Terjemahan disediakan oleh mesin penerjemah. Jika konten terjemahan yang diberikan bertentangan dengan versi bahasa Inggris aslinya, utamakan versi bahasa Inggris.
Menggunakan penskalaan otomatis untuk AWS Glue
Auto Scaling tersedia untuk AWS Glue ETL, sesi interaktif, dan pekerjaan streaming Anda dengan AWS Glue versi 3.0 atau yang lebih baru.
Dengan Auto Scaling diaktifkan, Anda akan mendapatkan manfaat berikut:
-
AWS Gluesecara otomatis menambahkan dan menghapus pekerja dari cluster tergantung pada paralelisme pada setiap tahap atau microbatch dari pekerjaan yang dijalankan.
-
Ini mengurangi kebutuhan bagi Anda untuk bereksperimen dan memutuskan jumlah pekerja yang akan ditugaskan untuk pekerjaan AWS Glue ETL Anda.
-
Dengan jumlah maksimum pekerja yang diberikan, AWS Glue akan memilih sumber daya ukuran yang tepat untuk beban kerja.
-
Anda dapat melihat bagaimana ukuran klaster berubah selama pekerjaan dijalankan dengan melihat CloudWatch metrik pada halaman rincian pekerjaan yang dijalankan di AWS Glue Studio.
Auto Scaling untuk AWS Glue ETL dan pekerjaan streaming memungkinkan penskalaan sesuai permintaan dan penskalaan sumber daya komputasi pekerjaan Anda. AWS Glue Peningkatan skala sesuai permintaan membantu Anda untuk hanya mengalokasikan sumber daya komputasi yang diperlukan pada awalnya pada startup yang dijalankan pekerjaan, dan juga untuk menyediakan sumber daya yang diperlukan sesuai permintaan selama pekerjaan.
Auto Scaling juga mendukung penskalaan dinamis dari sumber daya AWS Glue pekerjaan selama pekerjaan. Selama menjalankan pekerjaan, ketika lebih banyak pelaksana diminta oleh aplikasi Spark Anda, lebih banyak pekerja akan ditambahkan ke cluster. Ketika eksekutor telah menganggur tanpa tugas komputasi aktif, pelaksana dan pekerja terkait akan dihapus.
Skenario umum di mana Auto Scaling membantu biaya dan pemanfaatan untuk aplikasi Spark Anda meliputi:
-
driver Spark yang mencantumkan sejumlah besar file di Amazon S3 atau melakukan pemuatan saat pelaksana tidak aktif
-
Tahap percikan berjalan dengan hanya beberapa eksekutor karena penyediaan berlebihan
-
kemiringan data atau permintaan komputasi yang tidak merata di seluruh tahap Spark
Persyaratan
Auto Scaling hanya tersedia untuk AWS Glue versi 3.0 atau yang lebih baru. Untuk menggunakan Auto Scaling, Anda dapat mengikuti panduan migrasi untuk memigrasi pekerjaan yang ada ke AWS Glue versi 3.0 atau yang lebih baru atau membuat pekerjaan baru dengan AWS Glue versi 3.0 atau yang lebih baru.
Auto Scaling tersedia untuk AWS Glue pekerjaan dengan tipe pekerjaG.1X,G.2X,G.4X, G.8XG.12X,G.16X,R.1X,R.2X, R.4XR.8X, atau G.025X (hanya untuk pekerjaan Streaming). Standar tidak DPUs didukung untuk Auto Scaling.
Mengaktifkan Auto Scaling di AWS Glue Studio
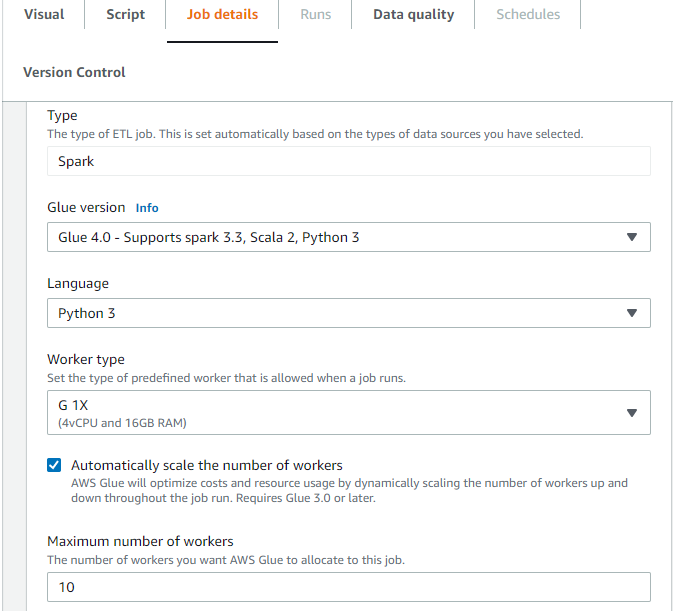
Pada tab Job details di AWS Glue Studio, pilih jenis sebagai Spark atau Spark Streaming, dan Glue versi sebagai Glue 3.0 atau yang lebih baru. Kemudian, kotak centang akan muncul di bawah Jenis pekerja.
