Terjemahan disediakan oleh mesin penerjemah. Jika konten terjemahan yang diberikan bertentangan dengan versi bahasa Inggris aslinya, utamakan versi bahasa Inggris.
Node dan Efisiensi Beban Kerja
Menjadi efisien dengan beban kerja dan node kami mengurangi complexity/cost sekaligus meningkatkan kinerja dan skala. Ada banyak faktor yang perlu dipertimbangkan ketika merencanakan efisiensi ini, dan paling mudah untuk berpikir dalam hal trade off vs. satu pengaturan praktik terbaik untuk setiap fitur. Mari kita jelajahi pengorbanan ini secara mendalam di bagian berikut.
Pemilihan Node
Menggunakan ukuran node yang sedikit lebih besar (4-12xlarge) meningkatkan ruang yang tersedia yang kita miliki untuk menjalankan pod karena fakta itu mengurangi persentase node yang digunakan untuk “overhead” seperti DaemonSets
catatan
Karena k8s menskalakan secara horizontal sebagai aturan umum, untuk sebagian besar aplikasi, tidak masuk akal untuk mengambil dampak kinerja node ukuran NUMA, sehingga rekomendasi rentang di bawah ukuran node tersebut.
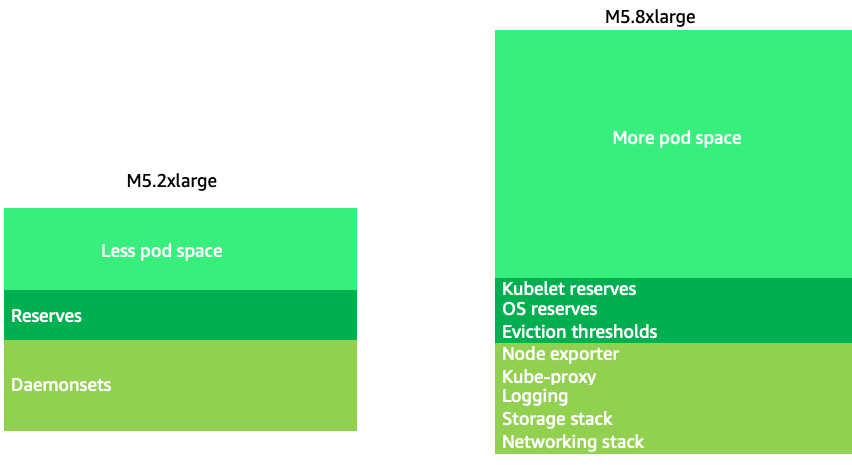
Ukuran node yang besar memungkinkan kita untuk memiliki persentase yang lebih tinggi dari ruang yang dapat digunakan per node. Namun, model ini dapat dibawa ke ekstrem dengan mengemas node dengan begitu banyak pod sehingga menyebabkan kesalahan atau menjenuhkan node. Memantau saturasi node adalah kunci untuk berhasil menggunakan ukuran node yang lebih besar.
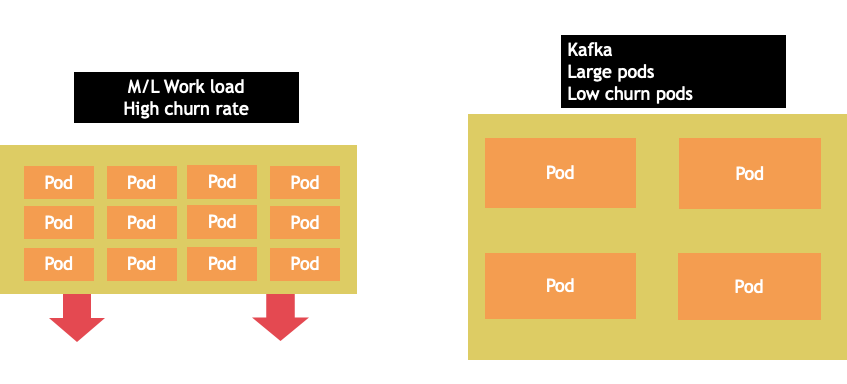
Pemilihan simpul jarang merupakan one-size-fits-all proposisi. Seringkali yang terbaik adalah membagi beban kerja dengan churn rate yang berbeda secara dramatis ke dalam grup node yang berbeda. Beban kerja batch kecil dengan churn rate tinggi akan paling baik dilayani oleh keluarga instance 4xlarge, sedangkan aplikasi skala besar seperti Kafka yang membutuhkan 8 vCPU dan memiliki churn rate rendah akan lebih baik dilayani oleh keluarga 12xlarge.
catatan
Faktor lain yang perlu dipertimbangkan dengan ukuran node yang sangat besar adalah karena CGROUPS tidak menyembunyikan jumlah total vCPU dari aplikasi container. Runtime dinamis seringkali dapat memunculkan sejumlah utas OS yang tidak disengaja, menciptakan latensi yang sulit dipecahkan. Untuk aplikasi ini CPU pinning
Node Bin-packing
Aturan Kubernetes vs Linux
Ada dua set aturan yang perlu kita perhatikan ketika berhadapan dengan beban kerja di Kubernetes. Aturan Kubernetes Scheduler, yang menggunakan nilai permintaan untuk menjadwalkan pod pada sebuah node, dan kemudian apa yang terjadi setelah pod dijadwalkan, yang merupakan ranah Linux, bukan Kubernetes.
