Terjemahan disediakan oleh mesin penerjemah. Jika konten terjemahan yang diberikan bertentangan dengan versi bahasa Inggris aslinya, utamakan versi bahasa Inggris.
Pesawat Kontrol Kubernetes
Bidang kontrol Kubernetes terdiri dari Kubernetes API Server, Kubernetes Controller Manager, Scheduler dan komponen lain yang diperlukan agar Kubernetes berfungsi. Batas skalabilitas komponen-komponen ini berbeda tergantung pada apa yang Anda jalankan di cluster, tetapi area dengan dampak terbesar terhadap penskalaan termasuk versi Kubernetes, pemanfaatan, dan penskalaan Node individual.
Batasi beban kerja dan ledakan simpul
penting
Untuk menghindari mencapai batas API pada bidang kontrol, Anda harus membatasi lonjakan penskalaan yang meningkatkan ukuran cluster dengan persentase dua digit sekaligus (misalnya 1000 node menjadi 1100 node atau 4000 hingga 4.500 pod sekaligus).
Bidang kontrol EKS akan secara otomatis menskalakan saat cluster Anda tumbuh, tetapi ada batasan seberapa cepat skalanya. Saat pertama kali membuat cluster EKS, Control Plane tidak akan segera dapat menskalakan ke ratusan node atau ribuan pod. Untuk membaca lebih lanjut tentang bagaimana EKS telah melakukan peningkatan penskalaan, lihat posting blog ini
Penskalaan aplikasi besar membutuhkan infrastruktur untuk beradaptasi agar siap sepenuhnya (misalnya penyeimbang beban pemanasan). Untuk mengontrol kecepatan penskalaan, pastikan Anda melakukan penskalaan berdasarkan metrik yang tepat untuk aplikasi Anda. Penskalaan CPU dan memori mungkin tidak secara akurat memprediksi batasan aplikasi Anda dan menggunakan metrik kustom (misalnya permintaan per detik) di Kubernetes Horizontal Pod Autoscaler (HPA) mungkin merupakan opsi penskalaan yang lebih baik.
Untuk menggunakan metrik kustom, lihat contoh di dokumentasi Kubernetes
Skala node dan pod dengan aman
Ganti instance yang berjalan lama
Mengganti node secara teratur membuat cluster Anda tetap sehat dengan menghindari penyimpangan konfigurasi dan masalah yang hanya terjadi setelah waktu aktif yang diperpanjang (misalnya kebocoran memori lambat). Penggantian otomatis akan memberi Anda proses dan praktik yang baik untuk peningkatan node dan patch keamanan. Jika setiap node di cluster Anda diganti secara teratur maka ada lebih sedikit kerja keras yang diperlukan untuk mempertahankan proses terpisah untuk pemeliharaan berkelanjutan.
Gunakan pengaturan waktu untuk hidup (TTL) Karpenter untuk mengganti instance setelah dijalankan untuk jangka waktu tertentu. Grup node yang dikelola sendiri dapat menggunakan max-instance-lifetime pengaturan untuk siklus node secara otomatis. Grup node terkelola saat ini tidak memiliki fitur ini tetapi Anda dapat melacak permintaan di sini GitHub
Hapus node yang kurang dimanfaatkan
Anda dapat menghapus node ketika mereka tidak memiliki beban kerja yang berjalan menggunakan ambang batas bawah skala di Kubernetes Cluster Autoscaler dengan --scale-down-utilization-thresholdttlSecondsAfterEmpty
Gunakan anggaran gangguan pod dan shutdown node aman
Menghapus pod dan node dari klaster Kubernetes membutuhkan pengontrol untuk membuat pembaruan ke beberapa sumber daya (mis.). EndpointSlices Melakukan hal ini sering atau terlalu cepat dapat menyebabkan pelambatan server API dan pemadaman aplikasi saat perubahan menyebar ke pengontrol. Anggaran Gangguan Pod
Gunakan Cloent-Side Cache saat menjalankan Kubectl
Menggunakan perintah kubectl secara tidak efisien dapat menambahkan beban tambahan ke Kubernetes API Server. Anda harus menghindari menjalankan skrip atau otomatisasi yang menggunakan kubectl berulang kali (misalnya dalam loop for) atau menjalankan perintah tanpa cache lokal.
kubectlmemiliki cache sisi klien yang menyimpan informasi penemuan dari cluster untuk mengurangi jumlah panggilan API yang diperlukan. Cache diaktifkan secara default dan disegarkan setiap 10 menit.
Jika Anda menjalankan kubectl dari container atau tanpa cache sisi klien, Anda mungkin mengalami masalah pembatasan API. Disarankan untuk mempertahankan cache cluster Anda dengan memasang file --cache-dir untuk menghindari panggilan API yang tidak biasa.
