Terjemahan disediakan oleh mesin penerjemah. Jika konten terjemahan yang diberikan bertentangan dengan versi bahasa Inggris aslinya, utamakan versi bahasa Inggris.
Mendebug tahapan yang menuntut dan tugas yang menyimpang
Anda dapat menggunakan AWS Glue pembuatan profil pekerjaan untuk mengidentifikasi tahapan yang menuntut dan tugas yang menyimpang dalam pekerjaan ekstrak, transformasi, dan pemuatan (ETL) Anda. Tugas yang menyimpang membutuhkan waktu lebih lama daripada tugas-tugas lainnya dalam tahap AWS Glue pekerjaan. Akibatnya, tahapan tersebut membutuhkan waktu lebih lama untuk selesai, yang juga menunda total waktu eksekusi tugas.
Menggabungkan file input kecil menjadi file output yang lebih besar
Sebuah tugas dengan performa buruk dapat terjadi ketika ada distribusi pekerjaan yang tidak seragam di seluruh tugas yang berbeda, atau adanya data condong yang mengakibatkan satu tugas memproses lebih banyak data.
Anda dapat melakukan pemrofilan pada kode berikut—pola umum di Apache Spark—untuk menggabungkan sejumlah besar file kecil ke dalam file output yang lebih besar. Untuk contoh ini, set data inputnya adalah file JSON Gzip terkompresi sebesar 32 GB. Set data output mempunyai file JSON tidak terkompresi kira-kira sebesar 190 GB.
Kode profilannya adalah sebagai berikut:
datasource0 = spark.read.format("json").load("s3://input_path") df = datasource0.coalesce(1) df.write.format("json").save(output_path)
Visualisasikan metrik yang diprofilkan pada AWS Glue konsol
Anda dapat melakukan pemrofilan pada tugas Anda untuk memeriksa empat rangkaian metrik yang berbeda:
-
Pergerakan data ETL
-
Data yang diacak di seluruh pelaksana
-
Eksekusi tugas
-
Profil memori
Pergerakan data ETL: Dalam profil Pergerakan data ETL, byte di-baca cukup cepat oleh semua pelaksana di tahap pertama yang selesai dalam waktu enam menit pertama. Namun, total waktu eksekusi tugas sekitar satu jam, sebagian besar terdiri dari eksekusi tulis data.

Data yang diacak di seluruh pelaksana: Jumlah byte yang di-baca dan di-tulis selama pengacakan juga menunjukkan lonjakan sebelum Tahap 2 berakhir, seperti yang ditunjukkan oleh metrik Eksekusi Tugas dan Pengacakan Data. Setelah pengacakan data dilakukan di semua pelaksana, baca dan tulis melanjutkan dari pelaksana nomor 3 saja.

