Terjemahan disediakan oleh mesin penerjemah. Jika konten terjemahan yang diberikan bertentangan dengan versi bahasa Inggris aslinya, utamakan versi bahasa Inggris.
Debugging pengecualian OOM dan kelainan pekerjaan
Anda dapat men-debug pengecualian out-of-memory (OOM) dan kelainan pekerjaan di AWS Glue. Bagian berikut menjelaskan skenario untuk debugging out-of-memory pengecualian driver Apache Spark atau pelaksana Spark.
Mendebug pengecualian OOM driver
Dalam skenario ini, sebuah tugas Spark membaca sejumlah besar file dalam ukuran kecil dari Amazon Simple Storage Service (Amazon S3). Ia mengkonversi file tersebut ke format Apache Parquet dan kemudian menulisnya ke Amazon S3. Driver Spark sedang kehabisan memori. Data input Amazon S3 memiliki lebih dari 1 juta file dalam partisi Amazon S3 yang berbeda.
Kode profilannya adalah sebagai berikut:
data = spark.read.format("json").option("inferSchema", False).load("s3://input_path") data.write.format("parquet").save(output_path)
Visualisasikan metrik yang diprofilkan di konsol AWS Glue
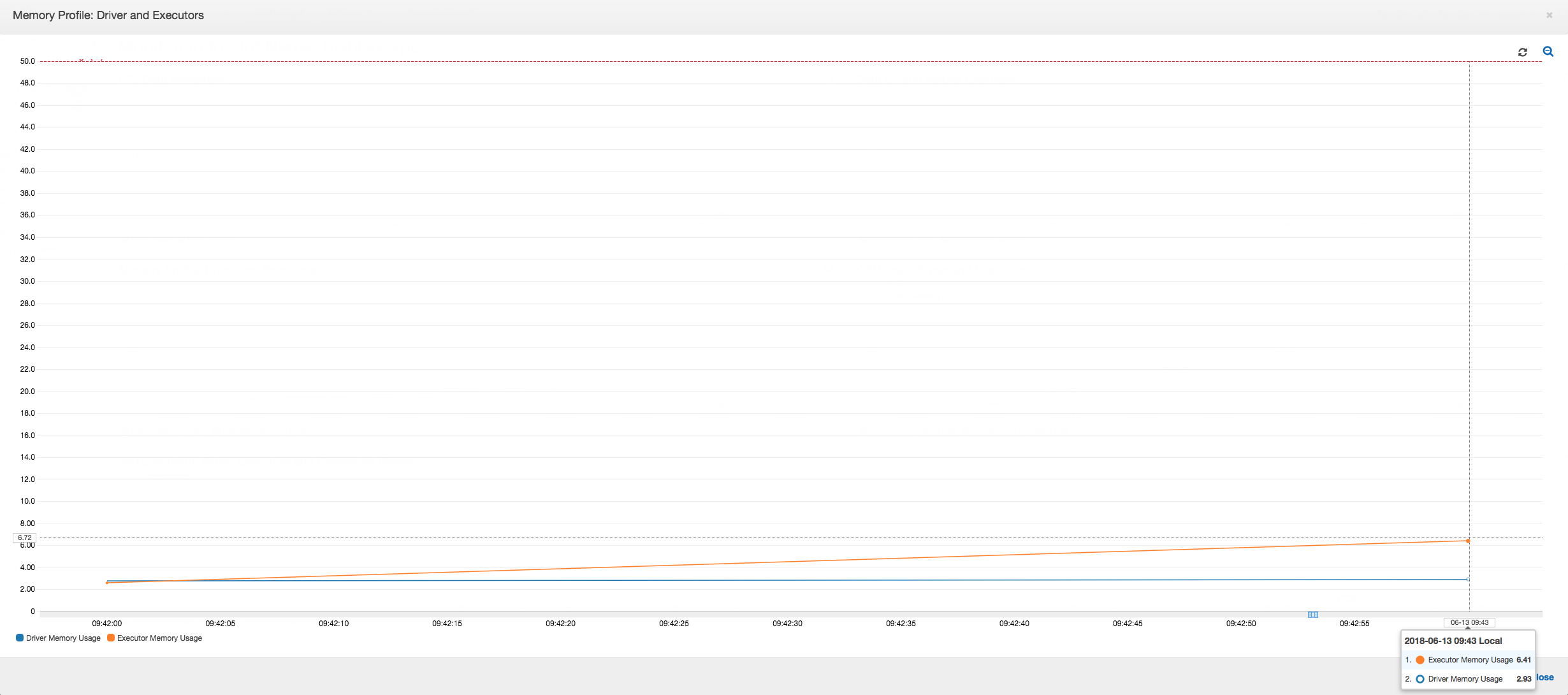
Grafik berikut menunjukkan penggunaan memori dalam satuan persentase untuk driver dan pelaksana. Penggunaan ini diplot sebagai satu titik data yang dirata-ratakan atas nilai-nilai yang dilaporkan di menit terakhir. Anda dapat melihat di profil memori dari tugas bahwa memori driver melewati ambang batas aman penggunaan 50 persen dengan cepat. Di sisi lain, penggunaan memori rata-rata di semua pelaksana masih kurang dari 4 persen. Hal ini jelas menunjukkan kelainan yang terjadi pada pelaksana eksekusi driver dalam tugas Spark ini.
