Terjemahan disediakan oleh mesin penerjemah. Jika konten terjemahan yang diberikan bertentangan dengan versi bahasa Inggris aslinya, utamakan versi bahasa Inggris.
HBase di Amazon S3 (mode penyimpanan Amazon S3)
Saat Anda menjalankan HBase Amazon EMR versi 5.2.0 atau yang lebih baru, Anda dapat mengaktifkan di Amazon HBase S3, yang menawarkan keuntungan sebagai berikut:
Direktori HBase root disimpan di Amazon S3, termasuk file HBase penyimpanan dan metadata tabel. Data ini persisten di luar klaster, tersedia di seluruh Zona EC2 Ketersediaan Amazon, dan Anda tidak perlu memulihkan menggunakan snapshot atau metode lain.
Dengan file penyimpanan di Amazon S3, Anda dapat mengukur klaster Amazon EMR Anda untuk kebutuhan komputasi Anda alih-alih persyaratan data, dengan replikasi 3x di HDFS.
Menggunakan Amazon EMR versi 5.7.0 atau yang lebih baru, Anda dapat mengatur sebuah klaster replika baca, yang memungkinkan Anda untuk mempertahankan salinan data baca-saja di Amazon S3. Anda dapat mengakses data dari klaster replika baca untuk melakukan operasi baca secara bersamaan, dan dalam hal klaster utama menjadi tidak tersedia.
Di Amazon EMR versi 6.2.0 hingga 7.3.0, HFile Pelacakan persisten menggunakan tabel HBase sistem yang dipanggil
hbase:storefileuntuk melacak HFile jalur yang digunakan untuk operasi baca secara langsung. Fitur ini diaktifkan secara default dan tidak memerlukan migrasi manual. Dalam versi yang lebih tinggi dari 7.3.0, HFile jalur dilacak menggunakan pelacak file, menyimpan HFile jalur langsung dalam file meta, di dalam direktori toko.
catatan
Pengguna yang menggunakan versi Amazon EMR sebelum 7.4.0 dan bermigrasi ke EMR-7.4.0 dan yang lebih baru, lihat Migrasi dari HBase versi sebelumnya dan ikuti dokumentasi pemutakhiran yang tersedia untuk memastikan transisi yang lancar.
Ilustrasi berikut menunjukkan HBase komponen yang relevan dengan HBase Amazon S3.

Mengaktifkan HBase di Amazon S3
Anda dapat mengaktifkan HBase di Amazon S3 menggunakan konsol EMR Amazon, API EMR Amazon, AWS CLI atau Amazon EMR. Konfigurasi adalah pilihan selama pembuatan klaster. Saat menggunakan konsol, Anda memilih pengaturan menggunakan Opsi lanjutan. Bila Anda menggunakan AWS CLI, gunakan pilihan --configurations untuk menyediakan objek konfigurasi JSON. Properti objek konfigurasi menentukan mode penyimpanan dan lokasi direktori root di Amazon S3. Lokasi Amazon S3 yang Anda tentukan harus berada di wilayah yang sama dengan klaster Amazon EMR. Hanya satu cluster aktif pada satu waktu yang dapat menggunakan direktori HBase root yang sama di Amazon S3. Untuk langkah-langkah konsol dan contoh create-cluster mendetail menggunakan, lihat. AWS CLIMembuat cluster dengan HBase Objek konfigurasi contoh ditunjukkan dalam potongan JSON berikut.
{ "Classification": "hbase-site", "Properties": { "hbase.rootdir": "s3://amzn-s3-demo-bucket/my-hbase-rootdir"} }, { "Classification": "hbase", "Properties": { "hbase.emr.storageMode":"s3" } }
catatan
Jika Anda menggunakan bucket Amazon S3 sebagai rootdir kegunaannya HBase, Anda harus menambahkan garis miring di akhir URI Amazon S3. Misalnya, Anda harus menggunakan "hbase.rootdir: s3://amzn-s3-demo-bucket/", alih-alih "hbase.rootdir: s3://amzn-s3-demo-bucket", untuk menghindari masalah.
Menggunakan klaster replika baca.
