Terjemahan disediakan oleh mesin penerjemah. Jika konten terjemahan yang diberikan bertentangan dengan versi bahasa Inggris aslinya, utamakan versi bahasa Inggris.
Penskalaan otomatis Flink
Gambaran Umum
Amazon EMR merilis 6.15.0 dan dukungan yang lebih tinggi Flink autoscaler. Fungsionalitas job autoscaler mengumpulkan metrik dari menjalankan pekerjaan streaming Flink, dan secara otomatis menskalakan verteks pekerjaan individual. Ini mengurangi tekanan balik dan memenuhi target pemanfaatan yang Anda tetapkan.
Untuk informasi selengkapnya, lihat bagian Autoscaler
Pertimbangan
-
Flink autoscaler didukung dengan Amazon EMR 6.15.0 dan lebih tinggi.
-
Flink autoscaler hanya didukung untuk pekerjaan streaming.
-
Hanya penjadwal adaptif yang didukung. Penjadwal default tidak didukung.
-
Kami menyarankan Anda mengaktifkan penskalaan klaster untuk memungkinkan penyediaan sumber daya dinamis. Penskalaan terkelola Amazon EMR lebih disukai `karena evaluasi metrik terjadi setiap 5-10 detik. Pada interval ini, klaster Anda dapat lebih mudah menyesuaikan diri dengan perubahan sumber daya cluster yang diperlukan.
Aktifkan autoscaler
Gunakan langkah-langkah berikut untuk mengaktifkan penskalaan otomatis Flink saat Anda membuat Amazon EMR di klaster. EC2
-
Di konsol EMR Amazon, buat cluster EMR baru:
-
Pilih rilis EMR Amazon
emr-6.15.0atau yang lebih tinggi. Pilih bundel aplikasi Flink, dan pilih aplikasi lain yang mungkin ingin Anda sertakan di cluster Anda.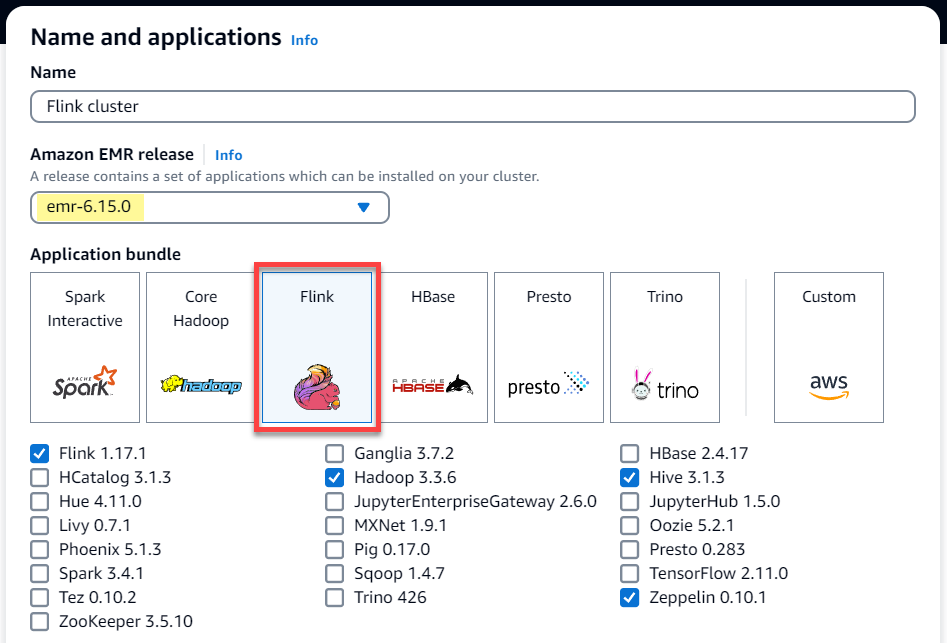
-
Untuk opsi penskalaan dan penyediaan Cluster, pilih Gunakan penskalaan yang dikelola EMR.