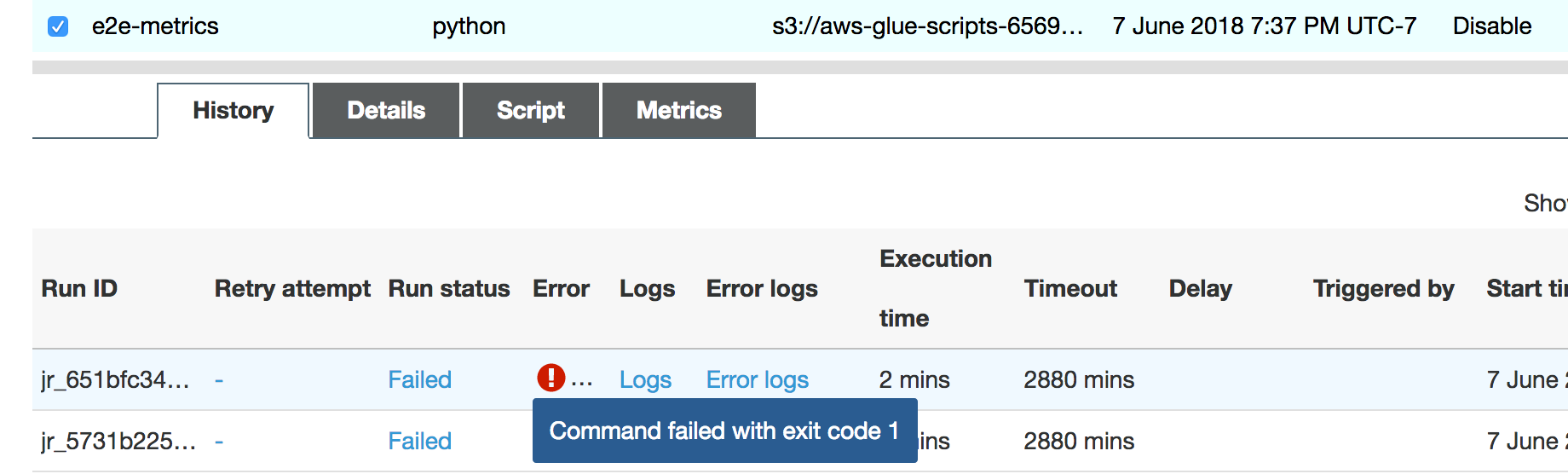
Pekerjaan berjalan segera gagal, dan kesalahan berikut muncul di tab History pada AWS Glue konsol: Perintah Gagal dengan Kode Keluar 1. String kesalahan ini berarti bahwa tugas gagal karena adanya sebuah kesalahan sistemik—yang dalam hal ini adalah bahwa driver kehabisan memori.
Di konsol, pilih tautan Kesalahan log pada tab Sejarah untuk mengonfirmasi temuan tentang driver OOM dari CloudWatch Log. Cari "Error" di log kesalahan tugas untuk mengonfirmasi bahwa hal itu memang pengecualian OOM yang membuat tugas gagal:
# java.lang.OutOfMemoryError: Java heap space # -XX:OnOutOfMemoryError="kill -9 %p" # Executing /bin/sh -c "kill -9 12039"...
Pada tab Riwayat untuk tugas, pilih Log. Anda dapat menemukan jejak eksekusi driver berikut di CloudWatch Log di awal pekerjaan. Driver Spark mencoba untuk mencantumkan semua file di semua direktori, membangun sebuah InMemoryFileIndex, dan meluncurkan satu tugas setiap file. Hal ini pada gilirannya akan mengakibatkan driver Spark harus mempertahankan sejumlah besar status di memori untuk melacak semua tugas. Ia meng-cache daftar lengkap dari sejumlah besar file untuk indeks dalam memori, yang mengakibatkan driver mengalami OOM.
Perbaiki pemrosesan beberapa file menggunakan pengelompokan
Anda dapat memperbaiki pemrosesan beberapa file dengan menggunakan fitur pengelompokan di AWS Glue. Pengelompokan diaktifkan secara otomatis ketika Anda menggunakan frame dinamis dan ketika dataset input memiliki sejumlah besar file (lebih dari 50.000). Pengelompokan dalam grup memungkinkan Anda untuk menggabungkan beberapa file bersama-sama ke dalam sebuah grup, dan memungkinkan tugas untuk memproses seluruh grup tersebut, alih-alih satu file. Akibatnya, driver Spark menyimpan jauh lebih sedikit status di memori untuk melacak lebih sedikit tugas. Untuk informasi lebih lanjut tentang pengaktifan pengelompokan data dalam grup secara manual, lihat Membaca file input dalam kelompok yang lebih besar.
Untuk memeriksa profil memori AWS Glue job, profil kode berikut dengan pengelompokan diaktifkan:
df = glueContext.create_dynamic_frame_from_options("s3", {'paths': ["s3://input_path"], "recurse":True, 'groupFiles': 'inPartition'}, format="json") datasink = glueContext.write_dynamic_frame.from_options(frame = df, connection_type = "s3", connection_options = {"path": output_path}, format = "parquet", transformation_ctx = "datasink")
Anda dapat memantau profil memori dan pergerakan data ETL di AWS Glue profil pekerjaan.