Setelah menyiapkan klaster utama menggunakan HBase Amazon S3, Anda dapat membuat dan mengonfigurasi klaster read-replica yang menyediakan akses hanya-baca ke data yang sama dengan klaster utama. Hal ini berguna ketika Anda membutuhkan akses simultan ke data kueri atau akses terganggu jika klaster utama tidak tersedia. Fitur replika baca tersedia dengan Amazon EMR versi 5.7.0 dan yang lebih baru.
Klaster utama dan klaster replika baca diatur dengan cara yang sama dengan satu perbedaan penting. Kedua titik memiliki lokasi hbase.rootdir yang sama. Namun, klasifikasi hbase untuk klaster replika baca mencakup "hbase.emr.readreplica.enabled":"true" properti.
Cluster read-replica dirancang untuk operasi hanya-baca, dan tidak ada tindakan pemadatan atau penulisan manual yang harus dilakukan di atasnya. Untuk Amazon EMR versi lebih awal dari 7.4.0, disarankan untuk menonaktifkan pemadatan pada klaster baca-replika saat Anda mengaktifkan fitur baca-replika. Tindakan pencegahan ini diperlukan karena, dengan fitur HFile pelacakan persisten diaktifkan pada klaster utama, klaster baca-replika dapat memadatkan tabel sistem, yang berpotensi menyebabkan klaster utama. FileNotFoundException Menonaktifkan pemadatan pada klaster read-replica mencegah inkonsistensi data antara cluster primer dan read-replica.
Misalnya, mengingat klasifikasi JSON untuk cluster primer seperti yang ditunjukkan sebelumnya dalam topik, konfigurasi untuk cluster baca-replika untuk versi EMR lebih awal dari 7.4.0 adalah sebagai berikut:
{ "Classification": "hbase-site", "Properties": { "hbase.rootdir": "s3://amzn-s3-demo-bucket/my-hbase-rootdir", "hbase.regionserver.compaction.enabled": "false" } }, { "Classification": "hbase", "Properties": { "hbase.emr.storageMode":"s3", "hbase.emr.readreplica.enabled":"true" } }
Untuk Amazon EMR versi lebih lambat dari 7.3.0, kami sekarang menggunakan Simpan Pelacakan File fitur ini, oleh karena itu tidak perlu menonaktifkan pemadatan.
Menyinkronkan replika baca ketika Anda menambahkan data
Karena replika baca menggunakan HBase StoreFiles dan metadata yang ditulis klaster utama ke Amazon S3, replika baca hanya sesaat penyimpanan data Amazon S3. Panduan berikut dapat membantu meminimalkan jeda waktu antara klaster utama dan replika baca ketika Anda menulis data.
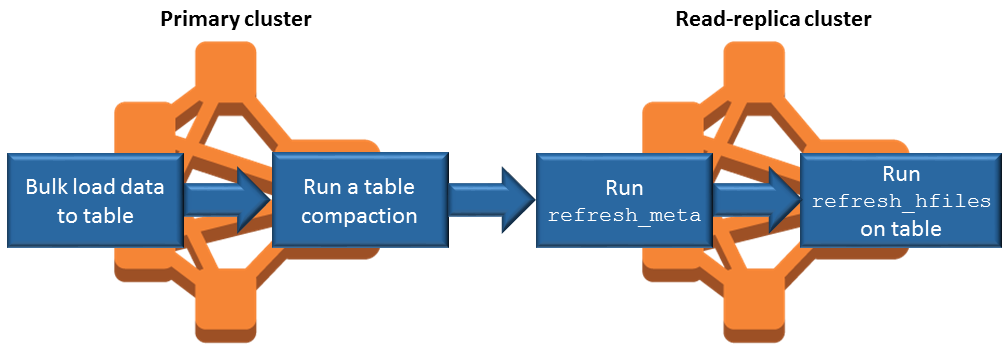
Muat data secara masal pada klaster utama bila memungkinkan. Untuk informasi selengkapnya, lihat Pemuatan massal
dalam HBase dokumentasi Apache. Sebuah flush yang menulis file penyimpanan ke Amazon S3 harus terjadi sesegera mungkin setelah data ditambahkan. Flush manual atau yang disesuaikan dengan pengaturan untuk meminimalkan waktu jeda.
Jika pemadatan dapat berjalan secara otomatis, jalankan pemadatan manual untuk menghindari inkonsistensi ketika pemadatan dipicu.
