Terjemahan disediakan oleh mesin penerjemah. Jika konten terjemahan yang diberikan bertentangan dengan versi bahasa Inggris aslinya, utamakan versi bahasa Inggris.
AWS Glue konsep
AWS Glue adalah layanan ETL (ekstrak, transformasi, muat) yang dikelola sepenuhnya yang memungkinkan Anda memindahkan data dengan mudah antara sumber dan target data yang berbeda. Komponen kuncinya adalah:
-
Katalog Data: Penyimpanan metadata yang berisi definisi tabel, definisi pekerjaan, dan informasi kontrol lainnya untuk alur kerja ETL Anda.
-
Crawler: Program yang terhubung ke sumber data, menyimpulkan skema data, dan membuat definisi tabel metadata di Katalog Data.
-
ETL Jobs: Logika bisnis untuk mengekstrak data dari sumber, mengubahnya menggunakan skrip Apache Spark, dan memuatnya ke target.
-
Pemicu: Mekanisme untuk memulai pekerjaan berjalan berdasarkan jadwal atau acara.
Alur kerja tipikal melibatkan:
-
Tentukan sumber dan target data dalam Katalog Data.
-
Gunakan Crawler untuk mengisi Katalog Data dengan metadata tabel dari sumber data.
-
Tentukan pekerjaan ETL dengan skrip transformasi untuk memindahkan dan memproses data.
-
Jalankan pekerjaan sesuai permintaan atau berdasarkan pemicu.
-
Pantau kinerja pekerjaan menggunakan dasbor.
Diagram berikut menunjukkan arsitektur suatu AWS Glue lingkungan.
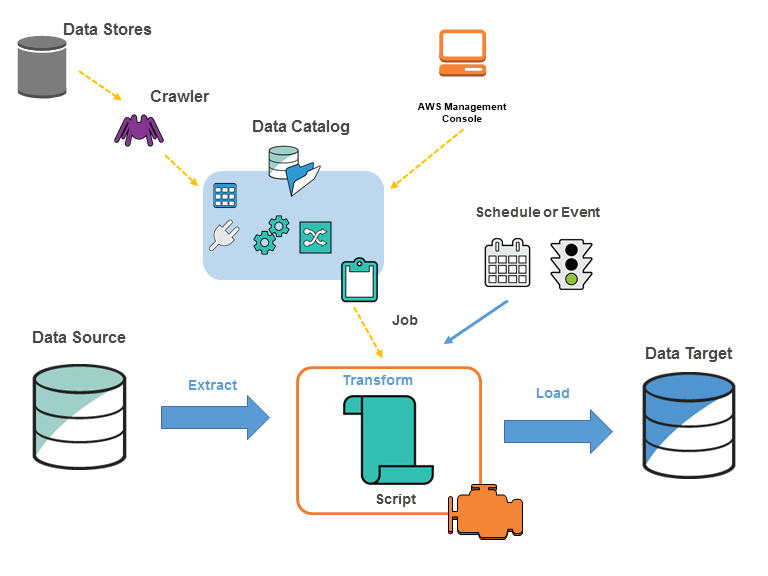
Anda menentukan pekerjaan AWS Glue untuk menyelesaikan pekerjaan yang diperlukan untuk mengekstrak, mengubah, dan memuat data (ETL) dari sumber data ke target data. Anda biasanya akan melakukan tindakan-tindakan berikut:
-
Untuk sumber penyimpanan data, Anda menentukan crawler agar mengisi AWS Glue Data Catalog Anda dengan definisi tabel metadata. Anda mengarahkan crawler Anda di sebuah penyimpanan data, dan crawler menciptakan definisi tabel dalam Katalog Data. Untuk sumber streaming, Anda secara manual menentukan tabel Katalog Data dan menentukan properti aliran data.
Selain definisi tabel, AWS Glue Data Catalog berisi metadata lain yang diperlukan untuk mendefinisikan pekerjaan ETL. Anda menggunakan metadata ini ketika Anda menentukan tugas untuk mengubah data Anda.
AWS Glue dapat menghasilkan skrip untuk mengubah data Anda. Atau, Anda dapat memberikan skrip di AWS Glue konsol atau API.
-
Anda dapat menjalankan tugas Anda sesuai permintaan, atau Anda dapat mengaturnya untuk memulai ketika pemicu yang ditentukan terjadi. Pemicu bisa menjadi jadwal berbasis waktu atau peristiwa.
Saat tugas Anda berjalan, skrip mengekstrak data dari sumber data Anda, mengubah data, dan memasukkannya ke target data Anda. Skrip berjalan di lingkungan Apache Spark di AWS Glue.
penting
Tabel dan database di AWS Glue adalah objek dalam. AWS Glue Data Catalog Mereka berisi metadata; mereka tidak berisi data dari penyimpanan data.
|
Data berbasis teks, seperti CSVs, harus dikodekan agar dapat memprosesnya dengan |
AWS Glue terminologi
AWS Glue bergantung pada interaksi beberapa komponen untuk membuat dan mengelola alur kerja ekstrak, transformasi, dan beban (ETL) Anda.
AWS Glue Data Catalog
Penyimpanan metadata persisten di. AWS Glue Ini berisi definisi tabel, definisi pekerjaan, dan informasi kontrol lainnya untuk mengelola AWS Glue lingkungan Anda. Setiap AWS akun memiliki satu AWS Glue Data Catalog per wilayah.
Pengklasifikasi
Menentukan skema data Anda. AWS Glue menyediakan pengklasifikasi untuk jenis file umum, seperti CSV, JSON, AVRO, XML, dan lainnya. Ia juga menyediakan pengklasifikasi untuk sistem pengelolaan basis data relasional umum dengan menggunakan koneksi JDBC. Anda dapat menulis pengklasifikasi Anda sendiri dengan menggunakan pola grok atau dengan menentukan tag baris dalam sebuah dokumen XML.