Pengemudi berjalan di bawah ambang batas penggunaan memori 50 persen selama seluruh durasi AWS Glue pekerjaan. Pelaksana mengalirkan data dari Amazon S3, memprosesnya, dan menuliskan data tersebut ke Amazon S3. Akibatnya, mereka menggunakan memori kurang dari 5 persen pada setiap titik waktu.
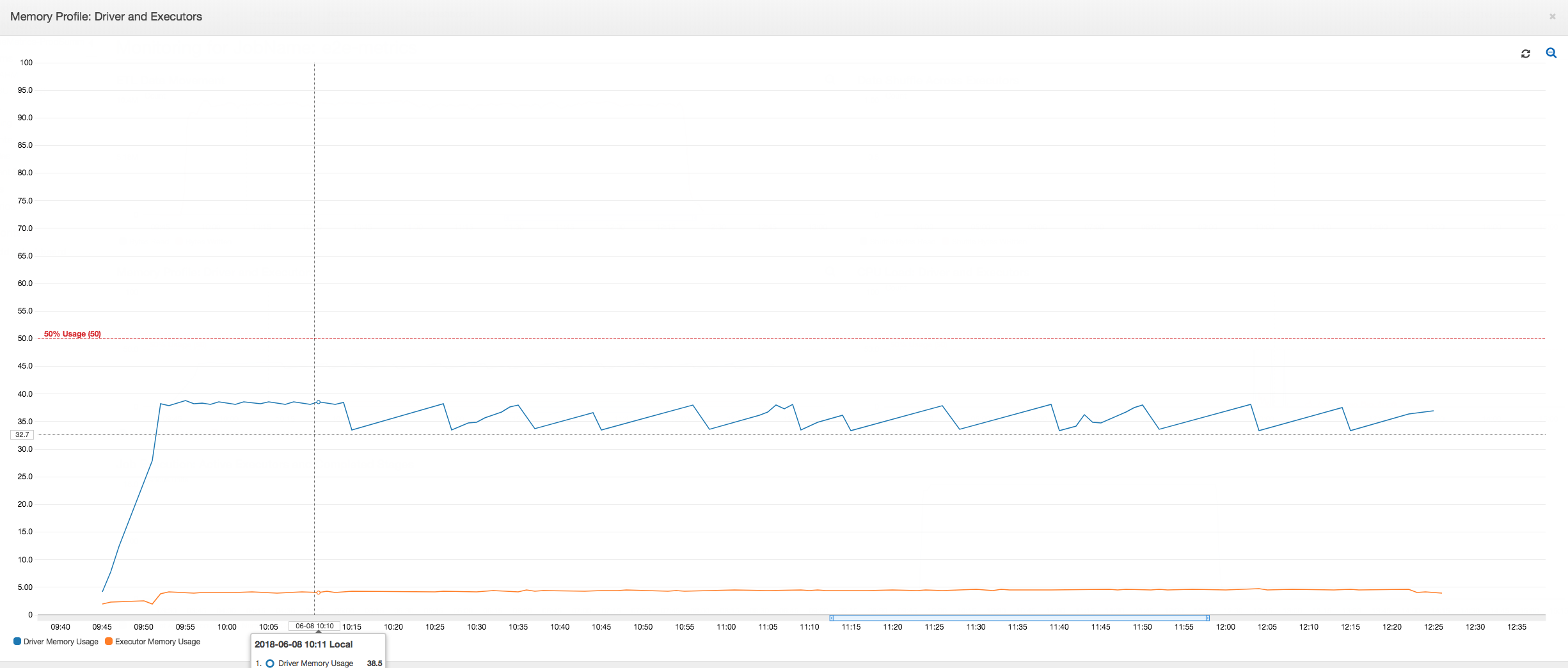
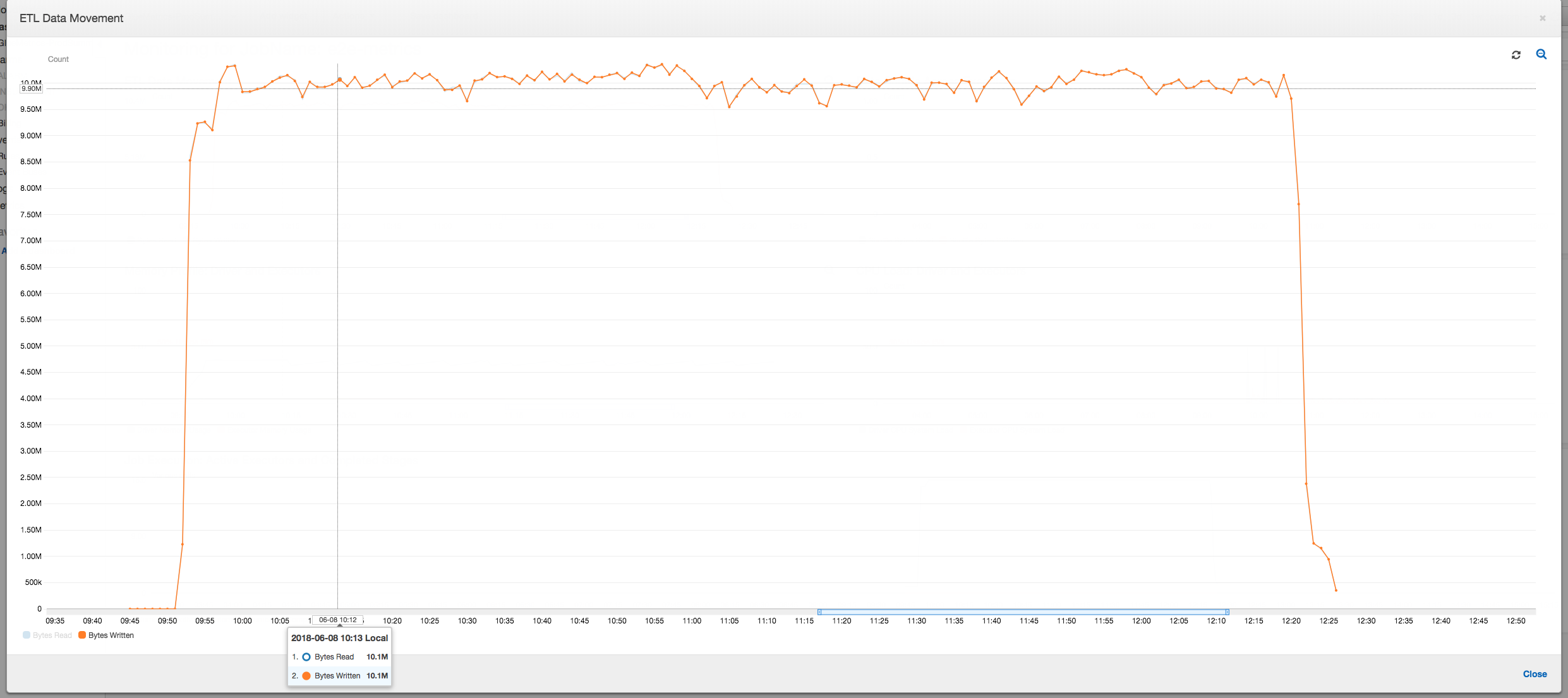
Profil pergerakan data di bawah ini menunjukkan jumlah byte Amazon S3 yang di-baca dan di-tulis pada menit terakhir oleh semua pelaksana saat tugas berlangsung. Keduanya mengikuti pola yang sama karena data dialirkan di semua pelaksana. Tugas tersebut menyelesaikan proses satu juta file dalam waktu kurang dari tiga jam.