Setelah penjadwal Kubernetes selesai, seperangkat aturan baru mengambil alih, Linux Completely Fair Scheduler (CFS). Kuncinya adalah Linux CFS tidak memiliki konsep inti. Kami akan membahas mengapa berpikir dalam inti dapat menyebabkan masalah besar dengan mengoptimalkan beban kerja untuk skala.
Berpikir di Cores
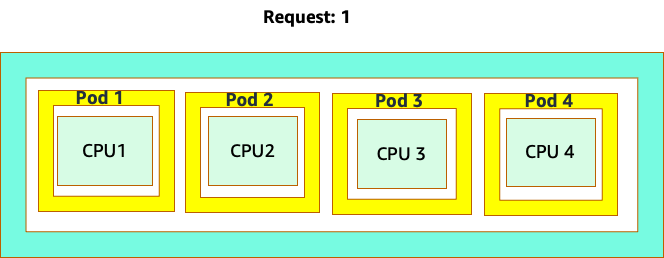
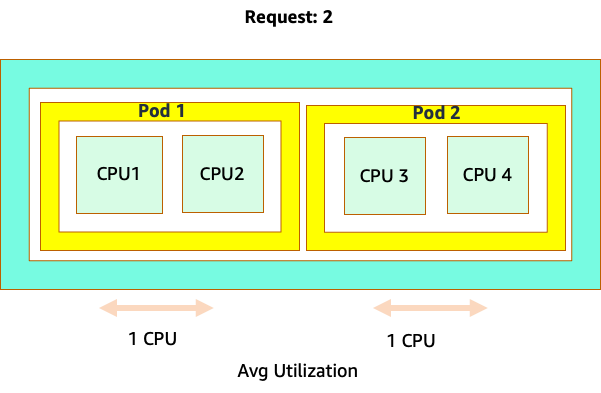
Kebingungan dimulai karena penjadwal Kubernetes memang memiliki konsep inti. Dari perspektif penjadwal Kubernetes jika kita melihat sebuah node dengan 4 pod NGINX, masing-masing dengan permintaan satu set inti, node akan terlihat seperti ini.
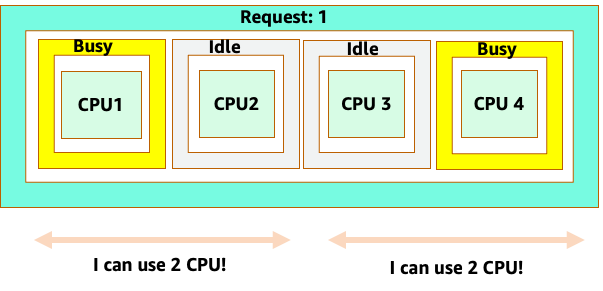
Namun, mari kita lakukan eksperimen pemikiran tentang betapa berbedanya ini terlihat dari perspektif CFS Linux. Hal yang paling penting untuk diingat ketika menggunakan sistem CFS Linux adalah: kontainer sibuk (CGROUPS) adalah satu-satunya wadah yang diperhitungkan dalam sistem berbagi. Dalam hal ini, hanya wadah pertama yang sibuk sehingga diizinkan untuk menggunakan semua 4 core pada node.
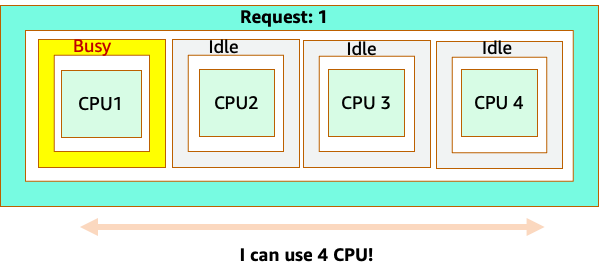
Mengapa ini penting? Katakanlah kami menjalankan pengujian kinerja kami di cluster pengembangan di mana aplikasi NGINX adalah satu-satunya wadah yang sibuk di node itu. Ketika kita memindahkan aplikasi ke produksi, hal berikut akan terjadi: aplikasi NGINX menginginkan 4 vCPU sumber daya, karena semua pod lain di node sibuk, kinerja aplikasi kita dibatasi.
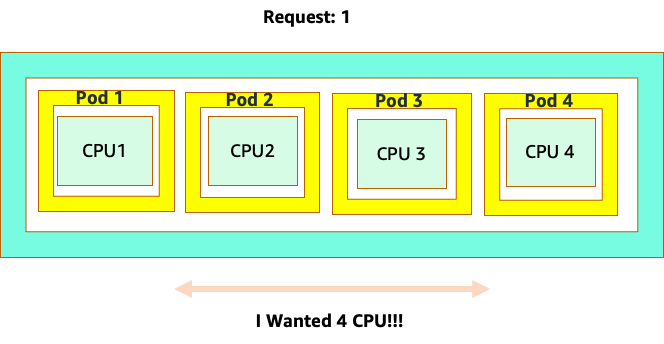
Situasi ini akan membuat kami menambahkan lebih banyak wadah secara tidak perlu karena kami tidak mengizinkan skala aplikasi kami ke “`sweet spot"` mereka. Mari kita jelajahi konsep penting ini "sweet spot" dengan sedikit lebih detail.
Aplikasi ukuran yang tepat
Setiap aplikasi memiliki titik tertentu di mana tidak dapat mengambil lalu lintas lagi. Melangkah di atas titik ini dapat meningkatkan waktu pemrosesan dan bahkan menurunkan lalu lintas ketika didorong jauh melampaui titik ini. Ini dikenal sebagai titik saturasi aplikasi. Untuk menghindari masalah penskalaan, kita harus mencoba menskalakan aplikasi sebelum mencapai titik saturasinya. Mari kita sebut titik ini sweet spot.