-
-
Di bagian Pengaturan perangkat lunak, masukkan konfigurasi berikut untuk mengaktifkan Flink autoscaler. Untuk skenario pengujian, atur interval keputusan, interval jendela metrik, dan interval stabilisasi ke nilai yang lebih rendah sehingga pekerjaan segera membuat keputusan penskalaan untuk verifikasi yang lebih mudah.
[ { "Classification": "flink-conf", "Properties": { "job.autoscaler.enabled": "true", "jobmanager.scheduler": "adaptive", "job.autoscaler.stabilization.interval": "60s", "job.autoscaler.metrics.window": "60s", "job.autoscaler.decision.interval": "10s", "job.autoscaler.debug.logs.interval": "60s" } } ] -
Pilih atau konfigurasikan pengaturan lain sesuai keinginan Anda, dan buat cluster berkemampuan autoscaler Flink.
Konfigurasi Autoscaler
Bagian ini mencakup sebagian besar konfigurasi yang dapat Anda ubah berdasarkan kebutuhan spesifik Anda.
catatan
Dengan konfigurasi berbasis waktu sepertitime, interval dan window pengaturan, unit default ketika tidak ada unit yang ditentukan adalah milidetik. Jadi nilai tanpa akhiran sama 30 dengan 30 milidetik. Untuk satuan waktu lainnya, sertakan sufiks yang sesuai s untuk detik, m menit, atau h berjam-jam.
Topik
Konfigurasi loop autoscaler
Autoscaler mengambil metrik tingkat titik pekerjaan untuk setiap beberapa interval waktu yang dapat dikonfigurasi, mengubahnya menjadi skala yang dapat ditindaklanjuti, memperkirakan paralelisme vertex pekerjaan baru, dan merekomendasikannya ke penjadwal pekerjaan. Metrik dikumpulkan hanya setelah waktu restart pekerjaan dan interval stabilisasi cluster.
| Kunci Config | Nilai default | Deskripsi | Contoh nilai |
|---|---|---|---|
job.autoscaler.enabled |
false |
Aktifkan penskalaan otomatis pada cluster Flink Anda. | true, false |
job.autoscaler.decision.interval |
60s |
Interval keputusan autoscaler. | 30(unit default adalah milidetik),, 5m 1h |
job.autoscaler.restart.time |
3m |
Waktu restart yang diharapkan untuk digunakan hingga operator dapat menentukannya dengan andal dari riwayat. | 30(unit default adalah milidetik),, 5m 1h |
job.autoscaler.stabilization.interval |
300s |
Periode stabilisasi di mana tidak ada penskalaan baru yang akan dieksekusi. | 30(unit default adalah milidetik),, 5m 1h |
job.autoscaler.debug.logs.interval |
300s |
Interval log debug autoscaler. | 30(unit default adalah milidetik),, 5m 1h |
Agregasi metrik dan konfigurasi riwayat
Autoscaler mengambil metrik, menggabungkannya dari jendela geser berbasis waktu dan ini dievaluasi ke dalam keputusan penskalaan. Riwayat keputusan penskalaan untuk setiap titik pekerjaan digunakan untuk memperkirakan paralelisme baru. Ini memiliki kedaluwarsa berdasarkan usia serta ukuran sejarah (setidaknya 1).
| Kunci Config | Nilai default | Deskripsi | Contoh nilai |
|---|---|---|---|
job.autoscaler.metrics.window |
600s |
Scaling metrics aggregation window size. |
30(unit default adalah milidetik),, 5m 1h |
job.autoscaler.history.max.count |
3 |
Jumlah maksimum keputusan penskalaan sebelumnya untuk mempertahankan per simpul. | 1 untuk Integer.MAX_VALUE |
job.autoscaler.history.max.age |
24h |
Jumlah minimum keputusan penskalaan sebelumnya untuk mempertahankan per simpul. | 30(unit default adalah milidetik),, 5m 1h |
Konfigurasi tingkat Job Vertex
Paralelisme setiap titik pekerjaan dimodifikasi berdasarkan pemanfaatan target dan dibatasi oleh batas paralelisme min-max. Tidak disarankan untuk menetapkan pemanfaatan target mendekati 100% (yaitu nilai 1) dan batas pemanfaatan berfungsi sebagai buffer untuk menangani fluktuasi beban menengah.