Pada cluster read-replica, ketika metadata apa pun telah berubah - misalnya, ketika pemisahan HBase wilayah atau pemadatan terjadi, atau ketika tabel ditambahkan atau dihapus - jalankan perintah.
refresh_metaPada klaster replika baca, jalankan
refresh_hfilesperintah ketika catatan ditambahkan ke atau diubah dalam tabel.
HFile Pelacakan persisten
HFile Pelacakan persisten menggunakan tabel HBase sistem yang dipanggil hbase:storefile untuk melacak HFile jalur yang digunakan untuk operasi baca secara langsung. HFile Jalur baru ditambahkan ke tabel saat data tambahan ditambahkan ke HBase. Ini menghapus operasi ganti nama sebagai mekanisme komit dalam HBase operasi jalur tulis kritis dan meningkatkan waktu pemulihan saat membuka HBase wilayah dengan membaca dari tabel hbase:storefile sistem alih-alih daftar direktori sistem file. Fitur ini diaktifkan secara default di Amazon EMR versi 6.2.0 hingga 7.3.0 dan tidak memerlukan langkah migrasi manual apa pun.
catatan
HFile Pelacakan persisten menggunakan tabel sistem HBase storefile tidak mendukung fitur replikasi HBase wilayah. Untuk informasi selengkapnya tentang replikasi HBase wilayah, lihat Bacaan tinggi yang tersedia sesuai waktu
Menonaktifkan Pelacakan Persisten HFile
HFile Pelacakan persisten diaktifkan secara default dimulai dengan rilis Amazon EMR 6.2.0. Untuk menonaktifkan HFile pelacakan persisten, tentukan penggantian konfigurasi berikut saat meluncurkan klaster:
{ "Classification": "hbase-site", "Properties": { "hbase.storefile.tracking.persist.enabled":"false", "hbase.hstore.engine.class":"org.apache.hadoop.hbase.regionserver.DefaultStoreEngine" } }
catatan
Ketika mengonfigurasi klaster Amazon EMR, semua grup instans harus diperbarui.
Menyinkronkan Tabel Storefile secara manual
Tabel storefile tetap up to date saat HFile instance baru dibuat. Namun, jika tabel storefile menjadi tidak sinkron dengan file data karena alasan apa pun, perintah yang mengikuti dapat digunakan untuk menyinkronkan data secara manual:
Sinkronkan tabel storefile di wilayah online:
hbase org.apache.hadoop.hbase.client.example.RefreshHFilesClient <table>
Sinkronkan tabel storefile di wilayah offline:
Hapus znode tabel penyimpanan file.
echo "ls /hbase/storefile/loaded" | sudo -u hbase hbase zkcli [<tableName>, hbase:namespace] # The TableName exists in the list echo "delete /hbase/storefile/loaded/<tableName>" | sudo -u hbase hbase zkcli # Delete the Table ZNode echo "ls /hbase/storefile/loaded" | sudo -u hbase hbase zkcli [hbase:namespace]Tetapkan wilayah (jalankan di 'Hbase shell').
hbase cli> assign '<region name>'Jika tugas gagal.
hbase cli> disable '<table name>' hbase cli> enable '<table name>'
Menskalakan Tabel Storefile
Tabel penyimpanan file dibagi menjadi empat wilayah secara default. Jika tabel penyimpanan file masih di bawah beban menulis berat, tabel dapat dibagi secara manual.
Untuk membagi wilayah panas tertentu, gunakan perintah berikut (jalankan di 'Hbase shell').
hbase cli> split '<region name>'
Untuk membagi tabel, gunakan perintah berikut (jalankan di 'Hbase shell').