Mendebug pengecualian OOM eksekutor
Dalam skenario ini, Anda dapat belajar bagaimana melakukan debug pada pengecualian OOM yang dapat terjadi dalam pelaksana Apache Spark. Kode berikut menggunakan pembaca Spark MySQL untuk membaca tabel besar yang mempunyai sekitar 34 juta baris ke dataframe Spark. Ia kemudian tulis tabel tersebut ke Amazon S3 dalam format Parquet. Anda dapat memberikan properti koneksi dan menggunakan konfigurasi Spark default untuk membaca tabel tersebut.
val connectionProperties = new Properties() connectionProperties.put("user", user) connectionProperties.put("password", password) connectionProperties.put("Driver", "com.mysql.jdbc.Driver") val sparkSession = glueContext.sparkSession val dfSpark = sparkSession.read.jdbc(url, tableName, connectionProperties) dfSpark.write.format("parquet").save(output_path)
Visualisasikan metrik yang diprofilkan pada AWS Glue konsol
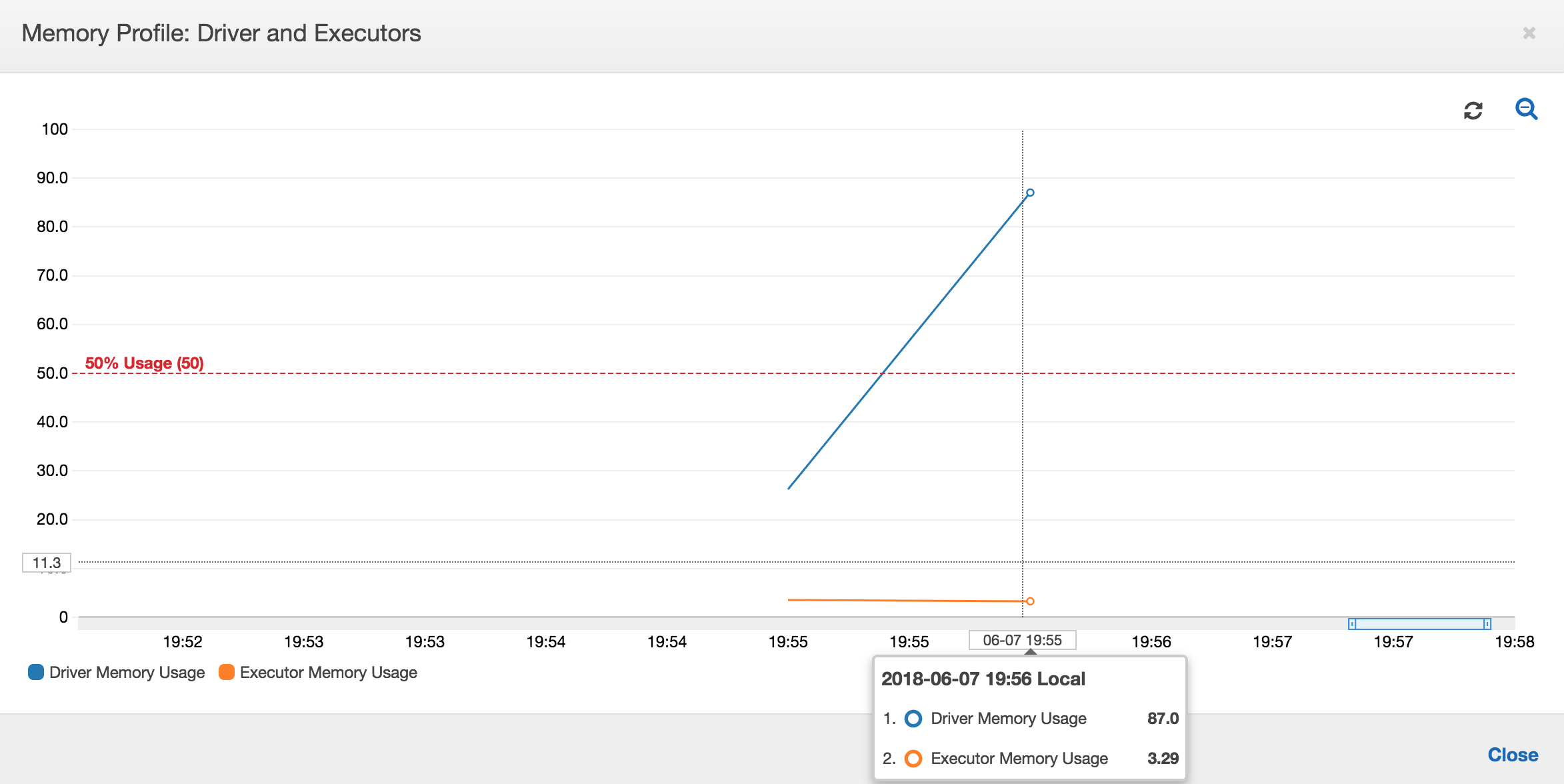
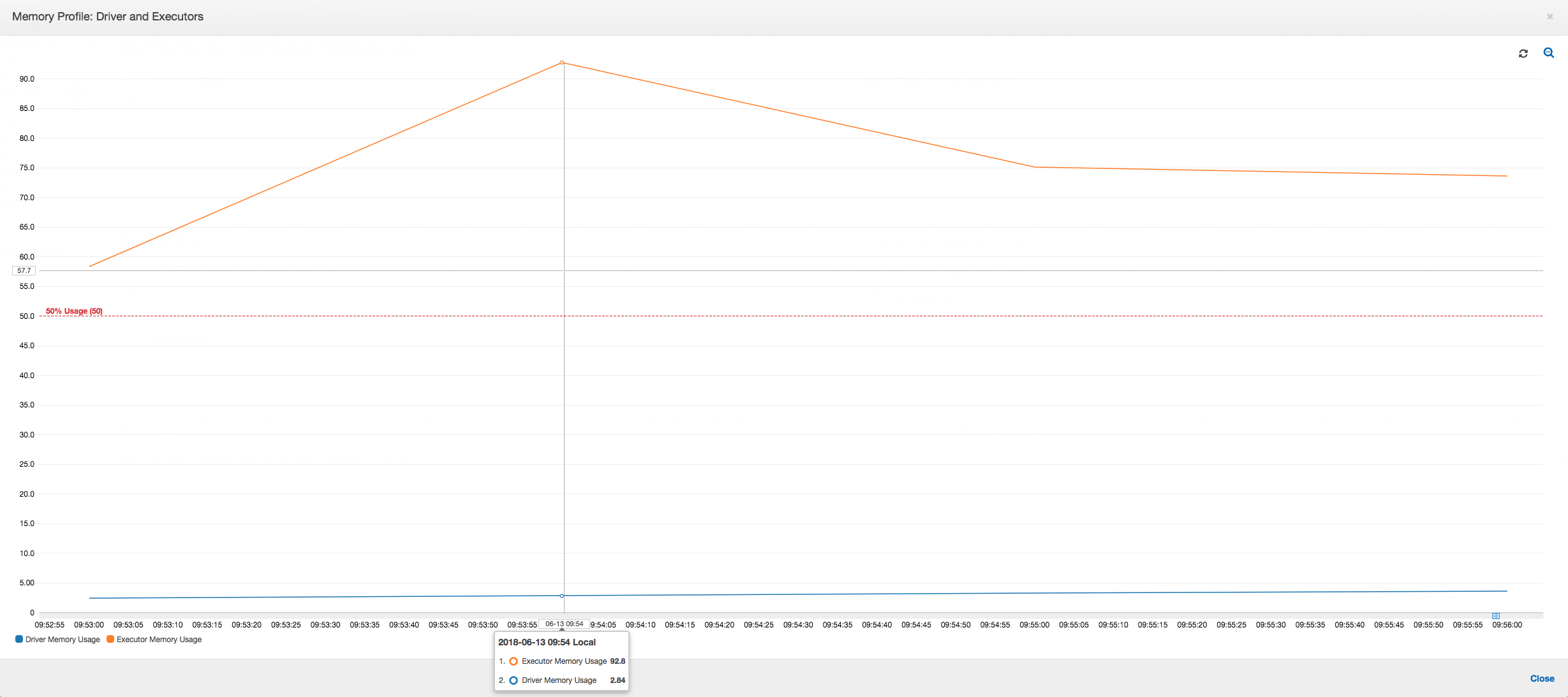
Jika kemiringan grafik penggunaan memori positif dan melewati 50 persen, maka jika tugas gagal sebelum metrik berikutnya dipancarkan, maka kelelahan memori menjadi kandidat yang tepat sebagai penyebabnya. Grafik berikut menunjukkan bahwa dalam satu menit eksekusi, penggunaan memori rata-rata di semua pelaksana melonjak dengan cepat di atas 50 persen. Penggunaan mencapai hingga 92 persen dan kontainer yang menjalankan pelaksana dihentikan oleh Apache Hadoop YARN.