-
Pilih opsi Skala jumlah pekerja secara otomatis.
-
Tetapkan jumlah maksimum pekerja untuk menentukan jumlah maksimum pekerja yang dapat dijual untuk menjalankan pekerjaan.
Mengaktifkan Auto Scaling dengan AWS CLI atau SDK
Untuk mengaktifkan Auto Scaling dari AWS CLI untuk menjalankan pekerjaan Anda, jalankan start-job-run dengan konfigurasi berikut:
{ "JobName": "<your job name>", "Arguments": { "--enable-auto-scaling": "true" }, "WorkerType": "G.2X", // G.1X, G.2X, G.4X, G.8X, G.12X, G.16X, R.1X, R.2X, R.4X, and R.8X are supported for Auto Scaling Jobs "NumberOfWorkers": 20, // represents Maximum number of workers ...other job run configurations... }
Setelah menjalankan tugas ETL selesai, Anda juga dapat menelepon get-job-run untuk memeriksa penggunaan sumber daya aktual dari pekerjaan yang dijalankan dalam DPU-detik. Catatan: bidang baru hanya DPUSecondsakan muncul untuk pekerjaan batch Anda di AWS Glue 4.0 atau yang lebih baru diaktifkan dengan Auto Scaling. Bidang ini tidak didukung untuk pekerjaan streaming.
$ aws glue get-job-run --job-name your-job-name --run-id jr_xx --endpoint https://glue.us-east-1.amazonaws.com --region us-east-1 { "JobRun": { ... "GlueVersion": "3.0", "DPUSeconds": 386.0 } }
Anda juga dapat mengonfigurasi job run dengan Auto Scaling menggunakan AWS Glue SDK dengan konfigurasi yang sama.
Mengaktifkan Auto Scaling dengan sesi Interaktif
Untuk mengaktifkan Auto Scaling saat membuat AWS Glue pekerjaan dengan sesi interaktif, lihat Mengonfigurasi AWS Glue sesi interaktif.
Kiat dan pertimbangan
Kiat dan pertimbangan untuk menyempurnakan Auto AWS Glue Scaling:
-
Jika Anda tidak memiliki gagasan tentang nilai awal dari jumlah maksimum pekerja, Anda dapat mulai dari perhitungan kasar yang dijelaskan dalam Estimasi AWS Glue DPU. Anda tidak boleh mengonfigurasi nilai yang sangat besar dalam jumlah maksimum pekerja untuk data volume yang sangat rendah.
-
AWS Glue Auto Scaling mengkonfigurasi
spark.sql.shuffle.partitionsdanspark.default.parallelismberdasarkan jumlah maksimum DPU (dihitung dengan jumlah maksimum pekerja dan jenis pekerja) yang dikonfigurasi pada pekerjaan. Jika Anda lebih suka nilai tetap pada konfigurasi tersebut, Anda dapat menimpa parameter ini dengan parameter pekerjaan berikut:-
Kunci:
--conf -
Nilai:
spark.sql.shuffle.partitions=200 --conf spark.default.parallelism=200
-
-
Untuk pekerjaan streaming, secara default, AWS Glue tidak melakukan penskalaan otomatis dalam batch mikro dan memerlukan beberapa batch mikro untuk memulai penskalaan otomatis. Jika Anda ingin mengaktifkan penskalaan otomatis dalam batch mikro, sediakan.
--auto-scale-within-microbatchUntuk informasi selengkapnya, lihat Referensi parameter Job.
