Terjemahan disediakan oleh mesin penerjemah. Jika konten terjemahan yang diberikan bertentangan dengan versi bahasa Inggris aslinya, utamakan versi bahasa Inggris.
Teori Penskalaan Kubernetes
Node vs Tingkat Churn
Seringkali ketika kita membahas skalabilitas Kubernetes, kita melakukannya dalam hal berapa banyak node yang ada dalam satu cluster. Menariknya, ini jarang merupakan metrik yang paling berguna untuk memahami skalabilitas. Misalnya, cluster 5.000 node dengan jumlah pod yang besar tetapi tetap tidak akan memberikan banyak tekanan pada bidang kontrol setelah penyiapan awal. Namun, jika kita mengambil cluster 1.000 node dan mencoba menciptakan 10.000 pekerjaan berumur pendek dalam waktu kurang dari satu menit, itu akan memberikan banyak tekanan berkelanjutan pada bidang kontrol.
Cukup menggunakan jumlah node untuk memahami penskalaan bisa menyesatkan. Lebih baik berpikir dalam hal tingkat perubahan yang terjadi dalam periode waktu tertentu (mari kita gunakan interval 5 menit untuk diskusi ini, karena inilah yang biasanya digunakan kueri Prometheus secara default). Mari kita jelajahi mengapa membingkai masalah dalam hal tingkat perubahan dapat memberi kita gambaran yang lebih baik tentang apa yang harus disetel untuk mencapai skala yang kita inginkan.
Berpikir dalam Pertanyaan Per Detik
Kubernetes memiliki sejumlah mekanisme perlindungan untuk setiap komponen - Kubelet, Scheduler, Kube Controller Manager, dan API server - untuk mencegah kewalahan link berikutnya dalam rantai Kubernetes. Misalnya, Kubelet memiliki flag untuk membatasi panggilan ke server API pada tingkat tertentu. Mekanisme perlindungan ini umumnya, tetapi tidak selalu, dinyatakan dalam hal kueri yang diizinkan berdasarkan per detik atau QPS.
Perhatian besar harus diberikan saat mengubah pengaturan QPS ini. Menghapus satu kemacetan, seperti kueri per detik pada Kubelet akan berdampak pada komponen downstream lainnya. Ini dapat dan akan membanjiri sistem di atas tingkat tertentu, sehingga memahami dan memantau setiap bagian dari rantai layanan adalah kunci untuk berhasil menskalakan beban kerja di Kubernetes.
catatan
Server API memiliki sistem yang lebih kompleks dengan pengenalan API Priority and Fairness yang akan kita bahas secara terpisah.
catatan
Perhatian, beberapa metrik tampak cocok tetapi sebenarnya mengukur sesuatu yang lain. Sebagai contoh, hanya kubelet_http_inflight_requests berkaitan dengan server metrik di Kubelet, bukan jumlah permintaan dari Kubelet ke permintaan apiserver. Ini dapat menyebabkan kita salah mengkonfigurasi flag QPS di Kubelet. Kueri pada log audit untuk Kubelet tertentu akan menjadi cara yang lebih andal untuk memeriksa metrik.
Penskalaan Komponen Terdistribusi
Karena EKS adalah layanan terkelola, mari kita bagi komponen Kubernetes menjadi dua kategori: komponen yang dikelola AWS yang meliputi etcd, Kube Controller Manager, dan Scheduler (di bagian kiri diagram), dan komponen yang dapat dikonfigurasi pelanggan seperti Kubelet, Container Runtime, dan berbagai operator yang memanggil APIs AWS seperti driver Networking and Storage (di bagian kanan diagram). Kami meninggalkan server API di tengah meskipun AWS dikelola, karena pengaturan untuk Prioritas dan Keadilan API dapat dikonfigurasi oleh pelanggan.