hbase cli> split 'hbase:storefile'
Simpan Pelacakan File
Secara default, kami menggunakan FileBasedStoreFileTrackerimplementasi. Implementasi ini membuat file baru langsung di direktori store, menghindari kebutuhan untuk mengganti nama operasi. Itu menyimpan daftar instance hfile yang berkomitmen dalam memori, didukung oleh file meta di setiap direktori toko. Setiap kali hfile baru dilakukan, daftar file yang dilacak di toko yang diberikan diperbarui dan file meta baru ditulis dengan isi daftar dan membuang file meta sebelumnya, yang berisi daftar yang sudah ketinggalan zaman. Informasi lebih lanjut tentang Store File Tracking dapat ditemukan di Store File Tracking
Implementasi FileBasedStoreFile pelacak diaktifkan secara default, dimulai dengan Amazon EMR rilis 7.4.0:
{ "Classification": "hbase-site", "Properties": { hbase.store.file-tracker.impl: "org.apache.hadoop.hbase.regionserver.storefiletracker.FileBasedStoreFileTracker" }
Untuk menonaktifkan FileBasedStoreFileTracker implementasi, tentukan penggantian konfigurasi berikut saat meluncurkan cluster:
{ "Classification": "hbase-site", "Properties": { hbase.store.file-tracker.impl: "org.apache.hadoop.hbase.regionserver.storefiletracker.DefaultStoreFileTracker" }
catatan
Ketika mengonfigurasi klaster Amazon EMR, semua grup instans harus diperbarui.
Pertimbangan operasional
HBase server wilayah digunakan BlockCache untuk menyimpan data yang dibaca dalam memori dan BucketCache untuk menyimpan data yang dibaca pada disk lokal. Selain itu, server wilayah digunakan MemStore untuk menyimpan data yang ditulis dalam memori, dan menggunakan log tulis di depan untuk menyimpan data yang ditulis dalam HDFS sebelum data ditulis di Amazon HBase StoreFiles S3. Performa baca klaster Anda berhubungan dengan seberapa sering catatan dapat diambil dari di-memori atau di-disk cache. Kehilangan cache menghasilkan catatan yang dibaca dari Amazon S3, yang StoreFile memiliki latensi yang jauh lebih tinggi dan standar deviasi yang lebih tinggi daripada membaca dari HDFS. Selain itu, tingkat permintaan maksimum untuk Amazon S3 lebih rendah dari yang dapat dicapai dari cache lokal, jadi data caching mungkin penting untuk beban kerja baca-berat. Untuk informasi selengkapnya tentang performa Amazon S3, lihat Pengoptimalan kinerja di Panduan Pengguna Layanan Penyimpanan Sederhana Amazon.
Untuk meningkatkan kinerja, sebaiknya Anda menyimpan data sebanyak mungkin di penyimpanan EC2 instans. Karena BucketCache menggunakan penyimpanan EC2 instans server wilayah, Anda dapat memilih jenis EC2 instans dengan penyimpanan instans yang memadai dan menambahkan penyimpanan Amazon EBS untuk mengakomodasi ukuran cache yang diperlukan. Anda juga dapat meningkatkan BucketCache ukuran pada penyimpanan instans terlampir dan volume EBS menggunakan hbase.bucketcache.size properti. Pengaturan default adalah 8.192 MB.
Untuk penulisan, frekuensi MemStore flushes dan jumlah StoreFiles hadir selama pemadatan minor dan besar dapat berkontribusi secara signifikan terhadap peningkatan waktu respons server wilayah. Untuk kinerja optimal, pertimbangkan untuk meningkatkan ukuran MemStore flush dan HRegion block multiplier, yang meningkatkan waktu berlalu antara pemadatan utama, tetapi juga meningkatkan kelambatan dalam konsistensi jika Anda menggunakan replika baca. Dalam beberapa kasus, Anda mungkin mendapatkan performa yang lebih baik menggunakan ukuran blok file yang lebih besar (tetapi kurang dari 5 GB) untuk memicu fungsi unggahan multipart Amazon S3 di EMRFS. Ukuran blok Amazon EMR default 128 MB. Untuk informasi selengkapnya, lihat Konfigurasi HDFS. Kami jarang melihat pelanggan yang melebihi ukuran blok 1 GB saat membandingkan performa dengan flushes dan pemadatan. Selain itu, HBase pemadatan dan server wilayah bekerja secara optimal ketika lebih sedikit yang StoreFiles perlu dipadatkan.
Tabel dapat memakan banyak waktu untuk diletakkan di Amazon S3 karena direktori besar perlu diganti namanya. Pertimbangkan menonaktifkan tabel, alih-alih menjatuhkannya.