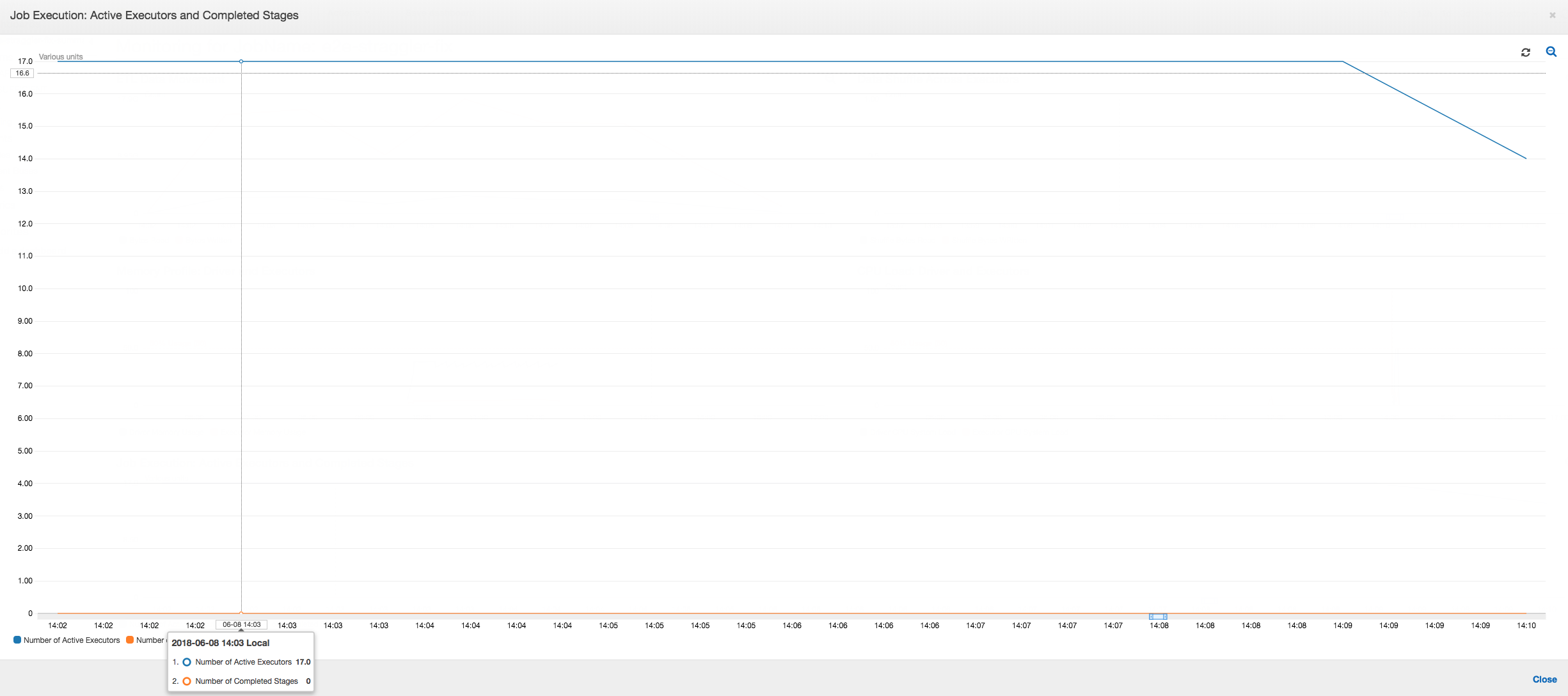
Eksekusi Tugas: Seperti ditunjukkan pada grafik di bawah ini, semua pelaksana lainnya menganggur dan akhirnya dilepaskan pada waktu 10:09. Pada saat itu, jumlah total pelaksana menurun menjadi hanya satu saja. Hal ini jelas menunjukkan bahwa pelaksana nomor 3 terdiri dari tugas dengan performa buruk yang mengambil waktu eksekusi paling lama dan memberikan kontribusi untuk sebagian besar waktu eksekusi tugas.