Memantau Auto Scaling dengan metrik Amazon CloudWatch
Metrik CloudWatch pelaksana tersedia untuk pekerjaan AWS Glue 3.0 atau yang lebih baru jika Anda mengaktifkan Auto Scaling. Metrik dapat digunakan untuk memantau permintaan dan penggunaan pelaksana yang dioptimalkan dalam aplikasi Spark mereka yang diaktifkan dengan Auto Scaling. Untuk informasi selengkapnya, lihat Pemantauan AWS Glue menggunakan CloudWatch metrik Amazon.
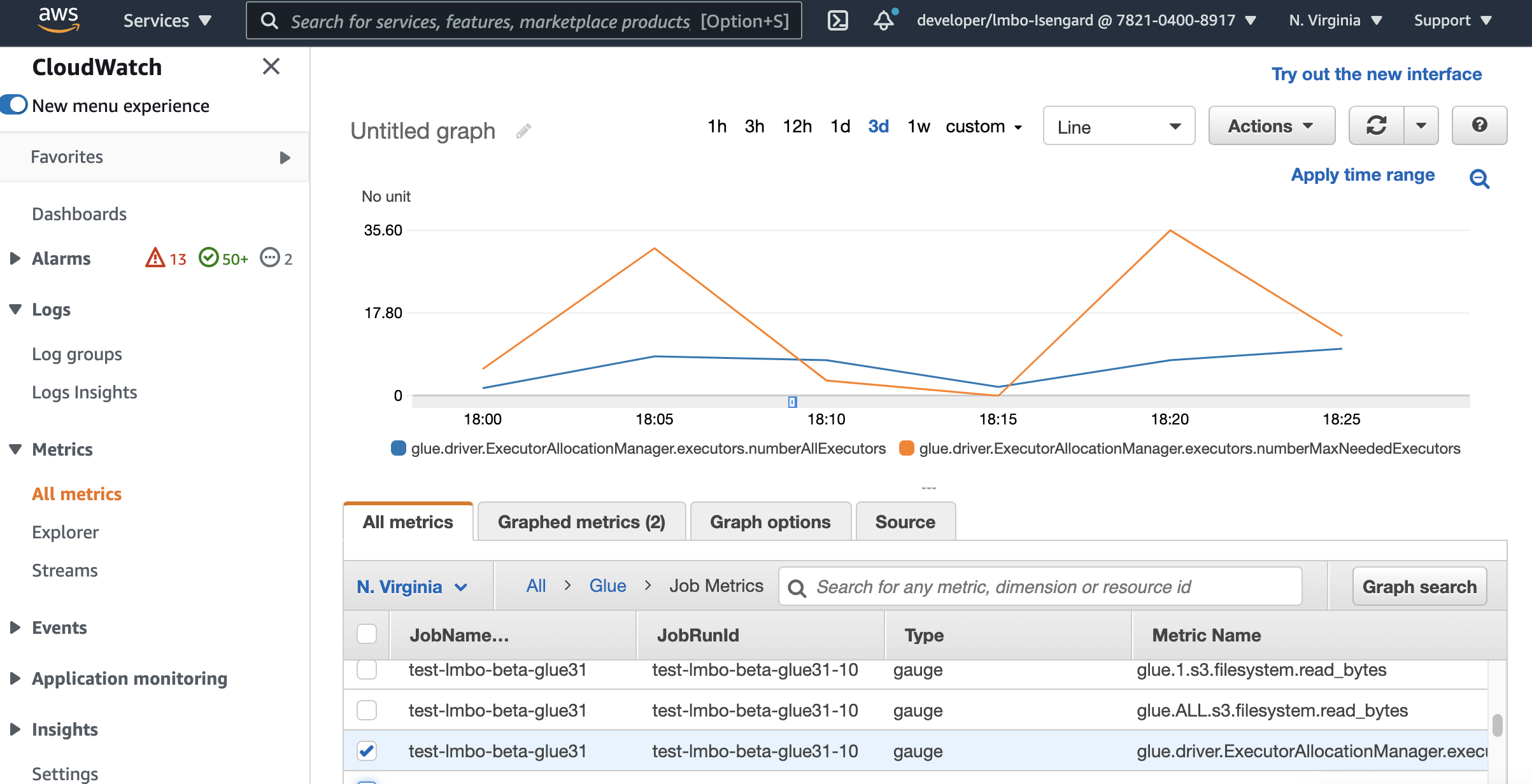
Anda juga dapat menggunakan metrik AWS Glue observabilitas untuk mendapatkan wawasan tentang pemanfaatan sumber daya. Misalnya, dengan memantauglue.driver.workerUtilization, Anda dapat memantau berapa banyak sumber daya yang sebenarnya digunakan dengan dan tanpa penskalaan otomatis. Untuk contoh lain, dengan memantau glue.driver.skewness.job danglue.driver.skewness.stage, Anda dapat melihat bagaimana data miring. Wawasan tersebut akan membantu Anda memutuskan untuk mengaktifkan penskalaan otomatis dan menyempurnakan konfigurasi. Untuk informasi selengkapnya, lihat Memantau denganPemantauan dengan metrik AWS Glue Observabilitas.