| Kunci Config | Nilai default | Deskripsi | Contoh nilai |
|---|---|---|---|
job.autoscaler.target.utilization |
0.7 |
Target pemanfaatan simpul. | 0 - 1 |
job.autoscaler.target.utilization.boundary |
0.4 |
Batas pemanfaatan simpul target. Penskalaan tidak akan dilakukan jika laju pemrosesan saat ini berada di dalam[target_rate /
(target_utilization - boundary), dan (target_rate /
(target_utilization + boundary)] |
0 - 1 |
job.autoscaler.vertex.min-parallelism |
1 |
Paralelisme minimum yang dapat digunakan autoscaler. | 0 - 200 |
job.autoscaler.vertex.max-parallelism |
200 |
Paralelisme maksimum yang dapat digunakan autoscaler. Perhatikan bahwa batas ini akan diabaikan jika lebih tinggi dari paralelisme maks yang dikonfigurasi dalam konfigurasi Flink atau langsung pada setiap operator. | 0 - 200 |
Konfigurasi pemrosesan backlog
Vertex pekerjaan membutuhkan sumber daya tambahan untuk menangani peristiwa yang tertunda, atau backlog, yang terakumulasi selama periode waktu operasi skala. Ini juga disebut sebagai catch-up durasi. Jika waktu untuk memproses backlog melebihi lag -threshold nilai yang dikonfigurasi, pemanfaatan target vertex pekerjaan meningkat ke level maksimal. Ini membantu mencegah operasi penskalaan yang tidak perlu saat proses backlog.
| Kunci Config | Nilai default | Deskripsi | Contoh nilai |
|---|---|---|---|
job.autoscaler.backlog-processing.lag-threshold |
5m |
Ambang batas lag yang akan mencegah penskalaan yang tidak perlu saat menghapus pesan tertunda yang bertanggung jawab atas kelambatan. | 30(unit default adalah milidetik),, 5m 1h |
job.autoscaler.catch-up.duration |
15m |
Durasi target untuk sepenuhnya memproses backlog apa pun setelah operasi penskalaan. Setel ke 0 untuk menonaktifkan penskalaan berbasis backlog. | 30(unit default adalah milidetik),, 5m 1h |
Konfigurasi operasi skala
Autoscaler tidak melakukan operasi penskalaan segera setelah operasi penskalaan dalam periode waktu tenggang. Ini mencegah siklus up-down-up-down operasi skala yang tidak diperlukan yang disebabkan oleh fluktuasi beban sementara.
Kita dapat menggunakan rasio operasi skala turun untuk secara bertahap mengurangi paralelisme dan melepaskan sumber daya untuk memenuhi lonjakan beban sementara. Ini juga membantu mencegah operasi skala kecil yang tidak diperlukan pasca operasi penurunan skala besar.
Kami dapat mendeteksi operasi skala yang efektif berdasarkan riwayat keputusan penskalaan titik pekerjaan sebelumnya untuk mencegah perubahan paralelisme lebih lanjut.
| Kunci Config | Nilai default | Deskripsi | Contoh nilai |
|---|---|---|---|
job.autoscaler.scale-up.grace-period |
1h |
Durasi di mana tidak ada penurunan skala dari simpul yang diizinkan setelah ditingkatkan. | 30(unit default adalah milidetik),, 5m 1h |
job.autoscaler.scale-down.max-factor |
0.6 |
Faktor penurunan skala maks. Nilai 1 berarti tidak ada batasan pada skala ke bawah; 0.6 berarti pekerjaan hanya dapat diperkecil dengan 60% dari paralelisme asli. |
0 - 1 |
job.autoscaler.scale-up.max-factor |
100000. |
Rasio peningkatan skala maksimum. Nilai pekerjaan 2.0 berarti hanya dapat ditingkatkan dengan 200% dari paralelisme saat ini. |
0 - Integer.MAX_VALUE |
job.autoscaler.scaling.effectiveness.detection.enabled |
false |
Apakah akan mengaktifkan deteksi operasi penskalaan yang tidak efektif dan memungkinkan penskalaan otomatis untuk memblokir peningkatan skala lebih lanjut. | true, false |