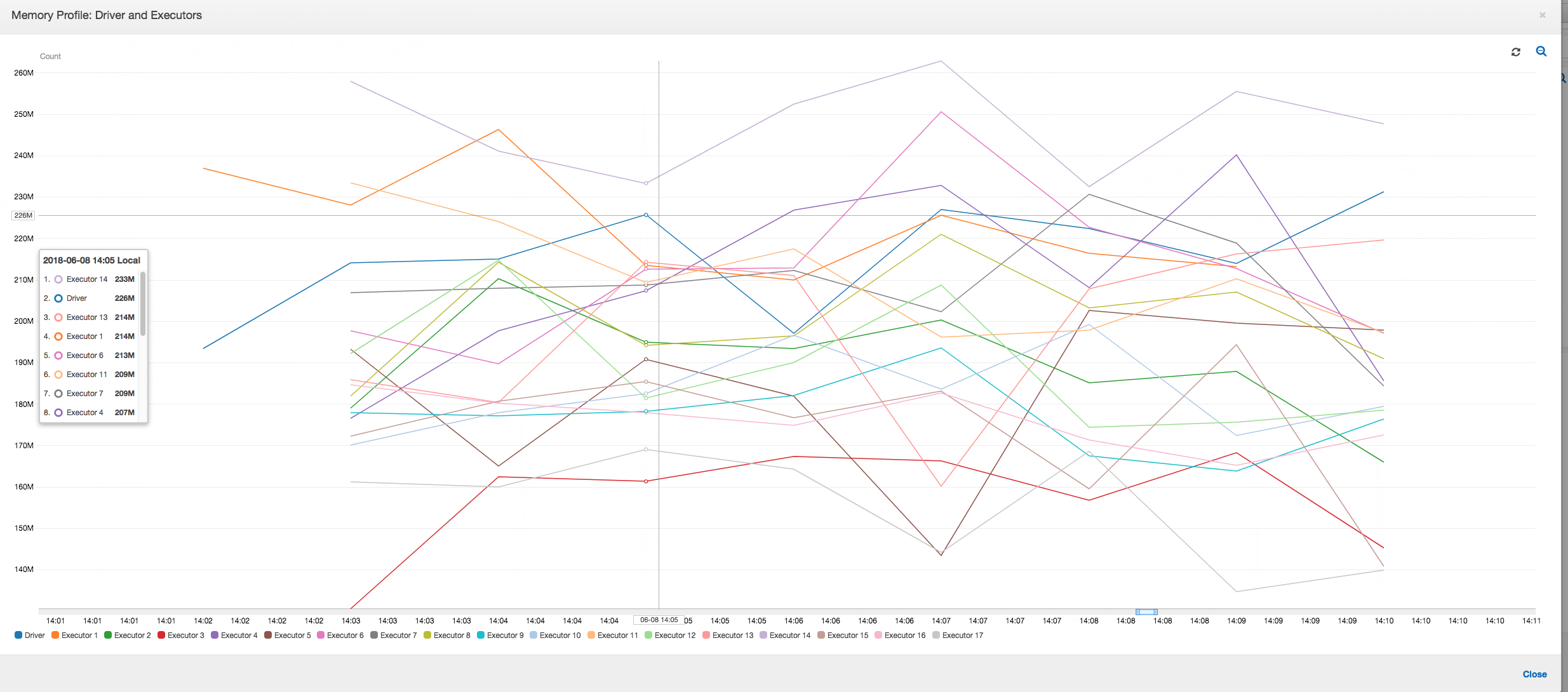
Profil memori: Setelah dua tahap pertama, hanya pelaksana nomor 3 yang secara aktif menggunakan memori untuk memproses data. Pelaksana yang tersisa hanya menganggur atau telah dilepaskan tak lama setelah dua tahap pertama selesai.

Perbaiki pelaksana yang tersesat menggunakan pengelompokan
Anda dapat menghindari pelaksana yang tersesat dengan menggunakan fitur pengelompokan di AWS Glue. Gunakan pengelompokan untuk mendistribusikan data secara seragam di semua pelaksana dan menggabungkan file menjadi file yang lebih besar menggunakan semua pelaksana yang tersedia di cluster. Untuk informasi selengkapnya, lihat Membaca file input dalam kelompok yang lebih besar.
Untuk memeriksa pergerakan data ETL di AWS Glue job, profil kode berikut dengan pengelompokan diaktifkan:
df = glueContext.create_dynamic_frame_from_options("s3", {'paths': ["s3://input_path"], "recurse":True, 'groupFiles': 'inPartition'}, format="json") datasink = glueContext.write_dynamic_frame.from_options(frame = df, connection_type = "s3", connection_options = {"path": output_path}, format = "json", transformation_ctx = "datasink4")
Pergerakan data ETL: Data tulis sekarang dialirkan secara paralel dengan data baca di sepanjang waktu eksekusi tugas. Akibatnya, tugas selesai dalam delapan menit—jauh lebih cepat dari sebelumnya.

Data yang diacak di seluruh pelaksana: Karena file input digabungkan selama baca menggunakan fitur pengelompokan dalam grup, tidak ada pengacakan data yang mahal setelah pembacaan data.

Eksekusi tugas: Metrik eksekusi tugas menunjukkan bahwa jumlah pelaksana aktif yang menjalankan dan memproses data masih tetap cukup konstan. Tidak ada performa buruk yang terjadi dalam tugas itu. Semua pelaksana aktif dan tidak dilepaskan sampai tugas selesai. Karena tidak ada pengacakan menengah pada data di seluruh pelaksana, maka hanya ada satu tahap dalam tugas tersebut.
Profil memori: Metrik menunjukkan konsumsi memori aktif di semua pelaksana—mengonfirmasi kembali bahwa ada aktivitas di semua pelaksana. Karena data dialirkan dan ditulis secara paralel, maka total jejak memori dari semua pelaksana kira-kira seragam dan jauh di bawah ambang batas aman untuk semua pelaksana.