Ada proses yang HBase lebih bersih yang membersihkan file WAL lama dan menyimpan file. Dengan rilis Amazon EMR versi 5.17.0 dan yang lebih baru, pembersih diaktifkan secara global, dan properti konfigurasi berikut dapat digunakan untuk mengontrol perilaku bersih.
| Properti konfigurasi | Nilai default | Deskripsi |
|---|---|---|
|
|
1 |
Jumlah utas yang dialokasikan untuk membersihkan kadaluarsa besar. HFiles |
|
|
1 |
Jumlah utas yang dialokasikan untuk membersihkan kadaluarsa kecil. HFiles |
|
|
Atur ke seperempat dari semua core yang tersedia. |
Jumlah thread untuk memindai WALs direktori lama. |
|
|
2 |
Jumlah utas untuk membersihkan di WALs bawah WALs direktori lama. |
Dengan Amazon EMR 5.17.0 dan sebelumnya, operasi yang lebih bersih dapat mempengaruhi performa permintaan saat menjalankan beban kerja yang berat, jadi kami sarankan agar Anda mengaktifkan pembersih hanya selama waktu off-peak. Pembersih memiliki perintah HBase shell berikut:
cleaner_chore_enabledpertanyaan apakah pembersih diaktifkan.cleaner_chore_runmenjalankan pembersih secara manual untuk menghapus file.cleaner_chore_switchmengaktifkan atau menonaktifkan pembersih dan mengembalikan keadaan pembersih sebelumnya. Misalnya,cleaner_chore_switch truemengaktifkan pembersih.
Properti untuk HBase penyetelan kinerja Amazon S3
Parameter berikut dapat disesuaikan untuk menyetel kinerja beban kerja Anda saat Anda menggunakan HBase di Amazon S3.
| Properti konfigurasi | Nilai default | Deskripsi |
|---|---|---|
|
|
8,192 |
Jumlah ruang disk, dalam MB, yang dicadangkan di server wilayah penyimpanan EC2 instans Amazon dan volume EBS untuk BucketCache penyimpanan. Pengaturan ini berlaku untuk semua instans server wilayah. BucketCache Ukuran yang lebih besar umumnya sesuai dengan peningkatan kinerja |
|
|
134217728 |
Batas data, dalam byte, di mana memstore flush ke Amazon S3 dipicu. |
|
|
4 |
Pengganda yang menentukan batas MemStore atas di mana pembaruan diblokir. Jika MemStore melebihi |
|
|
10 |
Jumlah maksimum StoreFiles yang dapat ada di toko sebelum pembaruan diblokir. |
|
|
10737418240 |
Ukuran maksimum wilayah sebelum dibagi. |
Mematikan dan memulihkan klaster tanpa kehilangan data
Untuk mematikan cluster EMR Amazon tanpa kehilangan data yang belum ditulis ke Amazon S3, Anda harus menyiram cache Anda MemStore ke Amazon S3 untuk menulis file toko baru. Pertama, Anda harus menonaktifkan semua tabel. Konfigurasi langkah berikut dapat digunakan saat Anda menambahkan langkah ke klaster. Untuk informasi selengkapnya, lihat Bekerja dengan langkah-langkah menggunakan AWS CLI dan konsol di Panduan Manajemen EMR Amazon.
Name="Disable all tables",Jar="command-runner.jar",Args=["/bin/bash","/usr/lib/hbase/bin/disable_all_tables.sh"]
Atau, Anda dapat menjalankan perintah bash berikut secara langsung.
bash /usr/lib/hbase/bin/disable_all_tables.sh
Setelah menonaktifkan semua tabel, siram hbase:meta tabel menggunakan HBase shell dan perintah berikut.
flush 'hbase:meta'
Kemudian, Anda dapat menjalankan skrip shell yang disediakan di cluster EMR Amazon untuk membersihkan cache. MemStore Anda dapat menambahkannya sebagai langkah atau menjalankannya langsung menggunakan on-cluster AWS CLI. Skrip menonaktifkan semua HBase tabel, yang menyebabkan server MemStore di setiap wilayah mengalir ke Amazon S3. Jika skrip sudah selesai, data akan tetap ada di Amazon S3 dan klaster dapat dihentikan.
Untuk memulai ulang cluster dengan HBase data yang sama, tentukan lokasi Amazon S3 yang sama dengan cluster sebelumnya baik di AWS Management Console atau menggunakan properti hbase.rootdir konfigurasi.
