Terjemahan disediakan oleh mesin penerjemah. Jika konten terjemahan yang diberikan bertentangan dengan versi bahasa Inggris aslinya, utamakan versi bahasa Inggris.
Bekerja dengan pekerjaan Flink dari Zeppelin di Amazon EMR
Pengantar
Amazon EMR merilis 6.10.0 dan Apache Zeppelin integrasi dukungan yang lebih tinggi dengan Apache Flink. Anda dapat secara interaktif mengirimkan pekerjaan Flink melalui notebook Zeppelin. Dengan penerjemah Flink, Anda dapat menjalankan kueri Flink, menentukan streaming Flink dan pekerjaan batch, dan memvisualisasikan output dalam notebook Zeppelin. Interpreter Flink dibangun di atas Flink REST API. Ini memungkinkan Anda mengakses dan memanipulasi pekerjaan Flink dari dalam lingkungan Zeppelin untuk melakukan pemrosesan dan analisis data waktu nyata.
Ada empat sub-interpreter dalam penerjemah Flink. Mereka melayani tujuan yang berbeda, tetapi semuanya ada di JVM dan berbagi titik masuk pra-konfigurasi yang sama ke Flink (ExecutionEnviroment,,,StreamExecutionEnvironment). BatchTableEnvironment StreamTableEnvironment Penerjemah adalah sebagai berikut:
-
%flink— MenciptakanExecutionEnvironment,StreamExecutionEnvironment,BatchTableEnvironment,StreamTableEnvironment, dan menyediakan lingkungan Scala -
%flink.pyflink— Menyediakan lingkungan Python -
%flink.ssql— Menyediakan lingkungan SQL streaming -
%flink.bsql— Menyediakan lingkungan SQL batch
Prasyarat
-
Integrasi Zeppelin dengan Flink didukung untuk cluster yang dibuat dengan Amazon EMR 6.10.0 dan yang lebih tinggi.
-
Untuk melihat antarmuka web yang di-host pada kluster EMR seperti yang diperlukan untuk langkah-langkah ini, Anda harus mengkonfigurasi terowongan SSH untuk memungkinkan akses masuk. Untuk informasi selengkapnya, lihat Mengonfigurasi setelan proxy untuk melihat situs web yang dihosting di simpul utama.
Konfigurasikan Zeppelin-Flink pada cluster EMR
Gunakan langkah-langkah berikut untuk mengkonfigurasi Apache Flink pada Apache Zeppelin untuk berjalan pada cluster EMR:
-
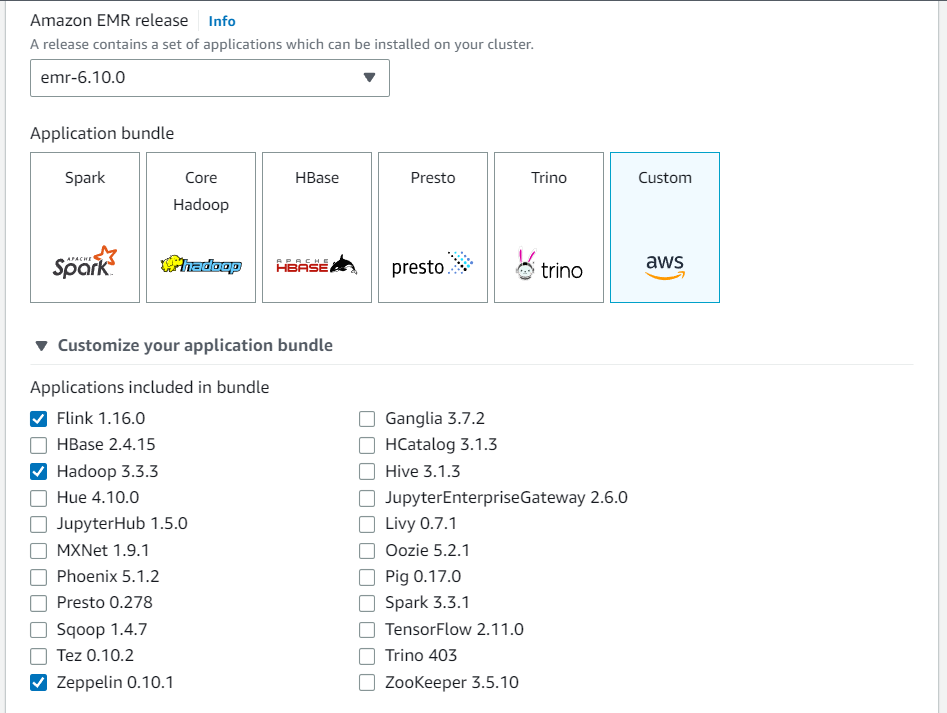
Buat cluster baru dari konsol EMR Amazon. Pilih emr-6.10.0 atau yang lebih tinggi untuk rilis EMR Amazon. Kemudian, pilih untuk menyesuaikan bundel aplikasi Anda dengan opsi Kustom. Sertakan setidaknya Flink, Hadoop, dan Zeppelin dalam bundel Anda.