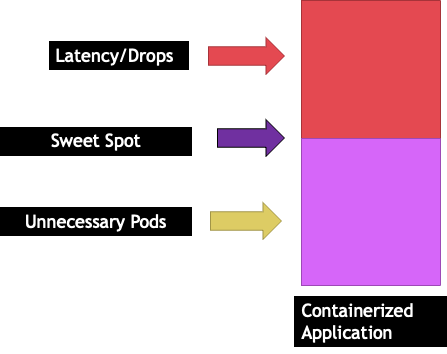
Kita perlu menguji setiap aplikasi kita untuk memahami sweet spotnya. Tidak akan ada panduan universal di sini karena setiap aplikasi berbeda. Selama pengujian ini kami mencoba memahami metrik terbaik yang menunjukkan titik saturasi aplikasi kami. Seringkali, metrik pemanfaatan digunakan untuk menunjukkan aplikasi jenuh tetapi ini dapat dengan cepat menyebabkan masalah penskalaan (Kami akan mengeksplorasi topik ini secara rinci di bagian selanjutnya). Setelah kita memiliki “`sweet spot"` ini, kita dapat menggunakannya untuk meningkatkan skala beban kerja kita secara efisien.
Sebaliknya, apa yang akan terjadi jika kita meningkatkan jauh sebelum sweet spot dan membuat pod yang tidak perlu? Mari kita jelajahi itu di bagian selanjutnya.
Pod terbentang
Untuk melihat bagaimana membuat pod yang tidak perlu dapat dengan cepat lepas kendali, mari kita lihat contoh pertama di sebelah kiri. Skala vertikal yang benar dari wadah ini membutuhkan CPUs pemanfaatan sekitar dua v saat menangani 100 permintaan per detik. Namun, jika kita kurang memberikan nilai permintaan dengan menyetel permintaan ke setengah inti, kita sekarang membutuhkan 4 pod untuk setiap satu pod yang sebenarnya kita butuhkan. Memperburuk masalah ini lebih lanjut, jika HPA
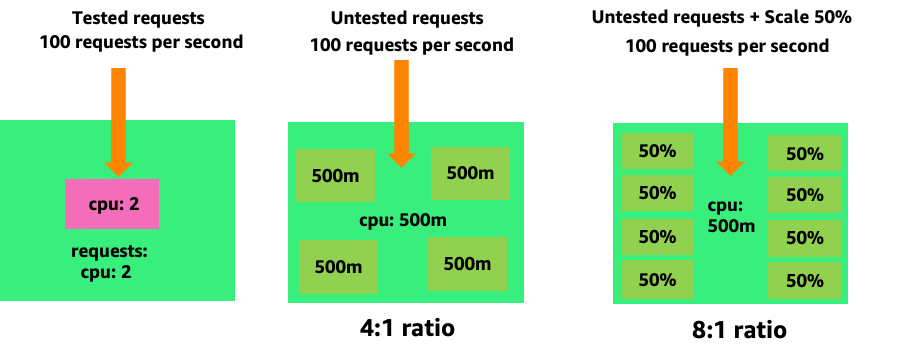
Menskalakan masalah ini, kita dapat dengan cepat melihat bagaimana ini bisa lepas kendali. Penyebaran sepuluh pod yang sweet spotnya disetel secara tidak benar dapat dengan cepat berputar ke 80 pod dan infrastruktur tambahan yang diperlukan untuk menjalankannya.
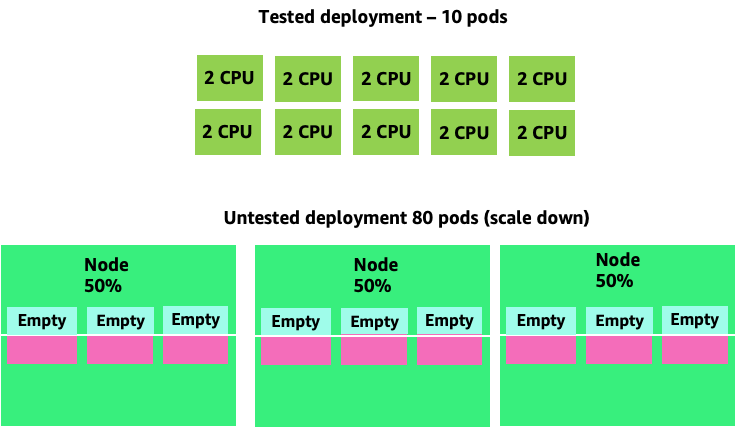
Sekarang setelah kita memahami dampak dari tidak mengizinkan aplikasi beroperasi di sweet spot mereka, mari kita kembali ke level node dan bertanya mengapa perbedaan antara penjadwal Kubernetes dan Linux CFS ini begitu penting?
Saat menskalakan naik dan turun dengan HPA, kita dapat memiliki skenario di mana kita memiliki banyak ruang untuk mengalokasikan lebih banyak pod. Ini akan menjadi keputusan yang buruk karena node yang digambarkan di sebelah kiri sudah pada pemanfaatan CPU 100%. Dalam skenario yang tidak realistis tetapi secara teoritis mungkin, kita dapat memiliki ekstrem lain di mana node kita sepenuhnya penuh, namun pemanfaatan CPU kita nol.