Nonaktifkan Kompresi kubectl
Menonaktifkan kompresi kubectl di file kubeconfig Anda dapat mengurangi penggunaan API dan CPU klien. Secara default server akan memampatkan data yang dikirim ke klien untuk mengoptimalkan bandwidth jaringan. Ini menambahkan beban CPU pada klien dan server untuk setiap permintaan dan menonaktifkan kompresi dapat mengurangi overhead dan latensi jika Anda memiliki bandwidth yang memadai. Untuk menonaktifkan kompresi, Anda dapat menggunakan --disable-compression=true flag atau set disable-compression: true di file kubeconfig Anda.
apiVersion: v1
clusters:
- cluster:
server: serverURL
disable-compression: true
name: cluster
Shard Cluster Autoscaler
Kubernetes Cluster Autoscaler telah diuji untuk skala hingga 1000 node
ClusterAutoscaler-1
autoscalingGroups: - name: eks-core-node-grp-20220823190924690000000011-80c1660e-030d-476d-cb0d-d04d585a8fcb maxSize: 50 minSize: 2 - name: eks-data_m1-20220824130553925600000011-5ec167fa-ca93-8ca4-53a5-003e1ed8d306 maxSize: 450 minSize: 2 - name: eks-data_m2-20220824130733258600000015-aac167fb-8bf7-429d-d032-e195af4e25f5 maxSize: 450 minSize: 2 - name: eks-data_m3-20220824130553914900000003-18c167fa-ca7f-23c9-0fea-f9edefbda002 maxSize: 450 minSize: 2
ClusterAutoscaler-2
autoscalingGroups: - name: eks-data_m4-2022082413055392550000000f-5ec167fa-ca86-6b83-ae9d-1e07ade3e7c4 maxSize: 450 minSize: 2 - name: eks-data_m5-20220824130744542100000017-02c167fb-a1f7-3d9e-a583-43b4975c050c maxSize: 450 minSize: 2 - name: eks-data_m6-2022082413055392430000000d-9cc167fa-ca94-132a-04ad-e43166cef41f maxSize: 450 minSize: 2 - name: eks-data_m7-20220824130553921000000009-96c167fa-ca91-d767-0427-91c879ddf5af maxSize: 450 minSize: 2
Prioritas dan Keadilan API
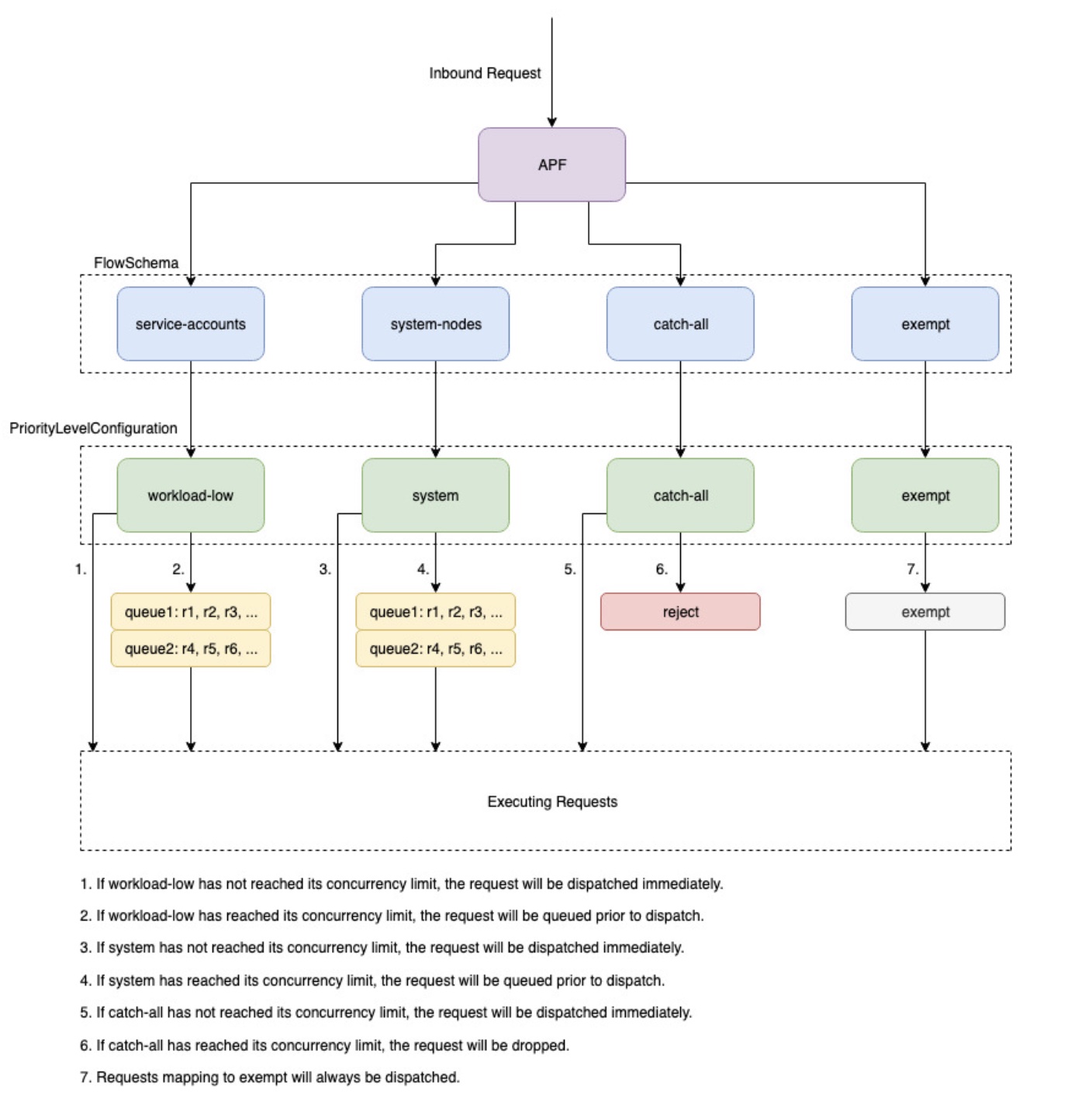
Gambaran Umum
Untuk melindungi diri dari kelebihan beban selama periode permintaan yang meningkat, Server API membatasi jumlah permintaan dalam penerbangan yang dapat ditulisnya pada waktu tertentu. Setelah batas ini terlampaui, Server API akan mulai menolak permintaan dan mengembalikan kode respons HTTP 429 untuk “Terlalu Banyak Permintaan” kembali ke klien. Server menjatuhkan permintaan dan meminta klien mencoba lagi nanti lebih disukai daripada tidak memiliki batas sisi server pada jumlah permintaan dan membebani bidang kontrol secara berlebihan, yang dapat mengakibatkan penurunan kinerja atau tidak tersedianya.