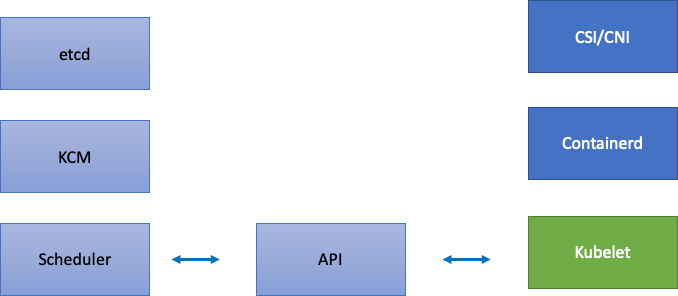
Kemacetan Hulu dan Hilir
Saat kami memantau setiap layanan, penting untuk melihat metrik di kedua arah untuk mencari kemacetan. Mari kita belajar bagaimana melakukan ini dengan menggunakan Kubelet sebagai contoh. Kubelet berbicara baik ke server API dan runtime container; bagaimana dan apa yang perlu kita pantau untuk mendeteksi apakah salah satu komponen mengalami masalah?
Berapa banyak Pod per Node
Ketika kita melihat angka penskalaan, seperti berapa banyak Pod yang dapat dijalankan pada sebuah node, kita dapat mengambil 110 pod per node yang didukung upstream pada nilai nominal.
Namun, beban kerja Anda kemungkinan lebih kompleks daripada yang diuji dalam uji skalabilitas di Upstream. Untuk memastikan kita dapat melayani jumlah pod yang ingin kita jalankan dalam produksi, mari kita pastikan bahwa Kubelet “mengikuti” runtime Containerd.
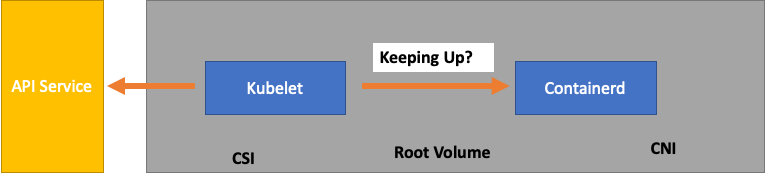
Untuk menyederhanakan, Kubelet mendapatkan status pod dari runtime container (dalam kasus kami Containerd). Bagaimana jika kita memiliki terlalu banyak pod yang mengubah status terlalu cepat? Jika tingkat perubahan terlalu tinggi, permintaan [ke runtime kontainer] dapat batas waktu.
catatan
Kubernetes terus berkembang, subsistem ini saat ini sedang mengalami perubahan. https://github.com/kubernetes/peningkatan/masalah/3386

Pada grafik di atas, kita melihat garis datar yang menunjukkan bahwa kita baru saja mencapai nilai batas waktu untuk metrik durasi pembuatan peristiwa siklus hidup pod. Jika Anda ingin melihat ini di cluster Anda sendiri, Anda dapat menggunakan sintaks promQL berikut.
increase(kubelet_pleg_relist_duration_seconds_bucket{instance="$instance"}[$__rate_interval])
Jika kita menyaksikan perilaku batas waktu ini, kita tahu kita mendorong node melebihi batas yang mampu dilakukannya. Kita perlu memperbaiki penyebab batas waktu sebelum melanjutkan lebih jauh. Ini dapat dicapai dengan mengurangi jumlah pod per node, atau mencari kesalahan yang mungkin menyebabkan volume percobaan ulang yang tinggi (sehingga mempengaruhi laju churn). Take-away yang penting adalah bahwa metrik adalah cara terbaik untuk memahami apakah sebuah node mampu menangani churn rate dari pod yang ditetapkan vs. menggunakan nomor tetap.
Skala menurut Metrik
Meskipun konsep menggunakan metrik untuk mengoptimalkan sistem sudah lama, konsep ini sering diabaikan saat orang memulai perjalanan Kubernetes mereka. Alih-alih berfokus pada angka tertentu (yaitu 110 pod per node), kami memfokuskan upaya kami untuk menemukan metrik yang membantu kami menemukan kemacetan di sistem kami. Memahami ambang batas yang tepat untuk metrik ini dapat memberi kami tingkat kepercayaan yang tinggi, sistem kami dikonfigurasi secara optimal.
Dampak Perubahan
Pola umum yang bisa membuat kita mendapat masalah adalah berfokus pada metrik pertama atau kesalahan log yang terlihat mencurigakan. Ketika kami melihat bahwa Kubelet sudah habis waktu sebelumnya, kami dapat mencoba hal-hal acak, seperti meningkatkan tarif per detik yang diizinkan untuk dikirim oleh Kubelet, dll. Namun, adalah bijaksana untuk melihat seluruh gambaran dari segala sesuatu di hilir kesalahan yang kita temukan terlebih dahulu. Buat setiap perubahan dengan tujuan dan didukung oleh data.