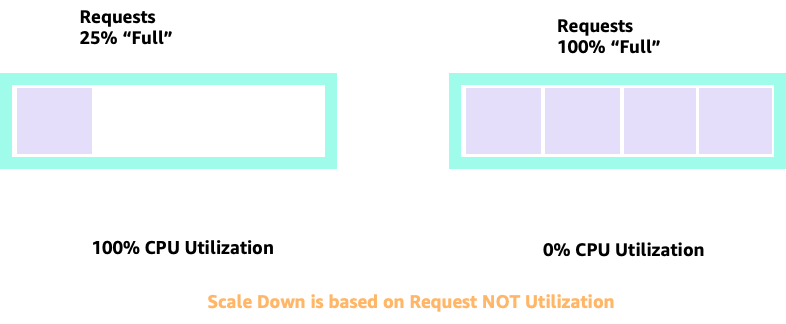
Pengaturan Permintaan
Akan tergoda untuk menetapkan permintaan pada nilai “sweet spot” untuk aplikasi itu, namun ini akan menyebabkan inefisiensi seperti yang digambarkan dalam diagram di bawah ini. Di sini kita telah menetapkan nilai permintaan ke 2 vCPU, namun rata-rata pemanfaatan pod ini hanya berjalan 1 CPU sebagian besar waktu. Pengaturan ini akan menyebabkan kami membuang 50% siklus CPU kami, yang tidak dapat diterima.
Ini membawa kita ke jawaban kompleks untuk masalah. Pemanfaatan kontainer tidak dapat dipikirkan dalam ruang hampa; seseorang harus memperhitungkan aplikasi lain yang berjalan pada node. Dalam contoh berikut, wadah yang bersifat bursty dicampur dengan dua wadah pemanfaatan CPU rendah yang mungkin dibatasi memori. Dengan cara ini kami mengizinkan kontainer untuk mencapai sweet spot mereka tanpa membebani node.
Konsep penting yang harus diambil dari semua ini adalah bahwa menggunakan konsep penjadwal inti Kubernetes untuk memahami kinerja container Linux dapat menyebabkan pengambilan keputusan yang buruk karena tidak terkait.
catatan
Linux CFS memiliki poin kuatnya. Ini terutama berlaku untuk beban kerja I/O berbasis. Namun, jika aplikasi Anda menggunakan inti penuh tanpa sespan, dan tidak memiliki I/O persyaratan, penyematan CPU dapat menghilangkan banyak kerumitan dari proses ini dan didorong dengan peringatan tersebut.
Pemanfaatan vs Saturasi
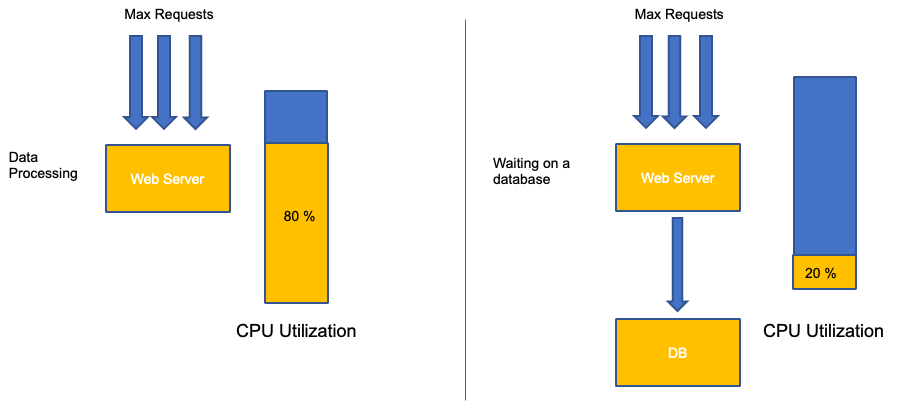
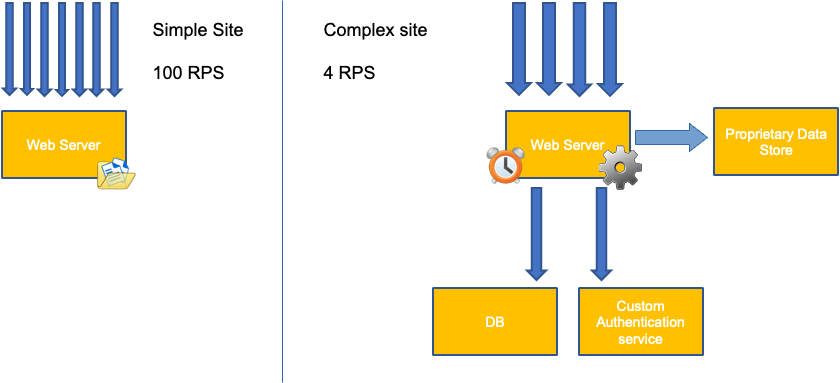
Kesalahan umum dalam penskalaan aplikasi hanya menggunakan pemanfaatan CPU untuk metrik penskalaan Anda. Dalam aplikasi yang kompleks, ini hampir selalu merupakan indikator yang buruk bahwa aplikasi sebenarnya jenuh dengan permintaan. Dalam contoh di sebelah kiri, kita melihat semua permintaan kita benar-benar mengenai server web, sehingga pemanfaatan CPU melacak dengan baik dengan saturasi.
