Terjemahan disediakan oleh mesin penerjemah. Jika konten terjemahan yang diberikan bertentangan dengan versi bahasa Inggris aslinya, utamakan versi bahasa Inggris.
Tutorial: Bangun beban kerja streaming pertama Anda menggunakan notebook AWS Glue Studio
Dalam tutorial ini, Anda akan mengeksplorasi cara memanfaatkan notebook AWS Glue Studio untuk secara interaktif membangun dan menyempurnakan pekerjaan ETL Anda untuk pemrosesan data mendekati waktu nyata. Apakah Anda baru AWS Glue atau ingin meningkatkan keahlian Anda, panduan ini akan memandu Anda melalui proses, memberdayakan Anda untuk memanfaatkan potensi penuh notebook sesi AWS Glue interaktif.
Dengan AWS Glue Streaming, Anda dapat membuat pekerjaan ekstrak, transformasi, dan pemuatan streaming (ETL) yang berjalan terus menerus dan mengkonsumsi data dari sumber streaming seperti Amazon Kinesis Data Streams, Apache Kafka, dan Amazon Managed Streaming untuk Apache Kafka (Amazon MSK).
Prasyarat
Untuk mengikuti tutorial ini, Anda memerlukan pengguna dengan izin AWS konsol untuk digunakan AWS Glue, Amazon Kinesis, Amazon S3, Amazon Athena,, AWS CloudFormation Lambda AWS , dan Amazon Cognito.
Konsumsi data streaming dari Amazon Kinesis
Topik
Menghasilkan data tiruan dengan Kinesis Data Generator
catatan
Jika Anda telah menyelesaikan kami sebelumnyaTutorial: Bangun beban kerja streaming pertama Anda menggunakan Studio AWS Glue, Anda sudah menginstal Kinesis Data Generator di akun Anda dan Anda dapat melewati langkah 1-8 di bawah ini dan melanjutkan ke bagian. Membuat pekerjaan AWS Glue streaming dengan AWS Glue Studio
Anda dapat secara sintetis menghasilkan data sampel dalam format JSON menggunakan Kinesis Data Generator (KDG). Anda dapat menemukan instruksi dan detail lengkap dalam dokumentasi alat
Untuk memulai, klik

untuk menjalankan AWS CloudFormation template di AWS lingkungan Anda. catatan
Anda mungkin mengalami kegagalan CloudFormation template karena beberapa sumber daya, seperti pengguna Amazon Cognito untuk Kinesis Data Generator sudah ada di akun Anda. AWS Ini bisa jadi karena Anda sudah mengaturnya dari tutorial atau blog lain. Untuk mengatasi hal ini, Anda dapat mencoba template di AWS akun baru untuk awal yang baru, atau menjelajahi AWS Wilayah yang berbeda. Opsi ini memungkinkan Anda menjalankan tutorial tanpa bertentangan dengan sumber daya yang ada.
Template menyediakan aliran data Kinesis dan akun Kinesis Data Generator untuk Anda.
Masukkan Nama Pengguna dan Kata Sandi yang akan digunakan KDG untuk mengautentikasi. Perhatikan nama pengguna dan kata sandi untuk penggunaan lebih lanjut.
Pilih Berikutnya sampai ke langkah terakhir. Mengakui penciptaan sumber daya IAM. Periksa kesalahan apa pun di bagian atas layar, seperti kata sandi yang tidak memenuhi persyaratan minimum, dan gunakan templat.
Arahkan ke tab Output dari tumpukan. Setelah template digunakan, itu akan menampilkan properti KinesisDataGeneratorUrlyang dihasilkan. Klik URL tersebut.
Masukkan Nama Pengguna dan Kata Sandi yang Anda catat.
Pilih Wilayah yang Anda gunakan dan pilih Kinesis Stream
GlueStreamTest-{AWS::AccountId}Masukkan template berikut:
{ "ventilatorid": {{random.number(100)}}, "eventtime": "{{date.now("YYYY-MM-DD HH:mm:ss")}}", "serialnumber": "{{random.uuid}}", "pressurecontrol": {{random.number( { "min":5, "max":30 } )}}, "o2stats": {{random.number( { "min":92, "max":98 } )}}, "minutevolume": {{random.number( { "min":5, "max":8 } )}}, "manufacturer": "{{random.arrayElement( ["3M", "GE","Vyaire", "Getinge"] )}}" }Anda sekarang dapat melihat data tiruan dengan template Uji dan menelan data tiruan ke Kinesis dengan data Kirim.