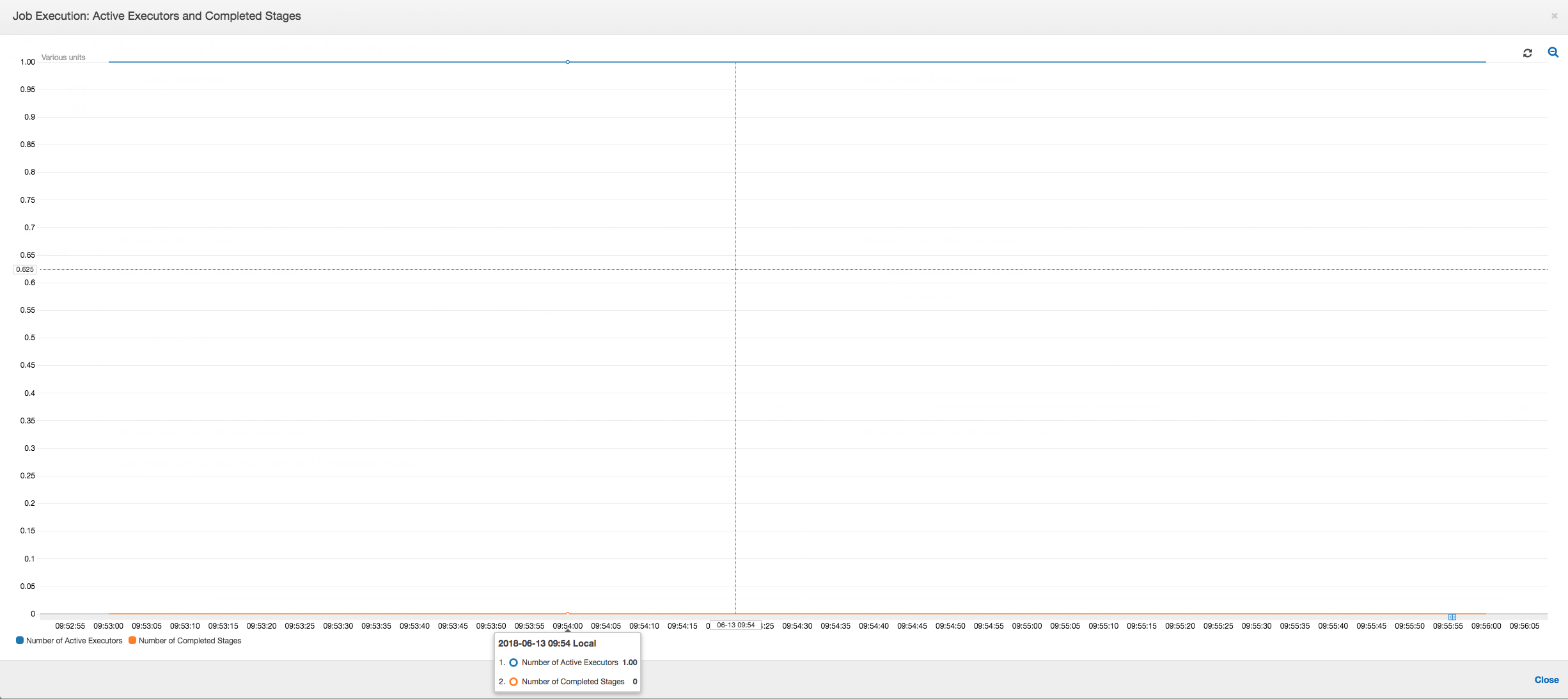
Seperti yang ditunjukkan pada grafik berikut, selalu ada satu pelaksana tunggal yang berjalan sampai tugas gagal. Hal ini karena pelaksana baru diluncurkan untuk menggantikan pelaksana yang dihentikan. Pembacaan sumber data JDBC tidak diparalelisasi secara default karena akan membutuhkan pemartisian tabel pada kolom dan membuka beberapa koneksi. Akibatnya, hanya satu pelaksana yang membaca dalam tabel yang lengkap secara berurutan.