Dalam aplikasi dunia nyata, kemungkinan beberapa permintaan tersebut akan dilayani oleh lapisan database atau lapisan otentikasi, dll. Dalam kasus yang lebih umum ini, perhatikan CPU tidak melacak dengan saturasi karena permintaan sedang dilayani oleh entitas lain. Dalam hal ini CPU adalah indikator saturasi yang sangat buruk.
Menggunakan metrik yang salah dalam kinerja aplikasi adalah alasan nomor satu untuk penskalaan yang tidak perlu dan tidak dapat diprediksi di Kubernetes. Perhatian besar harus diambil dalam memilih metrik saturasi yang tepat untuk jenis aplikasi yang Anda gunakan. Penting untuk dicatat bahwa tidak ada satu ukuran cocok untuk semua rekomendasi yang dapat diberikan. Bergantung pada bahasa yang digunakan dan jenis aplikasi yang dimaksud, ada beragam metrik untuk saturasi.
Kita mungkin berpikir masalah ini hanya dengan Pemanfaatan CPU, namun metrik umum lainnya seperti permintaan per detik juga dapat jatuh ke dalam masalah yang sama persis seperti yang dibahas di atas. Perhatikan permintaan juga dapat pergi ke lapisan DB, lapisan autentikasi, tidak langsung dilayani oleh server web kami, sehingga metrik yang buruk untuk saturasi sebenarnya dari server web itu sendiri.
Sayangnya tidak ada jawaban yang mudah dalam memilih metrik saturasi yang tepat. Berikut adalah beberapa pedoman yang perlu dipertimbangkan:
-
Pahami runtime bahasa Anda - bahasa dengan beberapa utas OS akan bereaksi berbeda dari aplikasi berulir tunggal, sehingga memengaruhi node secara berbeda.
-
Pahami skala vertikal yang benar - berapa banyak buffer yang Anda inginkan dalam skala vertikal aplikasi Anda sebelum menskalakan pod baru?
-
Metrik apa yang benar-benar mencerminkan saturasi aplikasi Anda - Metrik saturasi untuk Produser Kafka akan sangat berbeda dari aplikasi web yang kompleks.
-
Bagaimana semua aplikasi lain pada node saling mempengaruhi - Kinerja aplikasi tidak dilakukan dalam ruang hampa beban kerja lain pada node memiliki dampak besar.
Untuk menutup bagian ini, akan mudah untuk mengabaikan hal di atas sebagai terlalu rumit dan tidak perlu. Seringkali kita mengalami masalah tetapi kita tidak menyadari sifat sebenarnya dari masalah tersebut karena kita melihat metrik yang salah. Pada bagian selanjutnya kita akan melihat bagaimana itu bisa terjadi.
Saturasi Node
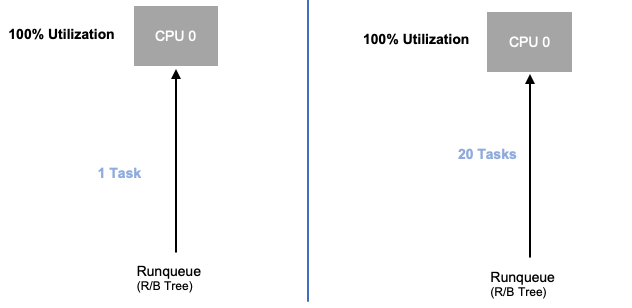
Sekarang kita telah mengeksplorasi saturasi aplikasi, mari kita lihat konsep yang sama ini dari sudut pandang simpul. Mari kita ambil dua CPUs yang 100% digunakan untuk melihat perbedaan antara pemanfaatan vs saturasi.
VCPU di sebelah kiri 100% digunakan, namun tidak ada tugas lain yang menunggu untuk dijalankan pada vCPU ini, jadi dalam arti teoritis murni, ini cukup efisien. Sementara itu, kami memiliki 20 aplikasi ulir tunggal yang menunggu untuk diproses oleh vCPU pada contoh kedua. Semua 20 aplikasi sekarang akan mengalami beberapa jenis latensi saat mereka menunggu giliran untuk diproses oleh vCPU. Dengan kata lain, vCPU di sebelah kanan jenuh.
Kita tidak hanya tidak akan melihat masalah ini jika kita hanya melihat pemanfaatan, tetapi kita mungkin menghubungkan latensi ini dengan sesuatu yang tidak terkait seperti jaringan yang akan membawa kita ke jalan yang salah.
Penting untuk melihat metrik saturasi, bukan hanya metrik pemanfaatan saat meningkatkan jumlah total pod yang berjalan pada sebuah node pada waktu tertentu karena kita dapat dengan mudah melewatkan fakta bahwa kita memiliki node yang terlalu jenuh. Untuk tugas ini kita dapat menggunakan metrik informasi tekanan stall seperti yang terlihat pada grafik di bawah ini.
