anda muncul ke driver dan klien Anda sebagai set replika. Instans yang ditambahkan dan dihapus dari klaster Amazon DocumentDB Anda direfleksikan secara otomatis dalam konfigurasi set replika.
Setiap klaster Amazon DocumentDB terdiri dari set replika tunggal dengan nama default rs0. Nama set replika tidak dapat diubah.
Menghubungkan ke titik akhir klaster dalam mode set replika adalah metode yang disarankan untuk penggunaan umum.
catatan
Semua instans dalam klaster Amazon DocumentDB mendengarkan pada port TCP yang sama untuk koneksi.
Dukungan TLS
Untuk detail selengkapnya tentang menghubungkan ke Amazon DocumentDB menggunakan Transport Layer Security (TLS), lihat Mengenkripsi data dalam perjalanan.
Penyimpanan Amazon DocumentDB
Data Amazon DocumentDB disimpan dalam volume klaster, yang merupakan volume virtual tunggal yang menggunakan solid state drive (SSD). Volume klaster terdiri dari enam salinan data Anda, yang direplikasi secara otomatis di beberapa Availability Zone dalam satu Wilayah AWS. Replikasi ini membantu memastikan bahwa data Anda sangat berdaya tahan, dengan kemungkinan kehilangan data yang lebih kecil. Ini juga membantu memastikan bahwa klaster Anda lebih tersedia selama failover karena salinan data Anda sudah ada di Availability Zone lainnya. Salinan ini dapat terus melayani permintaan data ke instans di klaster Amazon DocumentDB Anda.
Bagaimana penyimpanan data ditagih
Amazon DocumentDB secara otomatis meningkatkan ukuran volume klaster saat jumlah data meningkat. Volume cluster Amazon DocumentDB dapat tumbuh hingga ukuran maksimum 128 TiB; Namun, Anda hanya dikenakan biaya untuk ruang yang Anda gunakan dalam volume cluster Amazon DocumentDB. Dimulai dengan Amazon DocumentDB 4.0, ketika data dihapus, seperti dengan menjatuhkan koleksi atau indeks, keseluruhan ruang yang dialokasikan berkurang dengan jumlah yang sebanding. Dengan demikian, Anda dapat mengurangi biaya penyimpanan dengan menghapus koleksi, indeks, dan database yang tidak lagi Anda perlukan. Di Amazon DocumentDB versi 3.6, volume cluster dapat menggunakan kembali ruang yang dibebaskan saat Anda menghapus data, tetapi volume itu sendiri tidak pernah berkurang ukurannya. Akibatnya di versi 3.6, Anda mungkin tidak menyaksikan perubahan apa pun dalam penyimpanan saat Anda menjatuhkan koleksi atau indeks, meskipun ruang kosong digunakan kembali.
catatan
Dengan Amazon DocumentDB 3.6, biaya penyimpanan didasarkan pada penyimpanan “tanda air tinggi” (jumlah maksimum yang dialokasikan untuk cluster Amazon DocumentDB kapan saja). Anda dapat mengelola biaya dengan menghindari praktik ETL yang membuat volume besar informasi sementara, atau yang memuat volume besar data baru sebelum menghapus data lama yang tidak dibutuhkan. Jika menghapus data dari klaster Amazon DocumentDB menghasilkan sejumlah besar ruang yang dialokasikan tetapi tidak digunakan, mengatur ulang tanda air yang tinggi memerlukan pembuangan data logis dan memulihkan ke klaster baru, menggunakan alat seperti mongodump atau mongorestore. Membuat dan memulihkan snapshot tidak mengurangi penyimpanan yang dialokasikan karena tata letak fisik penyimpanan yang mendasarinya tetap sama di snapshot yang dipulihkan.
catatan
Menggunakan utilitas seperti mongodump dan mongorestore dikenakan I/O biaya berdasarkan ukuran data yang sedang dibaca dan ditulis ke volume penyimpanan.