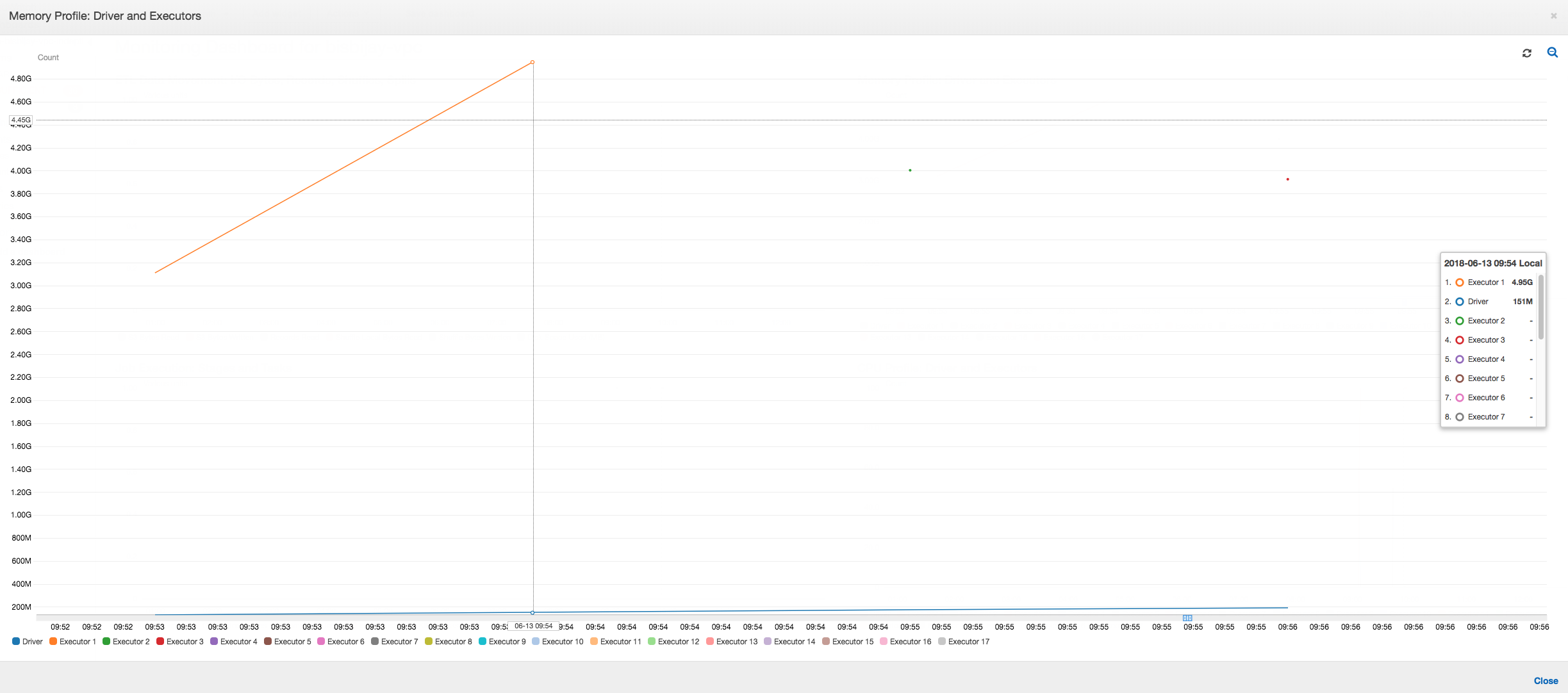
Sebagaimana ditunjukkan dalam grafik berikut, Spark mencoba untuk meluncurkan tugas baru empat kali sebelum gagal tugas. Anda dapat melihat profil memori dari tiga pelaksana. Setiap pelaksana dengan cepat menggunakan semua memorinya. Pelaksana keempat kehabisan memori, dan tugas gagal. Akibatnya, metriknya tidak langsung dilaporkan.
Anda dapat mengonfirmasi dari string kesalahan pada AWS Glue konsol bahwa pekerjaan gagal karena pengecualian OOM, seperti yang ditunjukkan pada gambar berikut.

Log keluaran Job: Untuk mengonfirmasi lebih lanjut temuan Anda tentang pengecualian OOM eksekutor, lihat CloudWatch Log. Saat Anda mencari Error, Anda menemukan empat pelaksana yang dihentikan di sekitar jendela waktu yang sama seperti yang ditunjukkan pada dasbor metrik. Semua diakhiri oleh YARN karena mereka melebihi batas memori mereka.
Pelaksana 1
18/06/13 16:54:29 WARN YarnAllocator: Container killed by YARN for exceeding memory limits. 5.5 GB of 5.5 GB physical memory used. Consider boosting spark.yarn.executor.memoryOverhead. 18/06/13 16:54:29 WARN YarnSchedulerBackend$YarnSchedulerEndpoint: Container killed by YARN for exceeding memory limits. 5.5 GB of 5.5 GB physical memory used. Consider boosting spark.yarn.executor.memoryOverhead. 18/06/13 16:54:29 ERROR YarnClusterScheduler: Lost executor 1 on ip-10-1-2-175.ec2.internal: Container killed by YARN for exceeding memory limits. 5.5 GB of 5.5 GB physical memory used. Consider boosting spark.yarn.executor.memoryOverhead. 18/06/13 16:54:29 WARN TaskSetManager: Lost task 0.0 in stage 0.0 (TID 0, ip-10-1-2-175.ec2.internal, executor 1): ExecutorLostFailure (executor 1 exited caused by one of the running tasks) Reason: Container killed by YARN for exceeding memory limits. 5.5 GB of 5.5 GB physical memory used. Consider boosting spark.yarn.executor.memoryOverhead.
