Terjemahan disediakan oleh mesin penerjemah. Jika konten terjemahan yang diberikan bertentangan dengan versi bahasa Inggris aslinya, utamakan versi bahasa Inggris.
Bagaimana crawler menentukan kapan harus membuat partisi?
Saat sebuah crawler AWS Glue memindai Amazon S3 dan mendeteksi beberapa folder dalam sebuah bucket, ia menentukan akar tabel dalam struktur folder dan folder mana yang merupakan partisi dari sebuah tabel. Nama tabel didasarkan pada prefiks Amazon S3 atau nama folder. Anda memberikan Termasuk path yang mengarahkan ke tingkat folder yang akan di-crawl. Ketika sebagian besar skema pada tingkat folder serupa, crawler tersebut menciptakan partisi dari sebuah tabel bukan tabel terpisah. Untuk mempengaruhi crawler agar membuat tabel terpisah, tambahkan folder akar dari setiap tabel sebagai penyimpanan data terpisah ketika Anda menentukan crawler.
Sebagai contoh, pertimbangkan struktur folder Amazon S3 berikut.
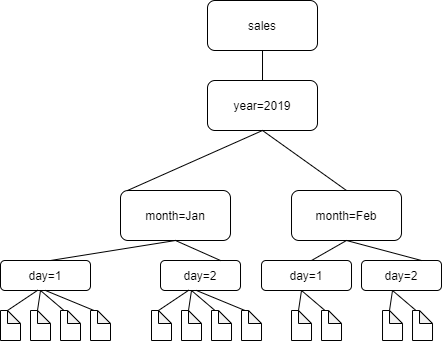
Path ke folder empat tingkat terendah adalah sebagai berikut:
S3://sales/year=2019/month=Jan/day=1 S3://sales/year=2019/month=Jan/day=2 S3://sales/year=2019/month=Feb/day=1 S3://sales/year=2019/month=Feb/day=2
Asumsikan bahwa target crawler ditetapkan pada Sales, dan bahwa semua file dalam folder day=n mempunyai format yang sama (sebagai contoh, JSON, tidak dienkripsi), dan mempunyai skema yang sama atau sangat serupa. Crawler tersebut akan membuat sebuah tabel tunggal dengan empat partisi, dengan kunci partisi year, month, dan day.
Pada contoh selanjutnya, pertimbangkan struktur Amazon S3 berikut:
s3://bucket01/folder1/table1/partition1/file.txt s3://bucket01/folder1/table1/partition2/file.txt s3://bucket01/folder1/table1/partition3/file.txt s3://bucket01/folder1/table2/partition4/file.txt s3://bucket01/folder1/table2/partition5/file.txt
Jika skema untuk file di bawah table1 dan table2 skemanya serupa, dan penyimpanan data tunggal didefinisikan dalam crawler dengan Termasuk path s3://bucket01/folder1/, maka crawler membuat sebuah tabel tunggal dengan dua kolom kunci partisi. Kolom kunci partisi pertama berisi table1 dan table2, dan kolom kunci partisi kedua berisi partition1 hingga partition3 untuk partisi table1 dan partition4 dan partition5 untuk partisi table2. Untuk membuat dua tabel terpisah, tentukan crawler dengan dua penyimpanan data. Dalam contoh ini, tentukan Termasuk path yang pertama sebagai s3://bucket01/folder1/table1/ dan yang kedua sebagai s3://bucket01/folder1/table2.
catatan
Di Amazon Athena, setiap tabel sesuai dengan prefiks Amazon S3 dengan semua objek di dalamnya. Jika objek memiliki skema yang berbeda, maka Athena tidak akan mengenali objek yang berbeda dalam prefiks yang sama sebagai tabel terpisah. Hal ini dapat terjadi jika crawler membuat beberapa tabel dari prefiks Amazon S3 yang sama. Hal ini mungkin menyebabkan kueri di Athena mengembalikan hasil nol. Bagi Athena, untuk dapat mengenali dan meng-kueri tabel dengan benar, buatlah crawler dengan Termasuk path terpisah untuk setiap skema tabel yang berbeda dalam struktur folder Amazon S3. Untuk informasi selengkapnya, lihat Praktik Terbaik Saat Menggunakan Athena dengan AWS Glue dan Artikel Pusat Pengetahuan AWS