Untuk informasi tentang penyimpanan I/O dan harga data Amazon DocumentDB, lihat FAQ harga dan Harga Amazon DocumentDB (dengan kompatibilitas MongoDB)
Replikasi Amazon DocumentDB
Dalam klaster Amazon DocumentDB, setiap instans replika menampilkan titik akhir independen. Titik akhir replika ini menyediakan akses baca-saja ke data dalam volume klaster. Mereka memungkinkan Anda untuk menskalakan beban kerja baca untuk data Anda melalui beberapa instans yang direplikasi. Mereka juga membantu meningkatkan performa pembacaan data dan meningkatkan ketersediaan data di klaster Amazon DocumentDB Anda. Replika Amazon DocumentDB juga merupakan target failover dan dengan cepat dipromosikan jika instans primer untuk klaster Amazon DocumentDB Anda gagal.
Keandalan Amazon DocumentDB
Amazon DocumentDB dirancang agar andal, tahan lama, dan toleran terhadap kesalahan. (Untuk meningkatkan ketersediaan, Anda harus mengonfigurasi klaster Amazon DocumentDB Anda sehingga memiliki beberapa instans replika di Availability Zone yang berbeda.) Amazon DocumentDB menyertakan beberapa fitur otomatis yang menjadikannya solusi basis data yang andal.
Perbaikan penyimpanan otomatis
Amazon DocumentDB menyimpan banyak salinan data Anda di tiga Availability Zone, sangat mengurangi kemungkinan kehilangan data karena kegagalan penyimpanan. Amazon DocumentDB secara otomatis mendeteksi kegagalan di dalam volume klaster. Saat segmen dari sebuah volume klaster gagal, Amazon DocumentDB segera memperbaiki segmen tersebut. Ini menggunakan data dari volume lain yang membentuk volume klaster untuk membantu memastikan bahwa data di segmen yang diperbaiki adalah yang terkini. Sebagai hasil, Amazon DocumentDB menghindari kehilangan data dan mengurangi kebutuhan untuk melakukan pemulihan tepat waktu untuk memulihkan dari kegagalan instans.
Pemanasan cache yang bisa bertahan
Amazon DocumentDB mengelola cache halamannya dalam proses terpisah dari basis data sehingga cache halaman dapat bertahan secara independen dari basis data. Jika terjadi kegagalan basis data yang tidak terduga, cache halaman tetap berada di memori. Ini memastikan bahwa kumpulan buffer dihangatkan dengan status terkini saat basis data dimulai ulang.
Pemulihan setelah crash
Amazon DocumentDB dirancang untuk pulih dari crash hampir seketika, dan untuk terus menyajikan data aplikasi Anda. Amazon DocumentDB melakukan pemulihan crash secara asinkron pada utas paralel sehingga basis data Anda terbuka dan tersedia segera setelah kerusakan.
Tata kelola sumber daya
Amazon DocumentDB melindungi sumber daya yang diperlukan untuk menjalankan proses penting dalam layanan, seperti pemeriksaan kondisi. Untuk melakukan ini, dan ketika instans mengalami tekanan memori tinggi, Amazon DocumentDB akan membatasi permintaan. Akibatnya, beberapa operasi mungkin diantrekan untuk menunggu tekanan memori mereda. Jika tekanan memori berlanjut, operasi yang diantrekan mungkin habis. Anda dapat memantau apakah operasi pelambatan layanan karena memori rendah atau tidak dengan CloudWatch metrik berikut:LowMemThrottleQueueDepth,,,LowMemThrottleMaxQueueDepth. LowMemNumOperationsThrottled LowMemNumOperationsTimedOut Untuk informasi selengkapnya, lihat Memantau Amazon CloudWatch DocumentDB dengan. Jika Anda melihat tekanan memori berkelanjutan pada instans Anda sebagai akibat dari LowMem CloudWatch metrik, kami menyarankan Anda meningkatkan skala instance Anda untuk menyediakan memori tambahan untuk beban kerja Anda.
Baca opsi preferensi
Amazon DocumentDB menggunakan layanan penyimpanan bersama cloud-native yang mereplikasi data enam kali di tiga Availability Zone untuk memberikan tingkat ketahanan yang tinggi. Amazon DocumentDB tidak bergantung pada replikasi data ke beberapa instans untuk mencapai ketahanan. Data klaster Anda tahan lama baik berisi satu instans atau 15 instans.