Mekanisme yang digunakan oleh Kubernetes untuk mengonfigurasi bagaimana permintaan dalam penerbangan ini dibagi di antara berbagai jenis permintaan disebut API--max-requests-inflight. --max-mutating-requests-inflight EKS menggunakan nilai default 400 dan 200 permintaan untuk flag ini, memungkinkan total 600 permintaan dikirim pada waktu tertentu. Namun, karena skala bidang kontrol ke ukuran yang lebih besar sebagai respons terhadap peningkatan pemanfaatan dan churn beban kerja, hal itu juga meningkatkan kuota permintaan dalam penerbangan hingga tahun 2000 (dapat berubah). APF menentukan bagaimana kuota permintaan dalam pesawat ini dibagi lagi di antara jenis permintaan yang berbeda. Perhatikan bahwa bidang kontrol EKS sangat tersedia dengan setidaknya 2 Server API yang terdaftar di setiap cluster. Ini berarti jumlah total permintaan dalam pesawat yang dapat ditangani klaster Anda adalah dua kali (atau lebih tinggi jika diperkecil secara horizontal lebih lanjut) kuota dalam pesawat yang ditetapkan per kube-apiserver. Jumlah ini mencapai beberapa ribu requests/second pada cluster EKS terbesar.
Dua jenis objek Kubernetes, dipanggil PriorityLevelConfigurations dan FlowSchemas, mengkonfigurasi bagaimana jumlah total permintaan dibagi antara jenis permintaan yang berbeda. Objek-objek ini dikelola oleh API Server secara otomatis dan EKS menggunakan konfigurasi default dari objek-objek ini untuk versi minor Kubernetes yang diberikan. PriorityLevelConfigurations mewakili sebagian kecil dari jumlah total permintaan yang diizinkan. Misalnya, beban kerja tinggi PriorityLevelConfiguration dialokasikan 98 dari total 600 permintaan. Jumlah permintaan yang dialokasikan untuk semua PriorityLevelConfigurations akan sama dengan 600 (atau sedikit di atas 600 karena Server API akan membulatkan jika level tertentu diberikan sebagian kecil dari permintaan). Untuk memeriksa PriorityLevelConfigurations di cluster Anda dan jumlah permintaan yang dialokasikan untuk masing-masing, Anda dapat menjalankan perintah berikut. Ini adalah default pada EKS 1.32:
$ kubectl get --raw /metrics | grep apiserver_flowcontrol_nominal_limit_seats apiserver_flowcontrol_nominal_limit_seats{priority_level="catch-all"} 13 apiserver_flowcontrol_nominal_limit_seats{priority_level="exempt"} 0 apiserver_flowcontrol_nominal_limit_seats{priority_level="global-default"} 49 apiserver_flowcontrol_nominal_limit_seats{priority_level="leader-election"} 25 apiserver_flowcontrol_nominal_limit_seats{priority_level="node-high"} 98 apiserver_flowcontrol_nominal_limit_seats{priority_level="system"} 74 apiserver_flowcontrol_nominal_limit_seats{priority_level="workload-high"} 98 apiserver_flowcontrol_nominal_limit_seats{priority_level="workload-low"} 245
Jenis objek kedua adalah FlowSchemas. Permintaan API Server dengan sekumpulan properti tertentu diklasifikasikan di bawah yang sama FlowSchema. Properti ini mencakup pengguna yang diautentikasi atau atribut permintaan, seperti grup API, namespace, atau sumber daya. A FlowSchema juga menentukan PriorityLevelConfiguration jenis permintaan yang harus dipetakan. Kedua objek bersama-sama berkata, “Saya ingin jenis permintaan ini dihitung terhadap bagian permintaan dalam penerbangan ini.” Ketika permintaan mengenai Server API, ia akan memeriksa masing-masing FlowSchemas hingga menemukan satu yang cocok dengan semua properti yang diperlukan. Jika beberapa FlowSchemas cocok dengan permintaan, Server API akan memilih FlowSchema dengan prioritas pencocokan terkecil yang ditentukan sebagai properti dalam objek.