-
Buat sisa cluster Anda dengan pengaturan yang Anda inginkan.
-
Setelah cluster Anda berjalan, pilih cluster di konsol untuk melihat detailnya dan buka tab Applications. Pilih Zeppelin dari bagian Antarmuka pengguna aplikasi untuk membuka antarmuka web Zeppelin. Pastikan bahwa Anda telah mengatur akses ke antarmuka web Zeppelin dengan terowongan SSH ke node utama dan koneksi proxy seperti yang dijelaskan dalam. Prasyarat
-
Sekarang, Anda dapat membuat catatan baru di notebook Zeppelin dengan Flink sebagai penerjemah default.

-
Lihat contoh kode berikut yang menunjukkan cara menjalankan pekerjaan Flink dari notebook Zeppelin.
Jalankan pekerjaan Flink dengan Zeppelin-Flink di cluster EMR
-
Contoh 1, Flink Scala
a) WordCount Contoh Batch (SCALA)
%flink val data = benv.fromElements("hello world", "hello flink", "hello hadoop") data.flatMap(line => line.split("\\s")) .map(w => (w, 1)) .groupBy(0) .sum(1) .print()b) WordCount Contoh Streaming (SCALA)
%flink val data = senv.fromElements("hello world", "hello flink", "hello hadoop") data.flatMap(line => line.split("\\s")) .map(w => (w, 1)) .keyBy(0) .sum(1) .print senv.execute()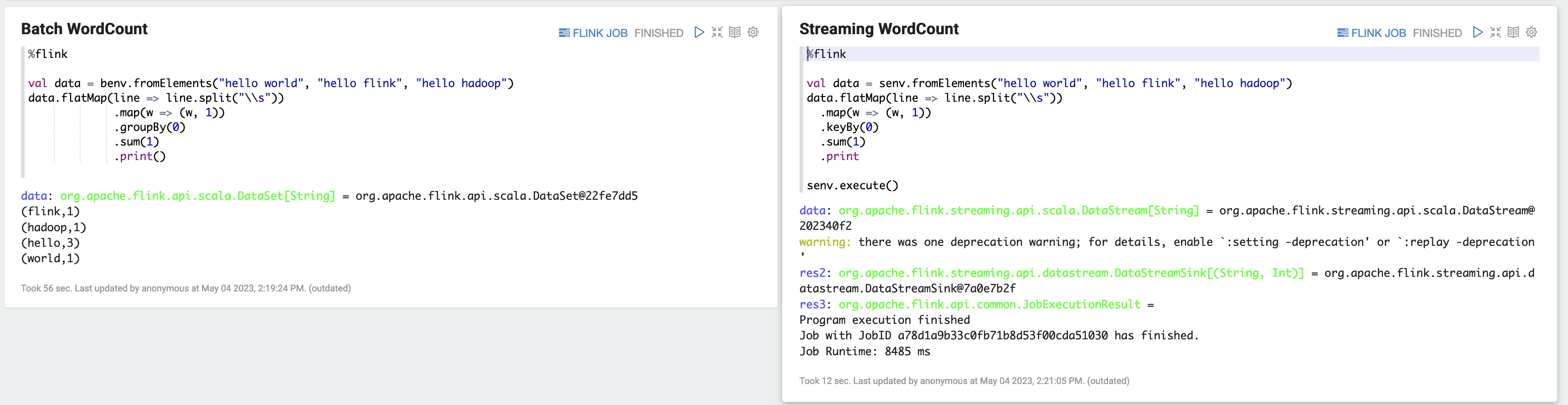
-
Contoh 2, Flink Streaming SQL
%flink.ssql SET 'sql-client.execution.result-mode' = 'tableau'; SET 'table.dml-sync' = 'true'; SET 'execution.runtime-mode' = 'streaming'; create table dummy_table ( id int, data string ) with ( 'connector' = 'filesystem', 'path' = 's3://s3-bucket/dummy_table', 'format' = 'csv' ); INSERT INTO dummy_table SELECT * FROM (VALUES (1, 'Hello World'), (2, 'Hi'), (2, 'Hi'), (3, 'Hello'), (3, 'World'), (4, 'ADD'), (5, 'LINE')); SELECT * FROM dummy_table;
-
Contoh 3, Pyflink. Perhatikan bahwa Anda harus mengunggah file teks sampel Anda sendiri yang diberi nama