Tulis daya tahan
Amazon DocumentDB menggunakan sistem penyimpanan self-healing yang unik, terdistribusi, toleran terhadap kesalahan. Sistem ini mereplikasi enam salinan (V=6) data Anda di tiga AWS Availability Zone untuk memberikan ketersediaan dan daya tahan tinggi. Ketika menulis data, Amazon DocumentDB memastikan bahwa semua penulisan dicatat secara tahan lama di sebagian besar node sebelum menyatakan penulisan ke klien. Jika Anda menjalankan set replika MongoDB tiga simpul, menggunakan perhatian tulis {w:3, j:true} akan menghasilkan konfigurasi terbaik saat dibandingkan dengan Amazon DocumentDB.
Penulisan ke klaster Amazon DocumentDB harus diproses oleh instans tulis klaster. Mencoba menulis ke pembaca menghasilkan kesalahan. Tulisan yang diakui dari instance utama Amazon DocumentDB tahan lama, dan tidak dapat diputar kembali. Amazon DocumentDB sangat berdaya tahan secara default dan tidak mendukung opsi tulis yang tidak tahan lama. Anda tidak dapat mengubah tingkat daya tahan (yaitu, perhatian tulis). Amazon DocumentDB mengabaikan w=anything dan secara efektif w: 3 dan j: true. Anda tidak dapat menguranginya.
Karena penyimpanan dan komputasi dipisahkan di dalam arsitektur Amazon DocumentDB, klaster dengan satu instans sangat berdaya tahan. Daya tahan ditangani di lapisan penyimpanan. Hasilnya, klaster Amazon DocumentDB dengan satu instans dan satu dengan tiga instans mencapai tingkat ketahanan yang sama. Anda dapat mengonfigurasi klaster Anda ke kasus penggunaan spesifik Anda sambil tetap memberikan daya tahan tinggi untuk data Anda.
Penulisan ke klaster Amazon DocumentDB bersifat atomik dalam satu dokumen.
Amazon DocumentDB tidak mendukung opsi wtimeout dan tidak akan mengembalikan kesalahan jika nilai ditentukan. Penulisan ke instans Amazon DocumentDB primer dijamin tidak akan diblokir tanpa batas waktu.
Baca isolasi
Pembacaan dari instans Amazon DocumentDB hanya mengembalikan data yang tahan lama sebelum kueri dimulai. Pembacaan tidak pernah mengembalikan data yang dimodifikasi setelah kueri memulai eksekusi, juga bacaan kotor tidak mungkin dilakukan dalam keadaan apa pun.
Konsistensi baca
Data yang dibaca dari klaster Amazon DocumentDB tahan lama dan tidak akan dibatalkan. Anda dapat mengubah konsistensi baca untuk pembacaan Amazon DocumentDB dengan menentukan preferensi baca untuk permintaan atau koneksi. Amazon DocumentDB tidak mendukung opsi baca yang tidak tahan lama.
Pembacaan dari instans primer klaster Amazon DocumentDB sangat konsisten dalam kondisi operasi normal dan memiliki konsistensi baca-setelah-tulis. Jika peristiwa failover terjadi antara penulisan dan pembacaan berikutnya, sistem dapat secara singkat mengembalikan pembacaan yang tidak sangat konsisten. Semua pembacaan dari replika baca pada akhirnya konsisten dan mengembalikan data dalam urutan yang sama, dan seringkali dengan jeda replika kurang dari 100 mili detik.
Preferensi baca Amazon DocumentDB
Amazon DocumentDB mendukung pengaturan opsi preferensi baca hanya saat membaca data dari titik akhir klaster dalam mode set replika. Mengatur opsi preferensi baca memengaruhi cara klien atau driver MongoDB Anda merutekan permintaan baca ke instans di klaster Amazon DocumentDB Anda. Anda dapat mengatur opsi preferensi baca untuk kueri tertentu, atau sebagai opsi umum di driver MongoDB Anda. (Konsultasikan dokumentasi klien atau driver Anda untuk petunjuk tentang bagaimana cara mengatur opsi preferensi baca.)