Pemetaan FlowSchemas to PriorityLevelConfigurations dapat dilihat menggunakan perintah ini:
$ kubectl get flowschemas NAME PRIORITYLEVEL MATCHINGPRECEDENCE DISTINGUISHERMETHOD AGE MISSINGPL exempt exempt 1 <none> 7h19m False eks-exempt exempt 2 <none> 7h19m False probes exempt 2 <none> 7h19m False system-leader-election leader-election 100 ByUser 7h19m False endpoint-controller workload-high 150 ByUser 7h19m False workload-leader-election leader-election 200 ByUser 7h19m False system-node-high node-high 400 ByUser 7h19m False system-nodes system 500 ByUser 7h19m False kube-controller-manager workload-high 800 ByNamespace 7h19m False kube-scheduler workload-high 800 ByNamespace 7h19m False kube-system-service-accounts workload-high 900 ByNamespace 7h19m False eks-workload-high workload-high 1000 ByUser 7h14m False service-accounts workload-low 9000 ByUser 7h19m False global-default global-default 9900 ByUser 7h19m False catch-all catch-all 10000 ByUser 7h19m False
PriorityLevelConfigurations dapat memiliki jenis Antrian, Tolak, atau Dikecualikan. Untuk tipe Antrian dan Tolak, batas diberlakukan pada jumlah maksimum permintaan dalam penerbangan untuk tingkat prioritas tersebut, namun, perilaku berbeda ketika batas tersebut tercapai. Misalnya, workload-high PriorityLevelConfiguration menggunakan tipe Queue dan memiliki 98 permintaan yang tersedia untuk digunakan oleh controller-manager, endpoint-controller, scheduler, eks related controllers dan from pods yang berjalan di namespace kube-system. Karena tipe Antrian digunakan, Server API akan berusaha menyimpan permintaan di memori dan berharap jumlah permintaan dalam penerbangan turun di bawah 98 sebelum waktu permintaan ini habis. Jika waktu permintaan yang diberikan habis dalam antrian atau jika terlalu banyak permintaan sudah antri, Server API tidak punya pilihan selain membatalkan permintaan dan mengembalikan klien 429. Perhatikan bahwa antrian dapat mencegah permintaan menerima 429, tetapi disertai dengan tradeoff peningkatan end-to-end latensi pada permintaan.
Sekarang pertimbangkan catch-all FlowSchema yang memetakan ke catch-all PriorityLevelConfiguration dengan tipe Reject. Jika klien mencapai batas 13 permintaan dalam pesawat, Server API tidak akan melakukan antrian dan akan menghapus permintaan secara instan dengan kode respons 429. Terakhir, pemetaan permintaan ke PriorityLevelConfiguration with type Exempt tidak akan pernah menerima 429 dan selalu dikirim segera. Ini digunakan untuk permintaan prioritas tinggi seperti permintaan healthz atau permintaan yang berasal dari grup system:master.
Memantau APF dan Permintaan yang Dijatuhkan
Untuk mengonfirmasi apakah ada permintaan yang dihapus karena APF, metrik API Server untuk apiserver_flowcontrol_rejected_requests_total dapat dipantau untuk memeriksa dampak dan. FlowSchemas PriorityLevelConfigurations Misalnya, metrik ini menunjukkan bahwa 100 permintaan dari akun layanan FlowSchema dibatalkan karena waktu permintaan habis dalam antrian rendah beban kerja:
% kubectl get --raw /metrics | grep apiserver_flowcontrol_rejected_requests_total
apiserver_flowcontrol_rejected_requests_total{flow_schema="service-accounts",priority_level="workload-low",reason="time-out"} 100
Untuk memeriksa seberapa dekat yang PriorityLevelConfiguration diberikan dengan menerima 429 detik atau mengalami peningkatan latensi karena antrian, Anda dapat membandingkan perbedaan antara batas konkurensi dan konkurensi yang digunakan. Dalam contoh ini, kami memiliki buffer 100 permintaan.