Pelaksana 2
18/06/13 16:55:35 WARN YarnAllocator: Container killed by YARN for exceeding memory limits. 5.8 GB of 5.5 GB physical memory used. Consider boosting spark.yarn.executor.memoryOverhead. 18/06/13 16:55:35 WARN YarnSchedulerBackend$YarnSchedulerEndpoint: Container killed by YARN for exceeding memory limits. 5.8 GB of 5.5 GB physical memory used. Consider boosting spark.yarn.executor.memoryOverhead. 18/06/13 16:55:35 ERROR YarnClusterScheduler: Lost executor 2 on ip-10-1-2-16.ec2.internal: Container killed by YARN for exceeding memory limits. 5.8 GB of 5.5 GB physical memory used. Consider boosting spark.yarn.executor.memoryOverhead. 18/06/13 16:55:35 WARN TaskSetManager: Lost task 0.1 in stage 0.0 (TID 1, ip-10-1-2-16.ec2.internal, executor 2): ExecutorLostFailure (executor 2 exited caused by one of the running tasks) Reason: Container killed by YARN for exceeding memory limits. 5.8 GB of 5.5 GB physical memory used. Consider boosting spark.yarn.executor.memoryOverhead.
Pelaksana 3
18/06/13 16:56:37 WARN YarnAllocator: Container killed by YARN for exceeding memory limits. 5.8 GB of 5.5 GB physical memory used. Consider boosting spark.yarn.executor.memoryOverhead. 18/06/13 16:56:37 WARN YarnSchedulerBackend$YarnSchedulerEndpoint: Container killed by YARN for exceeding memory limits. 5.8 GB of 5.5 GB physical memory used. Consider boosting spark.yarn.executor.memoryOverhead. 18/06/13 16:56:37 ERROR YarnClusterScheduler: Lost executor 3 on ip-10-1-2-189.ec2.internal: Container killed by YARN for exceeding memory limits. 5.8 GB of 5.5 GB physical memory used. Consider boosting spark.yarn.executor.memoryOverhead. 18/06/13 16:56:37 WARN TaskSetManager: Lost task 0.2 in stage 0.0 (TID 2, ip-10-1-2-189.ec2.internal, executor 3): ExecutorLostFailure (executor 3 exited caused by one of the running tasks) Reason: Container killed by YARN for exceeding memory limits. 5.8 GB of 5.5 GB physical memory used. Consider boosting spark.yarn.executor.memoryOverhead.
Pelaksana 4
18/06/13 16:57:18 WARN YarnAllocator: Container killed by YARN for exceeding memory limits. 5.5 GB of 5.5 GB physical memory used. Consider boosting spark.yarn.executor.memoryOverhead. 18/06/13 16:57:18 WARN YarnSchedulerBackend$YarnSchedulerEndpoint: Container killed by YARN for exceeding memory limits. 5.5 GB of 5.5 GB physical memory used. Consider boosting spark.yarn.executor.memoryOverhead. 18/06/13 16:57:18 ERROR YarnClusterScheduler: Lost executor 4 on ip-10-1-2-96.ec2.internal: Container killed by YARN for exceeding memory limits. 5.5 GB of 5.5 GB physical memory used. Consider boosting spark.yarn.executor.memoryOverhead. 18/06/13 16:57:18 WARN TaskSetManager: Lost task 0.3 in stage 0.0 (TID 3, ip-10-1-2-96.ec2.internal, executor 4): ExecutorLostFailure (executor 4 exited caused by one of the running tasks) Reason: Container killed by YARN for exceeding memory limits. 5.5 GB of 5.5 GB physical memory used. Consider boosting spark.yarn.executor.memoryOverhead.
Perbaiki pengaturan ukuran ambil menggunakan AWS Glue bingkai dinamis
Pelaksana kehabisan memori saat membaca tabel JDBC karena konfigurasi default untuk ukuran pengambilan JDBC Spark adalah nol. Ini berarti bahwa driver JDBC pada pelaksana Spark mencoba untuk mengambil 34 juta baris dari basis data bersama-sama dan meng-cache mereka, meskipun pengaliran Spark melalui baris-baris tersebut, sekali dalam satu waktu. Dengan Spark, Anda dapat menghindari skenario ini dengan menetapkan parameter ukuran pengambilan ke nilai default non-nol.
Anda juga dapat memperbaiki masalah ini dengan menggunakan AWS Glue bingkai dinamis sebagai gantinya. Secara default, bingkai dinamis menggunakan ukuran pengambilan sebesar 1.000 baris yang merupakan nilai yang biasanya cukup. Akibatnya, pelaksana tidak mengambil lebih dari 7 persen dari total memorinya. Bagian AWS Glue pekerjaan selesai dalam waktu kurang dari dua menit dengan hanya satu eksekutor. Saat menggunakan AWS Glue frame dinamis adalah pendekatan yang disarankan, juga dimungkinkan untuk mengatur ukuran fetch menggunakan properti Apache Sparkfetchsize. Lihat Spark SQL, DataFrames dan Panduan Datasets
val (url, database, tableName) = { ("jdbc_url", "db_name", "table_name") } val source = glueContext.getSource(format, sourceJson) val df = source.getDynamicFrame glueContext.write_dynamic_frame.from_options(frame = df, connection_type = "s3", connection_options = {"path": output_path}, format = "parquet", transformation_ctx = "datasink")
Metrik profil normal: Memori pelaksana dengan AWS Glue frame dinamis tidak pernah melebihi ambang batas aman, seperti yang ditunjukkan pada gambar berikut. Ia mengalirkan dalam baris-baris dari basis data dan meng-cache hanya 1.000 baris dalam driver JDBC pada setiap titik waktu. Pengecualian kehabisan memori tidak terjadi.