PromQL - I/O Terhenti
topk(3, ((irate(node_pressure_io_stalled_seconds_total[1m])) * 100))
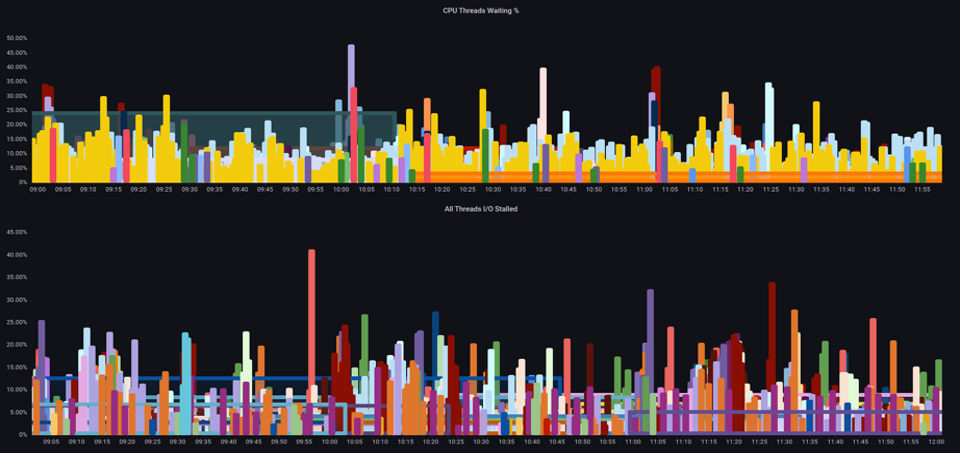
Dengan metrik ini, kami dapat mengetahui apakah utas menunggu di CPU, atau bahkan jika setiap utas di kotak macet menunggu sumber daya seperti memori atau I/O. For example, we could see what percentage every thread on the instance was stalled waiting on I/O selama 1 menit.
topk(3, ((irate(node_pressure_io_stalled_seconds_total[1m])) * 100))
Dengan menggunakan metrik ini, kita dapat melihat pada bagan di atas setiap utas pada kotak terhenti 45% dari waktu menunggu I/O pada tanda air tinggi, yang berarti kita membuang semua siklus CPU pada menit itu. Memahami bahwa ini terjadi dapat membantu kami merebut kembali sejumlah besar waktu vCPU, sehingga membuat penskalaan lebih efisien.
HPA V2
Disarankan untuk menggunakan versi autoscaling/v2 dari HPA API. Versi lama dari HPA API bisa terjebak dalam penskalaan dalam kasus tepi tertentu. Itu juga terbatas pada pod yang hanya berlipat ganda selama setiap langkah penskalaan, yang menciptakan masalah untuk penerapan kecil yang perlu diskalakan dengan cepat.
AutoScaling/v2 memungkinkan kami lebih banyak fleksibilitas untuk memasukkan beberapa kriteria untuk diskalakan dan memungkinkan kami banyak fleksibilitas saat menggunakan metrik khusus dan eksternal (metrik non K8s).
Sebagai contoh, kita dapat menskalakan pada nilai tertinggi dari tiga nilai (lihat di bawah). Kami menskalakan jika rata-rata pemanfaatan semua pod lebih dari 50%, jika metrik kustom paket per detik dari ingress melebihi rata-rata 1.000, atau objek ingress melebihi 10K permintaan per detik.
catatan
Ini hanya untuk menunjukkan fleksibilitas API auto-scaling, kami merekomendasikan terhadap aturan yang terlalu rumit yang sulit dipecahkan dalam produksi.
apiVersion: autoscaling/v2 kind: HorizontalPodAutoscaler metadata: name: php-apache spec: scaleTargetRef: apiVersion: apps/v1 kind: Deployment name: php-apache minReplicas: 1 maxReplicas: 10 metrics: - type: Resource resource: name: cpu target: type: Utilization averageUtilization: 50 - type: Pods pods: metric: name: packets-per-second target: type: AverageValue averageValue: 1k - type: Object object: metric: name: requests-per-second describedObject: apiVersion: networking.k8s.io/v1 kind: Ingress name: main-route target: type: Value value: 10k
Namun, kami mempelajari bahaya menggunakan metrik tersebut untuk aplikasi web yang kompleks. Dalam hal ini kami akan lebih baik dilayani dengan menggunakan metrik khusus atau eksternal yang secara akurat mencerminkan kejenuhan aplikasi kami vs. pemanfaatan. HPAv2 memungkinkan untuk ini dengan memiliki kemampuan untuk menskalakan sesuai dengan metrik apa pun, namun kami masih perlu menemukan dan mengekspor metrik itu ke Kubernetes untuk digunakan.
Misalnya, kita dapat melihat jumlah antrian thread aktif di Apache. Ini sering membuat profil penskalaan yang “lebih halus” (lebih lanjut tentang istilah itu segera). Jika utas aktif, tidak masalah jika utas itu menunggu di lapisan basis data atau melayani permintaan secara lokal, jika semua utas aplikasi digunakan, itu merupakan indikasi bagus bahwa aplikasi sudah jenuh.
Kita dapat menggunakan kehabisan utas ini sebagai sinyal untuk membuat pod baru dengan kumpulan utas yang tersedia sepenuhnya. Ini juga memberi kita kendali atas seberapa besar buffer yang kita inginkan dalam aplikasi untuk diserap selama masa lalu lintas padat. Misalnya, jika kami memiliki kumpulan utas total 10, penskalaan pada 4 utas yang digunakan vs. 8 utas yang digunakan akan berdampak besar pada buffer yang kami miliki saat menskalakan aplikasi. Pengaturan 4 akan masuk akal untuk aplikasi yang perlu skala cepat di bawah beban berat, di mana pengaturan 8 akan lebih efisien dengan sumber daya kami jika kami memiliki banyak waktu untuk skala karena jumlah permintaan meningkat perlahan vs. tajam dari waktu ke waktu.
Apa yang kita maksud dengan istilah “halus” dalam hal penskalaan? Perhatikan bagan di bawah ini di mana kita menggunakan CPU sebagai metrik. Pod dalam penerapan ini melonjak dalam waktu singkat dari 50 pod, hingga 250 pod hanya untuk segera menurunkan skala lagi. Ini adalah penskalaan yang sangat tidak efisien adalah penyebab utama churn pada cluster.