Jika klien atau driver Anda tidak terhubung ke titik akhir klaster Amazon DocumentDB dalam mode set replika, hasil penentuan preferensi baca tidak ditentukan.
Amazon DocumentDB tidak mendukung pengaturan set tag sebagai preferensi baca.
Opsi Preferensi Baca Yang Didukung
-
primary—Menentukan preferensi bacaprimarymembantu memastikan bahwa semua pembacaan dirutekan ke instans primer klaster. Jika instans primer tidak tersedia, operasi baca gagal. Preferensi bacaprimarymenghasilkan konsistensi baca-setelah-tulis dan sesuai untuk kasus penggunaan yang memprioritaskan konsistensi baca-setelah-tulis daripada ketersediaan tinggi dan penskalaan baca.Contoh berikut menentukan preferensi baca
primary:db.example.find().readPref('primary') -
primaryPreferred—Menentukan rute preferensi bacaprimaryPreferredmembaca ke instans primer dalam operasi normal. Jika ada failover primer, klien merutekan permintaan ke replika. Preferensi bacaprimaryPreferredmenghasilkan konsistensi baca-setelah-tulis selama operasi normal, dan pada akhirnya pembacaan yang konsisten selama peristiwa failover. Preferensi bacaprimaryPreferredsesuai untuk kasus penggunaan yang memprioritaskan konsistensi baca-setelah-tulis daripada penskalaan baca, tetapi masih memerlukan ketersediaan tinggi.Contoh berikut menentukan preferensi baca
primaryPreferred:db.example.find().readPref('primaryPreferred') -
secondary—Menentukan preferensi bacasecondarymemastikan bahwa pembacaan hanya dirutekan ke replika, tidak pernah ke instans primer. Jika tidak ada instans replika dalam sebuah klaster, permintaan baca akan gagal. Preferensi bacasecondarymenghasilkan bacaan akhir konsisten dan sesuai untuk kasus penggunaan yang memprioritaskan throughput tulis instans primer daripada ketersediaan tinggi dan konsistensi baca-setelah-tulis.Contoh berikut menentukan preferensi baca
secondary:db.example.find().readPref('secondary') -
secondaryPreferred—Menentukan preferensi bacasecondaryPreferredmemastikan bahwa pembacaan dirutekan ke replika baca saat satu atau beberapa replika aktif. Jika tidak ada instans replika aktif dalam sebuah klaster, permintaan baca akan dirutekan ke instans primer. Preferensi bacasecondaryPreferredmenghasilkan bacaan akhir konsisten saat pembacaan dilayani oleh replika baca. Ini menghasilkan konsistensi baca-setelah-tulis ketika pembacaan dilayani oleh instans primer (kecuali peristiwa failover). Preferensi bacasecondaryPreferredsesuai untuk kasus penggunaan yang memprioritaskan penskalaan baca dan ketersediaan tinggi daripada konsistensi baca-setelah-tulis.Contoh berikut menentukan preferensi baca
secondaryPreferred:db.example.find().readPref('secondaryPreferred') -
nearest—Menentukan rute preferensi bacanearestmembaca hanya berdasarkan latensi terukur antara klien dan semua instans di klaster Amazon DocumentDB. Preferensi bacanearestmenghasilkan bacaan akhir konsisten saat pembacaan dilayani oleh replika baca. Ini menghasilkan konsistensi baca-setelah-tulis ketika pembacaan dilayani oleh instans primer (kecuali peristiwa failover). Preferensi bacanearestsesuai untuk kasus penggunaan yang memprioritaskan pencapaian latensi baca serendah mungkin dan ketersediaan tinggi dibandingkan konsistensi baca-setelah-tulis dan penskalaan baca.Contoh berikut menentukan preferensi baca
nearest:db.example.find().readPref('nearest')
Ketersediaan tinggi
Amazon DocumentDB mendukung konfigurasi klaster yang sangat tersedia dengan menggunakan replika sebagai target failover untuk instans primer. Jika instans primer gagal, replika Amazon DocumentDB dipromosikan sebagai primer baru, dengan gangguan singkat selama permintaan baca dan tulis yang dibuat ke instans primer gagal dengan pengecualian.