-
lem.driver. ExecutorAllocationManager.pelaksana. numberAllExecutors
-
lem.driver. ExecutorAllocationManager.pelaksana. numberMaxNeededPelaksana
Untuk detail selengkapnya tentang metrik ini, lihatPemantauan perencanaan kapasitas DPU.
catatan
CloudWatch Metrik pelaksana tidak tersedia untuk sesi interaktif.
Memantau Auto Scaling dengan Amazon Logs CloudWatch
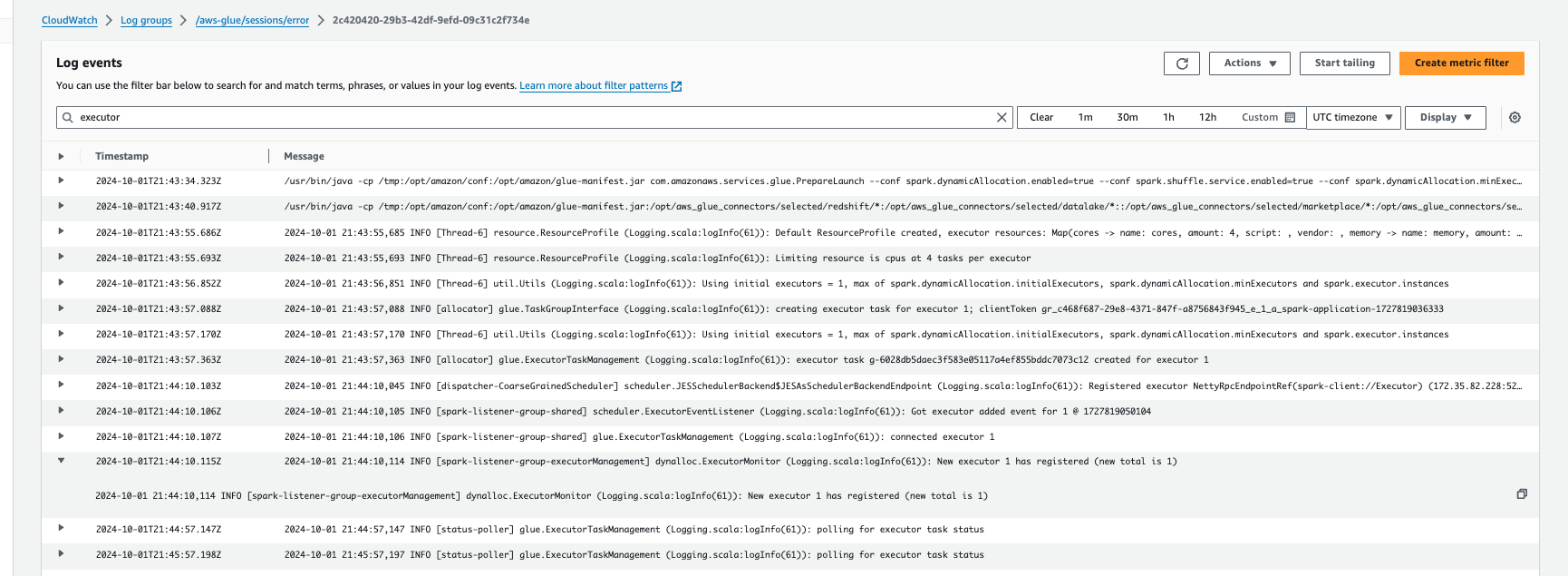
Jika Anda menggunakan sesi interaktif, Anda dapat memantau jumlah pelaksana dengan mengaktifkan CloudWatch Log Amazon berkelanjutan dan mencari “pelaksana” di log, atau dengan menggunakan UI Spark. Untuk melakukan ini, gunakan %%configure sihir untuk mengaktifkan logging terus menerus bersama denganenable auto scaling.