% kubectl get --raw /metrics | grep 'apiserver_flowcontrol_nominal_limit_seats.*workload-low' apiserver_flowcontrol_nominal_limit_seats{priority_level="workload-low"} 245 % kubectl get --raw /metrics | grep 'apiserver_flowcontrol_current_executing_seats.*workload-low' apiserver_flowcontrol_current_executing_seats{flow_schema="service-accounts",priority_level="workload-low"} 145
Untuk memeriksa apakah permintaan tertentu PriorityLevelConfiguration mengalami antrian tetapi belum tentu membatalkan permintaan, metrik untuk apiserver_flowcontrol_current_inqueue_requests dapat direferensikan:
% kubectl get --raw /metrics | grep 'apiserver_flowcontrol_current_inqueue_requests.*workload-low'
apiserver_flowcontrol_current_inqueue_requests{flow_schema="service-accounts",priority_level="workload-low"} 10
Metrik Prometheus berguna lainnya meliputi:
-
apiserver_flowcontrol_dispatched_requests_total
-
apiserver_flowcontrol_request_execution_seconds
-
apiserver_flowcontrol_request_wait_duration_seconds
Lihat dokumentasi upstream untuk daftar lengkap metrik APF
Mencegah Permintaan yang Diturunkan
Cegah 429 detik dengan mengubah beban kerja Anda
Ketika APF membatalkan permintaan karena permintaan yang diberikan PriorityLevelConfiguration melebihi jumlah maksimum permintaan dalam penerbangan yang diizinkan, klien yang terpengaruh FlowSchemas dapat mengurangi jumlah permintaan yang dieksekusi pada waktu tertentu. Hal ini dapat dicapai dengan mengurangi jumlah total permintaan yang dibuat selama periode di mana 429 terjadi. Perhatikan bahwa permintaan yang berjalan lama seperti panggilan daftar mahal sangat bermasalah karena dihitung sebagai permintaan dalam penerbangan untuk seluruh durasi yang mereka jalankan. Mengurangi jumlah permintaan mahal ini atau mengoptimalkan latensi panggilan daftar ini (misalnya, dengan mengurangi jumlah objek yang diambil per permintaan atau beralih menggunakan permintaan jam tangan) dapat membantu mengurangi total konkurensi yang diperlukan oleh beban kerja yang diberikan.
Cegah 429 detik dengan mengubah pengaturan APF
Awas
Hanya ubah pengaturan APF default jika Anda tahu apa yang Anda lakukan. Setelan APF yang salah konfigurasi dapat mengakibatkan permintaan Server API yang terputus dan gangguan beban kerja yang signifikan.
Salah satu pendekatan lain untuk mencegah permintaan yang dijatuhkan adalah mengubah default FlowSchemas atau PriorityLevelConfigurations diinstal pada kluster EKS. EKS menginstal pengaturan default upstream untuk FlowSchemas dan PriorityLevelConfigurations untuk versi minor Kubernetes yang diberikan. Server API akan secara otomatis merekonsiliasi objek ini kembali ke defaultnya jika diubah kecuali anotasi berikut pada objek disetel ke false:
metadata:
annotations:
apf.kubernetes.io/autoupdate-spec: "false"
Pada tingkat tinggi, pengaturan APF dapat dimodifikasi menjadi:
-
Alokasikan lebih banyak kapasitas dalam penerbangan untuk permintaan yang Anda pedulikan.
-
Mengisolasi permintaan yang tidak penting atau mahal yang dapat membuat kapasitas kelaparan untuk jenis permintaan lainnya.
Ini dapat dicapai dengan mengubah default FlowSchemas dan PriorityLevelConfigurations atau dengan membuat objek baru dari jenis ini. Operator dapat meningkatkan nilai assuredConcurrencyShares untuk PriorityLevelConfigurations objek yang relevan untuk meningkatkan fraksi permintaan dalam penerbangan yang dialokasikan. Selain itu, jumlah permintaan yang dapat diantrian pada waktu tertentu juga dapat ditingkatkan jika aplikasi dapat menangani latensi tambahan yang disebabkan oleh permintaan yang diantrian sebelum dikirim.
Atau, baru FlowSchema dan PriorityLevelConfigurations objek dapat dibuat yang khusus untuk beban kerja pelanggan. Ketahuilah bahwa mengalokasikan lebih banyak assuredConcurrencyShares ke yang sudah ada PriorityLevelConfigurations atau yang baru PriorityLevelConfigurations akan menyebabkan jumlah permintaan yang dapat ditangani oleh bucket lain berkurang karena batas keseluruhan akan tetap menjadi 600 dalam pesawat per Server API.
Saat membuat perubahan pada default APF, metrik ini harus dipantau pada klaster non-produksi untuk memastikan perubahan pengaturan tidak menyebabkan 429 detik yang tidak diinginkan:
-
Metrik untuk
apiserver_flowcontrol_rejected_requests_totalharus dipantau untuk semua FlowSchemas untuk memastikan bahwa tidak ada bucket yang mulai menjatuhkan permintaan. -
Nilai untuk
apiserver_flowcontrol_nominal_limit_seatsdanapiserver_flowcontrol_current_executing_seatsharus dibandingkan untuk memastikan bahwa konkurensi yang digunakan tidak berisiko melanggar batas untuk tingkat prioritas tersebut.
Salah satu kasus penggunaan umum untuk mendefinisikan yang baru FlowSchema dan PriorityLevelConfiguration untuk isolasi. Misalkan kita ingin mengisolasi panggilan event list yang sudah berjalan lama dari pod ke bagian permintaannya sendiri. Ini akan mencegah permintaan penting dari pod yang menggunakan akun layanan yang FlowSchema ada menerima 429 detik dan kekurangan kapasitas permintaan. Ingat bahwa jumlah total permintaan dalam pesawat terbatas, namun, contoh ini menunjukkan pengaturan APF dapat dimodifikasi untuk membagi kapasitas permintaan untuk beban kerja yang diberikan dengan lebih baik:
Contoh FlowSchema objek untuk mengisolasi daftar permintaan acara:
apiVersion: flowcontrol.apiserver.k8s.io/v1
kind: FlowSchema
metadata:
name: list-events-default-service-accounts
spec:
distinguisherMethod:
type: ByUser
matchingPrecedence: 8000
priorityLevelConfiguration:
name: catch-all
rules:
- resourceRules:
- apiGroups:
- '*'
namespaces:
- default
resources:
- events
verbs:
- list
subjects:
- kind: ServiceAccount
serviceAccount:
name: default
namespace: default
-
Ini FlowSchema menangkap semua panggilan acara daftar yang dibuat oleh akun layanan di namespace default.
