Terjemahan disediakan oleh mesin penerjemah. Jika konten terjemahan yang diberikan bertentangan dengan versi bahasa Inggris aslinya, utamakan versi bahasa Inggris.
Bagaimana Iceberg bekerja
Iceberg melacak file data individual dalam tabel, bukan di direktori. Dengan cara ini, penulis dapat membuat file data di tempat (file tidak dipindahkan atau diubah). Selain itu, penulis hanya dapat menambahkan file ke tabel dalam komit eksplisit. Status tabel dipertahankan dalam file metadata. Semua perubahan pada status tabel membuat file metadata baru yang secara atomik menggantikan metadata yang lebih lama. File metadata tabel melacak skema tabel, konfigurasi partisi, dan properti lainnya.
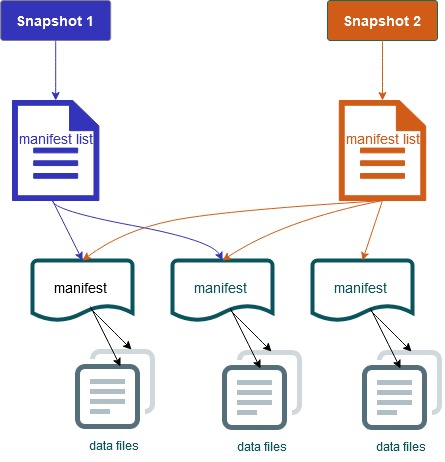
Ini juga termasuk snapshot dari isi tabel. Setiap snapshot adalah satu set lengkap file data dalam tabel pada suatu titik waktu. Snapshot tercantum dalam file metadata, tetapi file dalam snapshot disimpan dalam file manifes terpisah. Transisi atom dari satu file metadata tabel ke file berikutnya memberikan isolasi snapshot. Pembaca menggunakan snapshot yang terkini saat mereka memuat metadata tabel. Pembaca tidak terpengaruh oleh perubahan sampai mereka menyegarkan dan mengambil lokasi metadata baru. File data dalam snapshot disimpan dalam satu atau lebih file manifes yang berisi baris untuk setiap file data dalam tabel, data partisi, dan metriknya. Snapshot adalah penyatuan semua file dalam manifestasnya. File manifes juga dapat dibagikan di antara snapshot untuk menghindari penulisan ulang metadata yang jarang berubah.
Diagram snapshot gunung es
Iceberg menawarkan fitur-fitur berikut:
-
Mendukung transaksi ACID dan perjalanan waktu di danau data Amazon S3 Anda.
-
Commit retries mendapat manfaat dari keunggulan kinerja konkurensi optimis
. -
Resolusi konflik tingkat file menghasilkan konkurensi yang tinggi.
-
Dengan statistik min-max per kolom dalam metadata, Anda dapat melewati file, yang meningkatkan kinerja untuk kueri selektif.
-
Anda dapat mengatur tabel ke dalam tata letak partisi yang fleksibel, dengan evolusi partisi memungkinkan pembaruan ke skema partisi. Kueri dan volume data kemudian dapat berubah tanpa bergantung pada direktori fisik.
-
Mendukung evolusi skema
dan penegakan hukum. -
Tabel gunung es bertindak sebagai wastafel idempoten dan sumber yang dapat diputar ulang. Ini memungkinkan streaming dan dukungan batch dengan pipeline yang tepat sekali. Idempoten tenggelam melacak operasi penulisan yang telah berhasil di masa lalu. Oleh karena itu, wastafel dapat meminta data lagi jika terjadi kegagalan, dan menjatuhkan data jika telah dikirim beberapa kali.
-
Lihat riwayat dan garis keturunan, termasuk evolusi tabel, riwayat operasi, dan statistik untuk setiap komit.
-
Bermigrasi dari dataset yang ada dengan pilihan format data (Parquet, ORC, Avro) dan mesin analitik (Spark, Trino, PrestODB, Flink, Hive).