Jika klaster Amazon DocumentDB Anda tidak menyertakan replika apa pun, instans primer akan dibuat ulang selama kegagalan. Namun, mempromosikan replika Amazon DocumentDB jauh lebih cepat daripada membuat ulang instans primer. Jadi kami merekomendasikan Anda membuat satu atau beberapa replika Amazon DocumentDB sebagai target failover.
Replika yang dimaksudkan untuk digunakan sebagai target failover harus dari kelas instans yang sama dengan instans primer. Mereka harus disediakan di Availability Zone yang berbeda dari yang primer. Anda dapat mengontrol replika mana yang lebih disukai sebagai target failover. Untuk praktik terbaik dalam mengonfigurasi Amazon DocumentDB untuk ketersediaan tinggi, lihat Memahami toleransi kesalahan klaster Amazon DocumentDB.
Penskalaan dibaca
Replika Amazon DocumentDB ideal untuk penskalaan baca. Mereka sepenuhnya didedikasikan untuk membaca operasi pada volume klaster Anda, yaitu, replika tidak memproses penulisan. Replikasi data terjadi dalam volume klaster dan bukan di antara instans. Jadi setiap sumber daya replika didedikasikan untuk memproses kueri Anda, bukan mereplikasi dan menulis data.
Jika aplikasi Anda membutuhkan lebih banyak kapasitas baca, Anda dapat menambahkan replika ke klaster Anda dengan cepat (biasanya dalam waktu kurang dari sepuluh menit). Jika persyaratan kapasitas baca Anda berkurang, Anda dapat menghapus replika yang tidak dibutuhkan. Dengan replika Amazon DocumentDB, Anda hanya membayar untuk kapasitas baca yang Anda butuhkan.
Amazon DocumentDB mendukung penskalaan baca sisi klien melalui penggunaan opsi Preferensi Baca. Untuk informasi selengkapnya, lihat Preferensi baca Amazon DocumentDB.
TTL menghapus
Penghapusan dari area indeks TTL yang dicapai melalui proses latar belakang adalah upaya terbaik dan tidak dijamin dalam jangka waktu tertentu. Faktor-faktor seperti ukuran instans, pemanfaatan sumber daya instans, ukuran dokumen, dan throughput keseluruhan dapat memengaruhi waktu penghapusan TTL.
Saat monitor TTL menghapus dokumen Anda, setiap penghapusan dikenakan biaya IO, yang akan menambah tagihan Anda. Jika throughput dan tingkat penghapusan TTL meningkat, Anda harus mengharapkan kenaikan tagihan Anda karena peningkatan penggunaan IO.
Saat Anda membuat indeks TTL pada koleksi yang ada, Anda harus menghapus semua dokumen yang kedaluwarsa sebelum membuat indeks. Implementasi TTL saat ini dioptimalkan untuk menghapus sebagian kecil dokumen dalam koleksi, yang biasa terjadi jika TTL diaktifkan pada koleksi dari awal, dan dapat menghasilkan IOPS yang lebih tinggi daripada yang diperlukan jika sejumlah besar dokumen perlu dihapus dalam sekali jalan.
Jika Anda tidak ingin membuat indeks TTL untuk menghapus dokumen, Anda dapat mengelompokkan dokumen ke dalam koleksi berdasarkan waktu, dan cukup membuang koleksi tersebut saat dokumen tidak lagi diperlukan. Misalnya: Anda dapat membuat satu koleksi per minggu dan membuangnya tanpa mengeluarkan biaya IO. Ini dapat secara signifikan menghemat biaya daripada menggunakan indeks TTL.