%%configure{ "--enable-continuous-cloudwatch-log": "true", "--enable-auto-scaling": "true" }
Di Amazon CloudWatch Logsevents, cari “eksekusyon"di log:
Memantau Auto Scaling dengan Spark UI
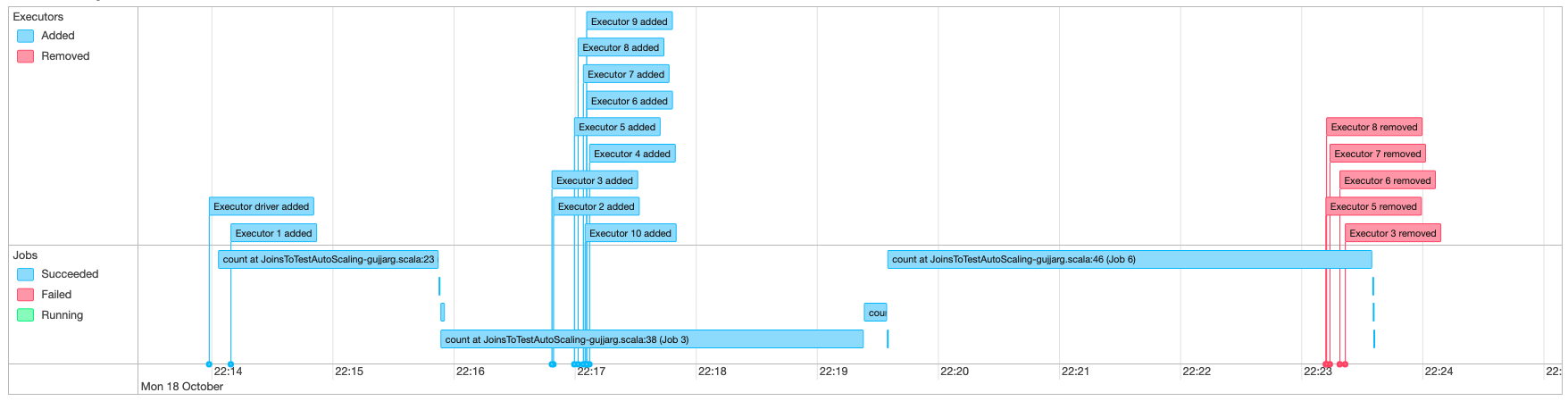
Dengan Auto Scaling diaktifkan, Anda juga dapat memantau pelaksana yang ditambahkan dan dihapus dengan penskalaan dinamis dan penurunan skala berdasarkan permintaan dalam pekerjaan AWS Glue Anda menggunakan UI Glue Spark. Untuk informasi selengkapnya, lihat Mengaktifkan UI web Apache Spark untuk pekerjaan AWS Glue.
Saat Anda menggunakan sesi interaktif dari notebook Jupyter, Anda dapat menjalankan keajaiban berikut untuk mengaktifkan penskalaan otomatis bersama dengan Spark UI:
%%configure{ "--enable-auto-scaling": "true", "--enable-continuous-cloudwatch-log": "true" }
Pemantauan pekerjaan Auto Scaling menjalankan penggunaan DPU
Anda dapat menggunakan tampilan AWS Glue Studio Job run untuk memeriksa penggunaan DPU dari pekerjaan Auto Scaling Anda.
-
Pilih Monitoring dari panel AWS Glue Studio navigasi. Halaman Monitoring muncul.
-
Gulir ke bawah ke bagan Job running.
-
Arahkan ke pekerjaan yang Anda minati dan gulir ke kolom jam DPU untuk memeriksa penggunaan untuk menjalankan pekerjaan tertentu.
Batasan
AWS Gluestreaming Auto Scaling saat ini tidak mendukung DataFrame gabungan streaming dengan statis yang DataFrame dibuat di luar. ForEachBatch Statis yang DataFrame dibuat di dalam ForEachBatch akan berfungsi seperti yang diharapkan.