Koneksi
Sebuah objek Katalog Data yang berisi properti yang diperlukan untuk connect ke penyimpanan data tertentu.
Crawler
Program yang terhubung ke penyimpanan data (sumber atau target), berlangsung melalui daftar prioritas pengklasifikasi untuk menentukan skema untuk data Anda, dan kemudian membuat tabel metadata di AWS Glue Data Catalog.
Basis Data
Satu set definisi tabel Katalog Data terkait diatur ke dalam grup logis.
Penyimpanan data, sumber data, target data
Sebuah penyimpanan data adalah repositori untuk menyimpan data Anda secara terus-menerus. Contohnya meliputi bucket Amazon S3 dan basis data relasional. Sebuah sumber data adalah penyimpanan data yang digunakan sebagai masukan untuk proses atau transformasi. Sebuah target data adalah penyimpanan data yang padanya dituliskan proses atau transformasi.
Titik akhir pengembangan
Lingkungan yang dapat Anda gunakan untuk mengembangkan dan menguji skrip AWS Glue ETL Anda.
Bingkai Dinamis
Sebuah tabel terdistribusi yang mendukung data bersarang seperti struktur dan rangkaian string. Setiap catatan adalah swa-deskripsi, yang dirancang untuk fleksibilitas skema dengan data semi-terstruktur. Setiap catatan berisi data dan skema yang menggambarkan data tersebut. Anda dapat menggunakan frame dinamis dan Apache Spark DataFrames di skrip ETL Anda, dan mengonversinya. Bingkai dinamis menyediakan satu set transformasi lanjutan untuk pembersihan data dan ETL.
Pekerjaan
Logika bisnis yang diperlukan untuk melakukan tugas ETL. Ia terdiri dari skrip transformasi, sumber data, dan target data. Eksekusi tugas dimulai oleh pemicu yang dapat dijadwalkan atau dipicu oleh peristiwa.
Dasbor performa tugas
AWS Glue menyediakan dasbor run komprehensif untuk pekerjaan ETL Anda. Dasbor menampilkan informasi tentang eksekusi tugas dalam kerangka waktu tertentu.
Antarmuka notebook
Pengalaman notebook yang disempurnakan dengan penyiapan sekali klik untuk memudahkan penulisan pekerjaan dan eksplorasi data. Notebook dan koneksi dikonfigurasi secara otomatis untuk Anda. Anda dapat menggunakan antarmuka notebook berdasarkan Jupyter Notebook untuk mengembangkan, men-debug, dan menyebarkan skrip dan alur kerja secara interaktif menggunakan infrastruktur Apache Spark ETL tanpa server. AWS Glue Anda juga dapat melakukan kueri ad-hoc, analisis data, dan visualisasi (misalnya, tabel dan grafik) di lingkungan notebook.
Skrip
Kode yang mengekstrak data dari sumber, mengubahnya, dan memuatnya menjadi target. AWS Glue menghasilkan PySpark atau skrip Scala.
Tabel
Definisi metadata yang mewakili data Anda. Baik data Anda berada dalam file Amazon Simple Storage Service (Amazon S3), atau tabel Amazon Relational Database Service (Amazon RDS), atau kumpulan data lainnya, tabel mendefinisikan skema data Anda. Sebuah tabel di AWS Glue Data Catalog terdiri dari nama-nama kolom, definisi tipe data, informasi partisi, dan metadata lainnya tentang dataset dasar. Skema data Anda direpresentasikan dalam definisi AWS Glue tabel Anda. Data aktual tetap berada di penyimpanan data aslinya, apakah itu dalam file atau tabel database relasional. AWS Glue katalog file Anda dan tabel database relasional di. AWS Glue Data Catalog Mereka digunakan sebagai sumber dan target ketika Anda membuat tugas ETL.
Transformasi
Logika kode yang digunakan untuk memanipulasi data Anda ke dalam sebuah format yang berbeda.
Pemicu
Memulai tugas ETL. Pemicu dapat didefinisikan berdasarkan waktu yang dijadwalkan atau peristiwa.
Editor tugas visual
Editor pekerjaan visual adalah antarmuka grafis yang memudahkan untuk membuat, menjalankan, dan memantau pekerjaan ekstrak, transformasi, dan pemuatan (ETL) di AWS Glue. Anda dapat menyusun alur kerja transformasi data secara visual, menjalankannya dengan mulus di AWS Glue mesin ETL tanpa server berbasis Apache Spark, dan memeriksa skema dan hasil data di setiap langkah pekerjaan.
Pekerja
Dengan AWS Glue, Anda hanya membayar waktu yang dibutuhkan pekerjaan ETL Anda untuk berjalan. Tidak ada sumber daya untuk dikelola, tidak ada biaya di muka, dan Anda tidak dikenakan biaya untuk waktu startup atau shutdown. Anda dikenakan tarif per jam berdasarkan jumlah Unit Pemrosesan Data (atau DPUs) yang digunakan untuk menjalankan pekerjaan ETL Anda. Satu Data Processing Unit (DPU) juga disebut sebagai pekerja. AWS Glue dilengkapi dengan beberapa jenis pekerja untuk membantu Anda memilih konfigurasi yang memenuhi latensi pekerjaan dan persyaratan biaya Anda. Pekerja datang dalam konfigurasi Standar, G.1X, G.2X, G.4X, G.8X, G.12X, G.16X, G.025X, dan R.1X, R.2X, R.8X yang dioptimalkan untuk memori.