-
Prioritas pencocokan 8000 lebih rendah dari nilai 9000 yang digunakan oleh akun layanan yang ada FlowSchema sehingga panggilan acara daftar ini akan cocok dengan -akun daripada akun layanan. list-events-default-service
-
Kami menggunakan catch-all PriorityLevelConfiguration untuk mengisolasi permintaan ini. Bucket ini hanya mengizinkan 13 permintaan dalam pesawat untuk digunakan oleh panggilan acara daftar yang sudah berjalan lama ini. Pod akan mulai menerima 429 detik segera setelah mereka mencoba mengeluarkan lebih dari 13 permintaan ini secara bersamaan.
Mengambil sumber daya di server API
Mendapatkan informasi dari server API adalah perilaku yang diharapkan untuk cluster dalam berbagai ukuran. Saat Anda menskalakan jumlah sumber daya di cluster, frekuensi permintaan dan volume data dapat dengan cepat menjadi hambatan bagi bidang kontrol dan akan menyebabkan latensi dan kelambatan API. Tergantung pada tingkat keparahan latensi itu menyebabkan downtime yang tidak terduga jika Anda tidak berhati-hati.
Menyadari apa yang Anda minta dan seberapa sering langkah pertama untuk menghindari jenis masalah ini. Berikut adalah panduan untuk membatasi volume kueri berdasarkan praktik terbaik penskalaan. Saran di bagian ini disediakan agar dimulai dengan opsi yang diketahui memiliki skala terbaik.
Gunakan Informan Bersama
Saat membangun pengontrol dan otomatisasi yang terintegrasi dengan API Kubernetes, Anda sering perlu mendapatkan informasi dari sumber daya Kubernetes. Jika Anda melakukan polling untuk sumber daya ini secara teratur, hal itu dapat menyebabkan beban yang signifikan pada server API.
Menggunakan informan
Pengontrol harus menghindari polling sumber daya kluster yang luas tanpa label dan pemilih bidang terutama dalam kelompok besar. Setiap polling yang tidak difilter membutuhkan banyak data yang tidak perlu untuk dikirim dari etcd melalui server API untuk difilter oleh klien. Dengan memfilter berdasarkan label dan ruang nama, Anda dapat mengurangi jumlah pekerjaan yang perlu dilakukan server API untuk memenuhi permintaan dan data yang dikirim ke klien.
Optimalkan penggunaan API Kubernetes
Saat memanggil Kubernetes API dengan pengontrol atau otomatisasi kustom, penting bagi Anda untuk membatasi panggilan hanya pada sumber daya yang Anda butuhkan. Tanpa batas, Anda dapat menyebabkan pemuatan yang tidak dibutuhkan pada server API dan etcd.
Disarankan agar Anda menggunakan argumen arloji bila memungkinkan. Tanpa argumen, perilaku default adalah mencantumkan objek. Untuk menggunakan watch alih-alih list, Anda dapat menambahkan ?watch=true ke akhir permintaan API Anda. Misalnya, untuk mendapatkan semua pod di namespace default dengan menggunakan jam tangan:
/api/v1/namespaces/default/pods?watch=true
Jika Anda mencantumkan objek, Anda harus membatasi ruang lingkup dari apa yang Anda cantumkan dan jumlah data yang dikembalikan. Anda dapat membatasi data yang dikembalikan dengan menambahkan limit=500 argumen ke permintaan. fieldSelectorArgumen dan /namespace/ jalur dapat berguna untuk memastikan daftar Anda memiliki cakupan yang sempit sesuai kebutuhan. Misalnya, untuk mencantumkan hanya pod yang sedang berjalan di namespace default, gunakan jalur dan argumen API berikut.
/api/v1/namespaces/default/pods?fieldSelector=status.phase=Running&limit=500
Atau daftar semua pod yang berjalan dengan:
/api/v1/pods?fieldSelector=status.phase=Running&limit=500
Opsi lain untuk membatasi panggilan jam tangan atau objek terdaftar adalah dengan menggunakan resourceVersionsyang dapat Anda baca di dokumentasi KubernetesresourceVersion argumen, Anda akan menerima versi terbaru yang tersedia yang memerlukan pembacaan kuorum etcd yang merupakan bacaan paling mahal dan paling lambat untuk database. ResourceVersion bergantung pada sumber daya apa yang Anda coba kueri dan dapat ditemukan di lapangan. metadata.resourseVersion Ini juga disarankan jika menggunakan panggilan jam tangan dan bukan hanya daftar panggilan
Ada khusus yang resourceVersion=0 tersedia yang akan mengembalikan hasil dari cache server API. Ini dapat mengurangi beban etcd tetapi tidak mendukung pagination.