word.txtke bucket S3 Anda.%flink.pyflink import argparse import logging import sys from pyflink.common import Row from pyflink.table import (EnvironmentSettings, TableEnvironment, TableDescriptor, Schema, DataTypes, FormatDescriptor) from pyflink.table.expressions import lit, col from pyflink.table.udf import udtf def word_count(input_path, output_path): t_env = TableEnvironment.create(EnvironmentSettings.in_streaming_mode()) # write all the data to one file t_env.get_config().set("parallelism.default", "1") # define the source if input_path is not None: t_env.create_temporary_table( 'source', TableDescriptor.for_connector('filesystem') .schema(Schema.new_builder() .column('word', DataTypes.STRING()) .build()) .option('path', input_path) .format('csv') .build()) tab = t_env.from_path('source') else: print("Executing word_count example with default input data set.") print("Use --input to specify file input.") tab = t_env.from_elements(map(lambda i: (i,), word_count_data), DataTypes.ROW([DataTypes.FIELD('line', DataTypes.STRING())])) # define the sink if output_path is not None: t_env.create_temporary_table( 'sink', TableDescriptor.for_connector('filesystem') .schema(Schema.new_builder() .column('word', DataTypes.STRING()) .column('count', DataTypes.BIGINT()) .build()) .option('path', output_path) .format(FormatDescriptor.for_format('canal-json') .build()) .build()) else: print("Printing result to stdout. Use --output to specify output path.") t_env.create_temporary_table( 'sink', TableDescriptor.for_connector('print') .schema(Schema.new_builder() .column('word', DataTypes.STRING()) .column('count', DataTypes.BIGINT()) .build()) .build()) @udtf(result_types=[DataTypes.STRING()]) def split(line: Row): for s in line[0].split(): yield Row(s) # compute word count tab.flat_map(split).alias('word') \ .group_by(col('word')) \ .select(col('word'), lit(1).count) \ .execute_insert('sink') \ .wait() logging.basicConfig(stream=sys.stdout, level=logging.INFO, format="%(message)s") word_count("s3://s3_bucket/word.txt", "s3://s3_bucket/demo_output.txt")
-
Pilih FLINK JOB di UI Zeppelin untuk mengakses dan melihat UI Web Flink.

-
Memilih rute FLINK JOB ke Konsol Web Flink di tab lain di browser Anda.