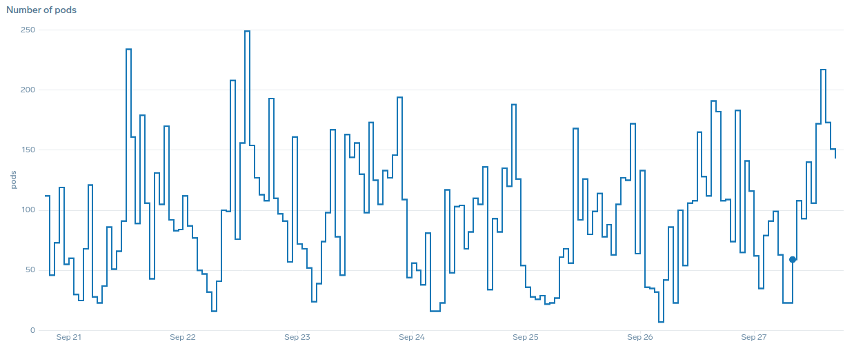
Perhatikan bagaimana setelah kita mengubah ke metrik yang mencerminkan sweet spot yang benar dari aplikasi kita (bagian tengah bagan), kita dapat menskalakan dengan lancar. Penskalaan kami sekarang efisien, dan pod kami diizinkan untuk sepenuhnya menskalakan dengan headroom yang kami sediakan dengan menyesuaikan pengaturan permintaan. Sekarang sekelompok kecil pod melakukan pekerjaan yang dilakukan ratusan pod sebelumnya. Data dunia nyata menunjukkan bahwa ini adalah faktor nomor satu dalam skalabilitas cluster Kubernetes.
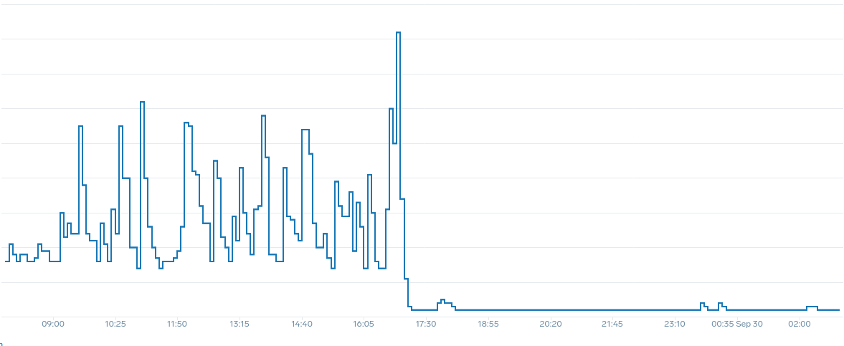
Kesimpulan utamanya adalah pemanfaatan CPU hanya satu dimensi dari kinerja aplikasi dan node. Menggunakan pemanfaatan CPU sebagai indikator kesehatan tunggal untuk node dan aplikasi kami menciptakan masalah dalam penskalaan, kinerja, dan biaya yang semuanya merupakan konsep yang terkait erat. Semakin berkinerja aplikasi dan node, semakin sedikit yang Anda butuhkan untuk menskalakan, yang pada gilirannya menurunkan biaya Anda.
Menemukan dan menggunakan metrik saturasi yang benar untuk menskalakan aplikasi khusus Anda juga memungkinkan Anda untuk memantau dan alarm tentang kemacetan sebenarnya untuk aplikasi itu. Jika langkah kritis ini dilewati, laporan masalah kinerja akan sulit, jika bukan tidak mungkin, untuk dipahami.
Mengatur Batas CPU
Untuk melengkapi bagian ini tentang topik yang disalahpahami, kami akan membahas batas CPU. Singkatnya, batas adalah metadata yang terkait dengan wadah yang memiliki penghitung yang mengatur ulang setiap 100 ms. Ini membantu Linux melacak berapa banyak sumber daya CPU yang digunakan di seluruh node oleh wadah tertentu dalam periode waktu 100 ms.
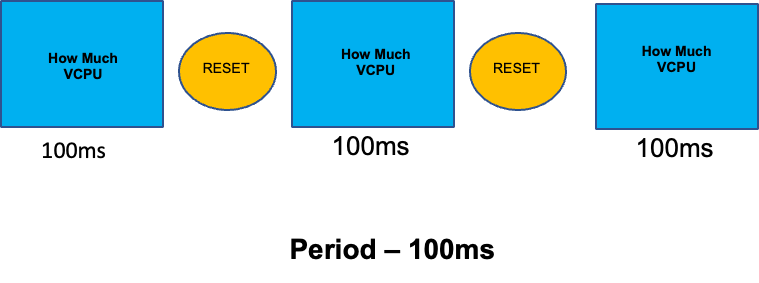
Kesalahan umum dengan menetapkan batas adalah dengan asumsi bahwa aplikasi berulir tunggal dan hanya berjalan pada vCPU “`ditugaskan”. Pada bagian di atas kami mengetahui bahwa CFS tidak menetapkan inti, dan pada kenyataannya wadah yang menjalankan kumpulan utas besar akan menjadwalkan semua vCPU yang tersedia di kotak.