/api/v1/namespaces/default/pods?resourceVersion=0
Disarankan untuk menggunakan jam tangan dengan set ResourceVersion untuk menjadi nilai terbaru yang diketahui yang diterima dari daftar atau jam tangan sebelumnya. Ini ditangani secara otomatis di client-go. Tetapi disarankan untuk memeriksanya kembali jika Anda menggunakan klien k8s dalam bahasa lain.
/api/v1/namespaces/default/pods?watch=true&resourceVersion=362812295
Jika Anda memanggil API tanpa argumen apa pun, itu akan menjadi sumber daya yang paling intensif untuk server API dan etcd. Panggilan ini akan mendapatkan semua pod di semua ruang nama tanpa pagination atau membatasi cakupan dan memerlukan kuorum yang dibaca dari etcd.
/api/v1/pods
Mencegah ternak yang DaemonSet bergemuruh
A DaemonSet memastikan bahwa semua (atau beberapa) node menjalankan salinan pod. Saat node bergabung dengan cluster, daemonset-controller membuat pod untuk node tersebut. Saat node meninggalkan cluster, pod tersebut adalah sampah yang dikumpulkan. Menghapus a DaemonSet akan membersihkan pod yang dibuatnya.
Beberapa kegunaan khas a DaemonSet adalah:
-
Menjalankan daemon penyimpanan cluster di setiap node
-
Menjalankan daemon koleksi log di setiap node
-
Menjalankan daemon pemantauan node di setiap node
Pada cluster dengan ribuan node, membuat yang baru DaemonSet, memperbarui DaemonSet, atau meningkatkan jumlah node dapat menghasilkan beban tinggi yang ditempatkan pada bidang kontrol. Jika DaemonSet pod mengeluarkan permintaan server API yang mahal saat memulai pod, mereka dapat menyebabkan penggunaan sumber daya yang tinggi pada bidang kontrol dari sejumlah besar permintaan bersamaan.
Dalam operasi normal, Anda dapat menggunakan a RollingUpdate untuk memastikan peluncuran pod baru secara bertahap. DaemonSet Dengan strategi RollingUpdate pembaruan, setelah Anda memperbarui DaemonSet template, pengontrol membunuh DaemonSet pod lama dan membuat DaemonSet pod baru secara otomatis dengan cara yang terkontrol. Paling banyak satu pod DaemonSet akan berjalan di setiap node selama seluruh proses pembaruan. Anda dapat melakukan peluncuran bertahap dengan mengatur maxUnavailable ke 1, maxSurge ke 0, dan minReadySeconds 60. Jika Anda tidak menentukan strategi pembaruan, Kubernetes akan default membuat a RollingUpdate dengan maxUnavailable sebagai 1, sebagai 0, dan maxSurge minReadySeconds sebagai 0.
minReadySeconds: 60
strategy:
type: RollingUpdate
rollingUpdate:
maxSurge: 0
maxUnavailable: 1
A RollingUpdate memastikan peluncuran DaemonSet Pod baru secara bertahap jika pod DaemonSet sudah dibuat dan memiliki jumlah Ready Pod yang diharapkan di semua node. Masalah kawanan yang bergemuruh dapat terjadi dalam kondisi tertentu yang tidak tercakup oleh strategi. RollingUpdate
Cegah ternak yang bergemuruh saat penciptaan DaemonSet
Secara default, terlepas dari RollingUpdate konfigurasinya, daemonset-controller di dalamnya kube-controller-manager akan membuat pod untuk semua node yang cocok secara bersamaan saat Anda membuat yang baru. DaemonSet Untuk memaksa peluncuran pod secara bertahap setelah Anda membuat DaemonSet, Anda dapat menggunakan salah satu atau. NodeSelector NodeAffinity Ini akan membuat sebuah DaemonSet yang cocok dengan nol node dan kemudian Anda dapat secara bertahap memperbarui node untuk membuatnya memenuhi syarat untuk menjalankan pod dari DaemonSet pada tingkat yang terkontrol. Anda dapat mengikuti pendekatan ini:
-
Tambahkan label ke semua node untuk
run-daemonset=false.
kubectl label nodes --all run-daemonset=false
-
Buat Anda DaemonSet dengan
NodeAffinitypengaturan untuk mencocokkan node apa pun tanparun-daemonset=falselabel. Awalnya, ini akan mengakibatkan Anda tidak DaemonSet memiliki pod yang sesuai.
affinity:
nodeAffinity:
requiredDuringSchedulingIgnoredDuringExecution:
nodeSelectorTerms:
- matchExpressions:
- key: run-daemonset
operator: NotIn
values:
- "false"
-
Hapus
run-daemonset=falselabel dari node Anda pada tingkat yang terkontrol. Anda dapat menggunakan skrip bash ini sebagai contoh:
#!/bin/bash
nodes=$(kubectl get --raw "/api/v1/nodes" | jq -r '.items | .[].metadata.name')
for node in ${nodes[@]}; do
echo "Removing run-daemonset label from node $node"
kubectl label nodes $node run-daemonset-
sleep 5
done
-
Secara opsional, hapus
NodeAffinitypengaturan dari DaemonSet objek Anda. Perhatikan bahwa ini juga akan memicuRollingUpdatedan secara bertahap mengganti semua DaemonSet pod yang ada karena DaemonSet template berubah.