Hilir Kubelet akan menjadi runtime Containerd (kesalahan pod), DaemonSets seperti driver penyimpanan (CSI) dan driver jaringan (CNI) yang berbicara dengan API, dll. EC2
Mari kita lanjutkan contoh Kubelet kita sebelumnya yang tidak mengikuti runtime. Ada sejumlah titik di mana kita bisa mengemas node dengan sangat padat sehingga memicu kesalahan.
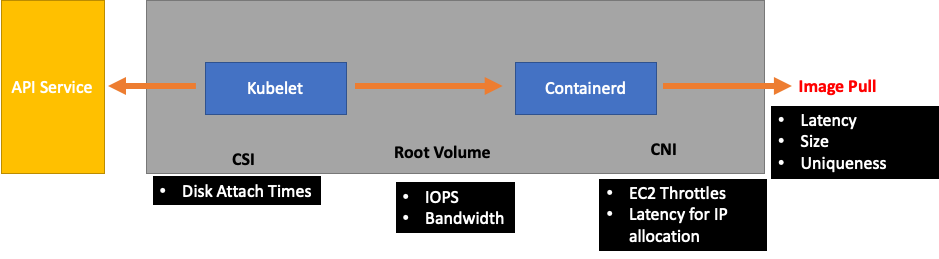
Saat merancang ukuran node yang tepat untuk beban kerja kami, ini adalah easy-to-overlook sinyal yang mungkin memberikan tekanan yang tidak perlu pada sistem sehingga membatasi skala dan kinerja kami.
Biaya Kesalahan yang Tidak Perlu
Pengontrol Kubernetes unggul dalam mencoba lagi ketika kondisi kesalahan muncul, namun ini membutuhkan biaya. Percobaan ulang ini dapat meningkatkan tekanan pada komponen seperti Kube Controller Manager. Ini adalah penyewa penting pengujian skala untuk memantau kesalahan tersebut.
Ketika lebih sedikit kesalahan yang terjadi, lebih mudah menemukan masalah dalam sistem. Dengan secara berkala memastikan bahwa klaster kami bebas dari kesalahan sebelum operasi besar (seperti peningkatan), kami dapat menyederhanakan log pemecahan masalah ketika peristiwa yang tidak terduga terjadi.
Memperluas Pandangan Kami
Dalam cluster skala besar dengan 1.000 node, kami tidak ingin mencari kemacetan satu per satu. Dalam promQL kita dapat menemukan nilai tertinggi dalam kumpulan data menggunakan fungsi yang disebut topk; K menjadi variabel kita menempatkan jumlah item yang kita inginkan. Di sini kita menggunakan tiga node untuk mendapatkan ide apakah semua Kubelet di cluster sudah jenuh. Kami telah melihat latensi hingga saat ini, sekarang mari kita lihat apakah Kubelet membuang peristiwa.
topk(3, increase(kubelet_pleg_discard_events{}[$__rate_interval]))
Memecah pernyataan ini.
-
Kami menggunakan variabel Grafana
$__rate_intervaluntuk memastikannya mendapatkan empat sampel yang dibutuhkannya. Ini melewati topik kompleks dalam pemantauan dengan variabel sederhana. -
topkberi kami hasil teratas dan angka 3 membatasi hasil tersebut menjadi tiga. Ini adalah fungsi yang berguna untuk metrik luas cluster. -
{}beri tahu kami tidak ada filter, biasanya Anda akan memasukkan nama pekerjaan apa pun aturan pengikisan, namun karena nama-nama ini bervariasi, kami akan membiarkannya kosong.
Memisahkan Masalah Menjadi Setengah
Untuk mengatasi kemacetan dalam sistem, kami akan mengambil pendekatan menemukan metrik yang menunjukkan kepada kami ada masalah di hulu atau hilir karena ini memungkinkan kami untuk membagi masalah menjadi dua. Ini juga akan menjadi prinsip inti bagaimana kami menampilkan data metrik kami.
Tempat yang baik untuk memulai dengan proses ini adalah server API, karena memungkinkan kita untuk melihat apakah ada masalah dengan aplikasi klien atau Control Plane.