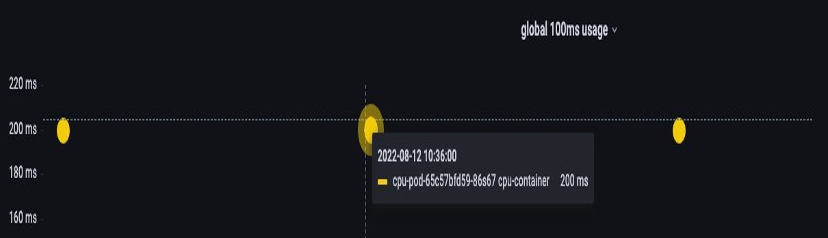
Jika 64 utas OS berjalan di 64 core yang tersedia (dari perspektif node Linux), kami akan membuat tagihan total waktu CPU yang digunakan dalam periode 100ms cukup besar setelah waktu berjalan pada semua 64 core tersebut ditambahkan. Karena ini mungkin hanya terjadi selama proses pengumpulan sampah, sangat mudah untuk melewatkan sesuatu seperti ini. Inilah sebabnya mengapa perlu menggunakan metrik untuk memastikan kami memiliki penggunaan yang benar dari waktu ke waktu sebelum mencoba menetapkan batas.
Untungnya, kami memiliki cara untuk melihat dengan tepat berapa banyak vCPU yang digunakan oleh semua utas dalam suatu aplikasi. Kami akan menggunakan metrik container_cpu_usage_seconds_total untuk tujuan ini.
Karena logika pelambatan terjadi setiap 100ms dan metrik ini adalah metrik per detik, kami akan mempromQL untuk mencocokkan periode 100ms ini. Jika Anda ingin menyelam jauh ke dalam karya pernyataan PromQL ini, silakan lihat blog berikut.
Kueri PromQL:
topk(3, max by (pod, container)(rate(container_cpu_usage_seconds_total{image!="", instance="$instance"}[$__rate_interval]))) / 10

Begitu kita merasa memiliki nilai yang tepat, kita dapat membatasi produksi. Kemudian menjadi perlu untuk melihat apakah aplikasi kita sedang dibatasi karena sesuatu yang tidak terduga. Kita bisa melakukan ini dengan melihat container_cpu_throttled_seconds_total
topk(3, max by (pod, container)(rate(container_cpu_cfs_throttled_seconds_total{image!=``""``, instance=``"$instance"``}[$__rate_interval]))) / 10
Memori
Alokasi memori adalah contoh lain di mana mudah untuk membingungkan perilaku penjadwalan Kubernetes untuk perilaku Linux. CGroup Ini adalah topik yang lebih bernuansa karena ada perubahan besar dalam cara CGroup v2 menangani memori di Linux dan Kubernetes telah mengubah sintaksnya untuk mencerminkan hal ini; baca blog ini untuk detail lebih lanjut.
Tidak seperti permintaan CPU, permintaan memori tidak digunakan setelah proses penjadwalan selesai. Ini karena kita tidak dapat mengompres memori di CGroup v1 dengan cara yang sama dengan CPU. Itu membuat kita hanya memiliki batas memori, yang dirancang untuk bertindak sebagai brankas yang gagal untuk kebocoran memori dengan menghentikan pod sepenuhnya. Ini adalah proposisi gaya semua atau tidak sama sekali, namun kami sekarang telah diberi cara baru untuk mengatasi masalah ini.
Pertama, penting untuk dipahami bahwa pengaturan jumlah memori yang tepat untuk wadah tidaklah mudah seperti yang terlihat. Sistem file di Linux akan menggunakan memori sebagai cache untuk meningkatkan kinerja. Cache ini akan tumbuh seiring waktu, dan mungkin sulit untuk mengetahui berapa banyak memori yang bagus untuk dimiliki untuk cache tetapi dapat direklamasi tanpa dampak signifikan terhadap kinerja aplikasi. Hal ini sering mengakibatkan salah menafsirkan penggunaan memori.
Memiliki kemampuan untuk “mengompres” memori adalah salah satu driver utama di belakang CGroup v2. Untuk sejarah lebih lanjut tentang mengapa CGroup V2 diperlukan, silakan lihat presentasi
Untungnya, Kubernetes sekarang memiliki konsep dan di bawah. memory.min memory.high requests.memory Ini memberi kami opsi untuk melepaskan memori cache ini secara agresif untuk digunakan wadah lain. Setelah wadah mencapai batas tinggi memori, kernel dapat secara agresif merebut kembali memori kontainer itu hingga nilai yang ditetapkan pada. memory.min Dengan demikian memberi kita lebih banyak fleksibilitas ketika sebuah node berada di bawah tekanan memori.
Pertanyaan kuncinya adalah, nilai apa yang memory.min harus ditetapkan? Di sinilah metrik penghentian tekanan memori ikut bermain. Kita dapat menggunakan metrik ini untuk mendeteksi memori “meronta-ronta” pada tingkat kontainer. Kemudian kita dapat menggunakan pengontrol seperti fbtaxmemory.min dengan mencari thrashing memori ini, dan secara dinamis mengatur nilai ke pengaturan ini. memory.min
Ringkasan
Untuk meringkas bagian ini, mudah untuk menggabungkan konsep-konsep berikut:
-
Pemanfaatan dan Saturasi
-
Aturan kinerja Linux dengan logika Penjadwal Kubernetes
Perhatian besar harus diberikan untuk menjaga konsep-konsep ini terpisah. Kinerja dan skala terkait pada tingkat yang dalam. Penskalaan yang tidak perlu menciptakan masalah kinerja, yang pada gilirannya menciptakan masalah penskalaan.