Mencegah kawanan gemuruh pada skala node
Sama halnya dengan DaemonSet pembuatan, membuat node baru dengan kecepatan cepat dapat menghasilkan sejumlah besar DaemonSet pod yang dimulai secara bersamaan. Anda harus membuat node baru pada tingkat yang terkontrol sehingga controller membuat DaemonSet pod pada tingkat yang sama. Jika ini tidak memungkinkan, Anda dapat membuat node baru awalnya tidak memenuhi syarat untuk yang ada DaemonSet dengan menggunakanNodeAffinity. Selanjutnya, Anda dapat menambahkan label ke node baru secara bertahap sehingga daemonset-controller membuat pod pada tingkat yang terkontrol. Anda dapat mengikuti pendekatan ini:
-
Tambahkan label ke semua node yang ada untuk
run-daemonset=true
kubectl label nodes --all run-daemonset=true
-
Perbarui Anda DaemonSet dengan
NodeAffinitypengaturan untuk mencocokkan node apa pun denganrun-daemonset=truelabel. Perhatikan bahwa ini juga akan memicuRollingUpdatedan secara bertahap mengganti semua DaemonSet pod yang ada karena DaemonSet template berubah. Anda harus menungguRollingUpdatesampai selesai sebelum maju ke langkah berikutnya.
affinity:
nodeAffinity:
requiredDuringSchedulingIgnoredDuringExecution:
nodeSelectorTerms:
- matchExpressions:
- key: run-daemonset
operator: In
values:
- "true"
-
Buat node baru di cluster Anda. Perhatikan bahwa node ini tidak akan memiliki
run-daemonset=truelabel sehingga tidak DaemonSet akan cocok dengan node tersebut. -
Tambahkan
run-daemonset=truelabel ke node baru Anda (yang saat ini tidak memilikirun-daemonsetlabel) pada tingkat yang terkontrol. Anda dapat menggunakan skrip bash ini sebagai contoh:
#!/bin/bash
nodes=$(kubectl get --raw "/api/v1/nodes?labelSelector=%21run-daemonset" | jq -r '.items | .[].metadata.name')
for node in ${nodes[@]}; do
echo "Adding run-daemonset=true label to node $node"
kubectl label nodes $node run-daemonset=true
sleep 5
done
-
Secara opsional, hapus
NodeAffinitypengaturan dari DaemonSet objek Anda dan hapusrun-daemonsetlabel dari semua node.
Cegah kawanan gemuruh pada pembaruan DaemonSet
RollingUpdateKebijakan hanya akan menghormati maxUnavailable pengaturan untuk DaemonSet pod yang adaReady. Jika A hanya DaemonSet memiliki NotReady pod atau sebagian besar NotReady pod dan Anda memperbarui templatnya, daemonset-controller akan membuat pod baru secara bersamaan untuk setiap pod. NotReady Hal ini dapat mengakibatkan masalah kawanan yang menggelegar jika ada sejumlah besar NotReady pod, misalnya jika pod terus-menerus crash looping atau gagal menarik gambar.
Untuk memaksa peluncuran pod secara bertahap saat Anda memperbarui DaemonSet dan ada NotReady pod, Anda dapat mengubah sementara strategi pembaruan dari ke DaemonSet . RollingUpdate OnDelete DenganOnDelete, setelah Anda memperbarui DaemonSet template, controller membuat pod baru setelah Anda secara manual menghapus yang lama sehingga Anda dapat mengontrol peluncuran pod baru. Anda dapat mengikuti pendekatan ini:
-
Periksa apakah Anda memiliki
NotReadypod di DaemonSet. -
Jika tidak, Anda dapat memperbarui DaemonSet template dengan aman dan
RollingUpdatestrategi akan memastikan peluncuran bertahap. -
Jika ya, Anda harus memperbarui terlebih dahulu DaemonSet untuk menggunakan
OnDeletestrategi.
updateStrategy: type: OnDelete
-
Selanjutnya, perbarui DaemonSet template Anda dengan perubahan yang diperlukan.
-
Setelah pembaruan ini, Anda dapat menghapus DaemonSet pod lama dengan mengeluarkan permintaan delete pod pada tingkat yang terkontrol. Anda dapat menggunakan skrip bash ini sebagai contoh di mana namanya fluentd-elasticsearch di DaemonSet namespace kube-system:
#!/bin/bash
daemonset_pods=$(kubectl get --raw "/api/v1/namespaces/kube-system/pods?labelSelector=name%3Dfluentd-elasticsearch" | jq -r '.items | .[].metadata.name')
for pod in ${daemonset_pods[@]}; do
echo "Deleting pod $pod"
kubectl delete pod $pod -n kube-system
sleep 5
done
-
Akhirnya, Anda dapat memperbarui DaemonSet kembali ke
RollingUpdatestrategi sebelumnya.