Sumber daya yang dapat ditagih
Mengidentifikasi sumber daya Amazon DocumentDB yang dapat ditagih
Sebagai layanan database yang dikelola sepenuhnya, Amazon DocumentDB mengenakan biaya untuk instans, penyimpanan, pencadangan I/Os, dan transfer data. Untuk informasi selengkapnya, lihat Harga Amazon DocumentDB (dengan kompatibilitas MongoDB)
Untuk menemukan sumber daya yang dapat ditagih di akun Anda dan berpotensi menghapus sumber daya, Anda dapat menggunakan atau. Konsol Manajemen AWS AWS CLI
Menggunakan Konsol Manajemen AWS
Dengan menggunakan Konsol Manajemen AWS, Anda dapat menemukan klaster Amazon DocumentDB, instance, dan snapshot yang telah Anda sediakan untuk diberikan. Wilayah AWS
Untuk menemukan klaster, instans, dan snapshot
Masuk ke Konsol Manajemen AWS, dan buka konsol Amazon DocumentDB di. https://console.aws.amazon.com/docdb
-
Untuk menemukan sumber daya yang dapat ditagih di Wilayah selain Wilayah default Anda, di sudut kanan atas layar, pilih yang ingin Anda cari. Wilayah AWS
-
Di panel navigasi, pilih tipe sumber daya yang dapat ditagih yang Anda minati: Klaster, Instans, atau Snapshot.
-
Semua klaster, instans, atau snapshot yang Anda sediakan untuk Wilayah terdaftar di panel kanan. Anda akan dikenakan biaya untuk klaster, instans, dan snapshot.
Menggunakan AWS CLI
Dengan menggunakan AWS CLI, Anda dapat menemukan klaster Amazon DocumentDB, instance, dan snapshot yang telah Anda sediakan untuk diberikan. Wilayah AWS
Untuk menemukan klaster dan instans
Kode berikut mencantumkan semua klaster dan instans Anda untuk Wilayah yang ditentukan. Jika Anda ingin mencari klaster dan instans di Wilayah default, Anda dapat menghilangkan parameter --region.
contoh
Untuk Linux, macOS, atau Unix:
aws docdb describe-db-clusters \ --region us-east-1 \ --query 'DBClusters[?Engine==`docdb`]' | \ grep -e "DBClusterIdentifier" -e "DBInstanceIdentifier"
Untuk Windows:
aws docdb describe-db-clusters ^ --region us-east-1 ^ --query 'DBClusters[?Engine==`docdb`]' | ^ grep -e "DBClusterIdentifier" -e "DBInstanceIdentifier"
Output dari operasi ini terlihat seperti berikut ini.
"DBClusterIdentifier": "docdb-2019-01-09-23-55-38",
"DBInstanceIdentifier": "docdb-2019-01-09-23-55-38",
"DBInstanceIdentifier": "docdb-2019-01-09-23-55-382",
"DBClusterIdentifier": "sample-cluster",
"DBClusterIdentifier": "sample-cluster2",Untuk menemukan snapshot
Kode berikut mencantumkan semua snapshot Anda untuk Wilayah yang ditentukan. Jika Anda ingin mencari snapshot di Wilayah default Anda, Anda dapat menghilangkan parameter --region.
Untuk Linux, macOS, atau Unix:
aws docdb describe-db-cluster-snapshots \ --region us-east-1 \ --query 'DBClusterSnapshots[?Engine==`docdb`].[DBClusterSnapshotIdentifier,SnapshotType]'
Untuk Windows:
aws docdb describe-db-cluster-snapshots ^ --region us-east-1 ^ --query 'DBClusterSnapshots[?Engine==`docdb`].[DBClusterSnapshotIdentifier,SnapshotType]'
Output dari operasi ini terlihat seperti berikut ini.
[
[
"rds:docdb-2019-01-09-23-55-38-2019-02-13-00-06",
"automated"
],
[
"test-snap",
"manual"
]
]Anda hanya perlu menghapus snapshot manual. Snapshot Automated dihapus saat Anda menghapus klaster.
Menghapus sumber daya yang tidak dapat ditagih
Untuk menghapus klaster, Anda harus menghapus semua instans di klaster terlebih dahulu.
-
Untuk menghapus instans, lihat Menghapus instans Amazon DocumentDB.
penting
Meskipun Anda menghapus instans dalam sebuah klaster, Anda masih ditagih untuk penggunaan penyimpanan dan pencadangan yang terkait dengan klaster tersebut. Untuk menghentikan semua tagihan, Anda juga harus menghapus klaster dan snapshot manual.
-
Untuk menghapus klaster, lihat Menghapus cluster Amazon DocumentDB.
-
Untuk menghapus snapshot manual, lihat Menghapus snapshot cluster.