Klik Kirim data dan hasilkan 5-10K catatan ke Kinesis.
Membuat pekerjaan AWS Glue streaming dengan AWS Glue Studio
AWS Glue Studio adalah antarmuka visual yang menyederhanakan proses merancang, mengatur, dan memantau jaringan pipa integrasi data. Hal ini memungkinkan pengguna untuk membangun pipa transformasi data tanpa menulis kode ekstensif. Terlepas dari pengalaman penulisan pekerjaan visual, AWS Glue Studio juga menyertakan notebook Jupyter yang didukung oleh sesi AWS Glue Interaktif, yang akan Anda gunakan di sisa tutorial ini.
Siapkan pekerjaan sesi interaktif AWS Glue Streaming
Unduh file notebook
yang disediakan dan simpan ke direktori lokal Buka AWS Glue Console dan di panel kiri klik Notebooks > Jupyter Notebook > Upload dan edit notebook yang ada. Unggah buku catatan dari langkah sebelumnya dan klik Buat.
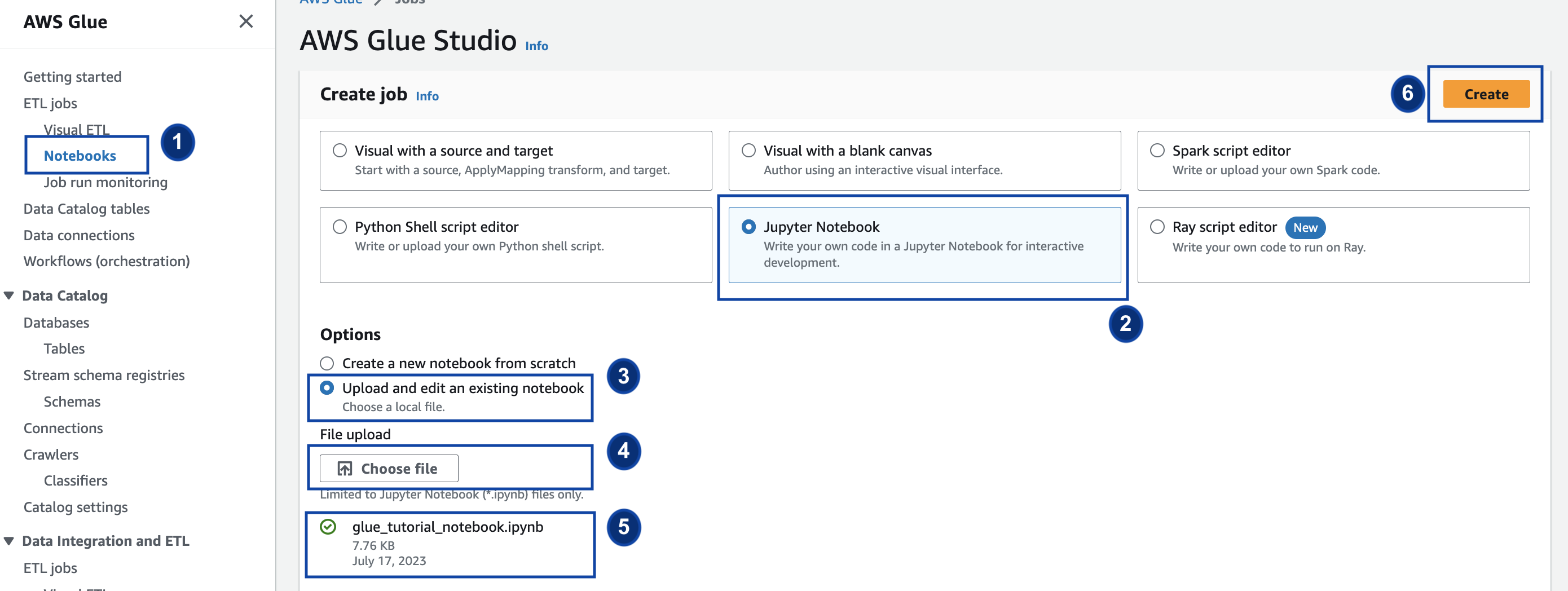
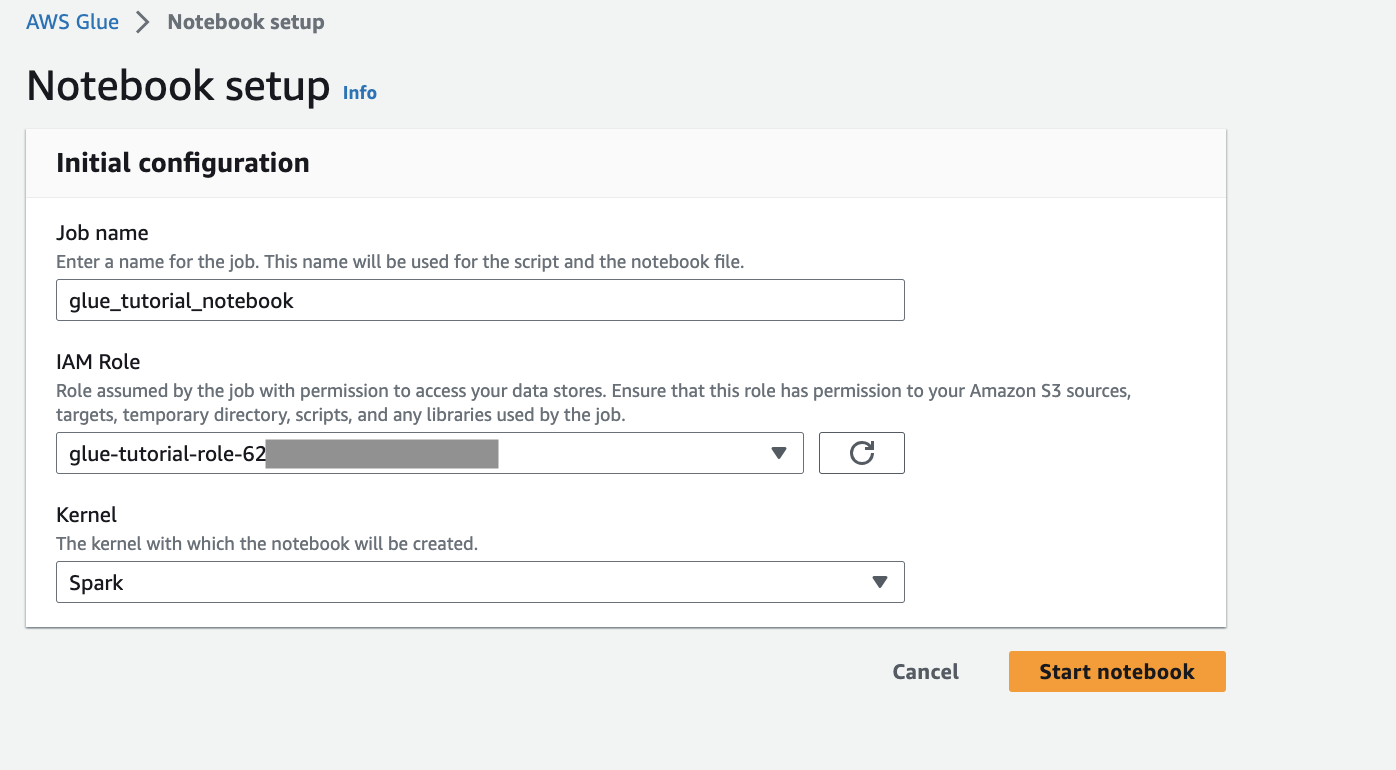
Berikan nama pekerjaan, peran, dan pilih kernel Spark default. Klik berikutnya Mulai notebook. Untuk Peran IAM, pilih peran yang disediakan oleh template. CloudFormation Anda dapat melihat ini di tab Output dari. CloudFormation
Notebook memiliki semua instruksi yang diperlukan untuk melanjutkan tutorial. Anda dapat menjalankan instruksi pada notebook atau mengikuti tutorial ini untuk melanjutkan pengembangan pekerjaan.
Jalankan sel notebook
(Opsional) Sel kode pertama,
%helpmencantumkan semua sihir notebook yang tersedia. Anda dapat melewati sel ini untuk saat ini, tetapi jangan ragu untuk menjelajahinya.Mulailah dengan blok kode berikutnya
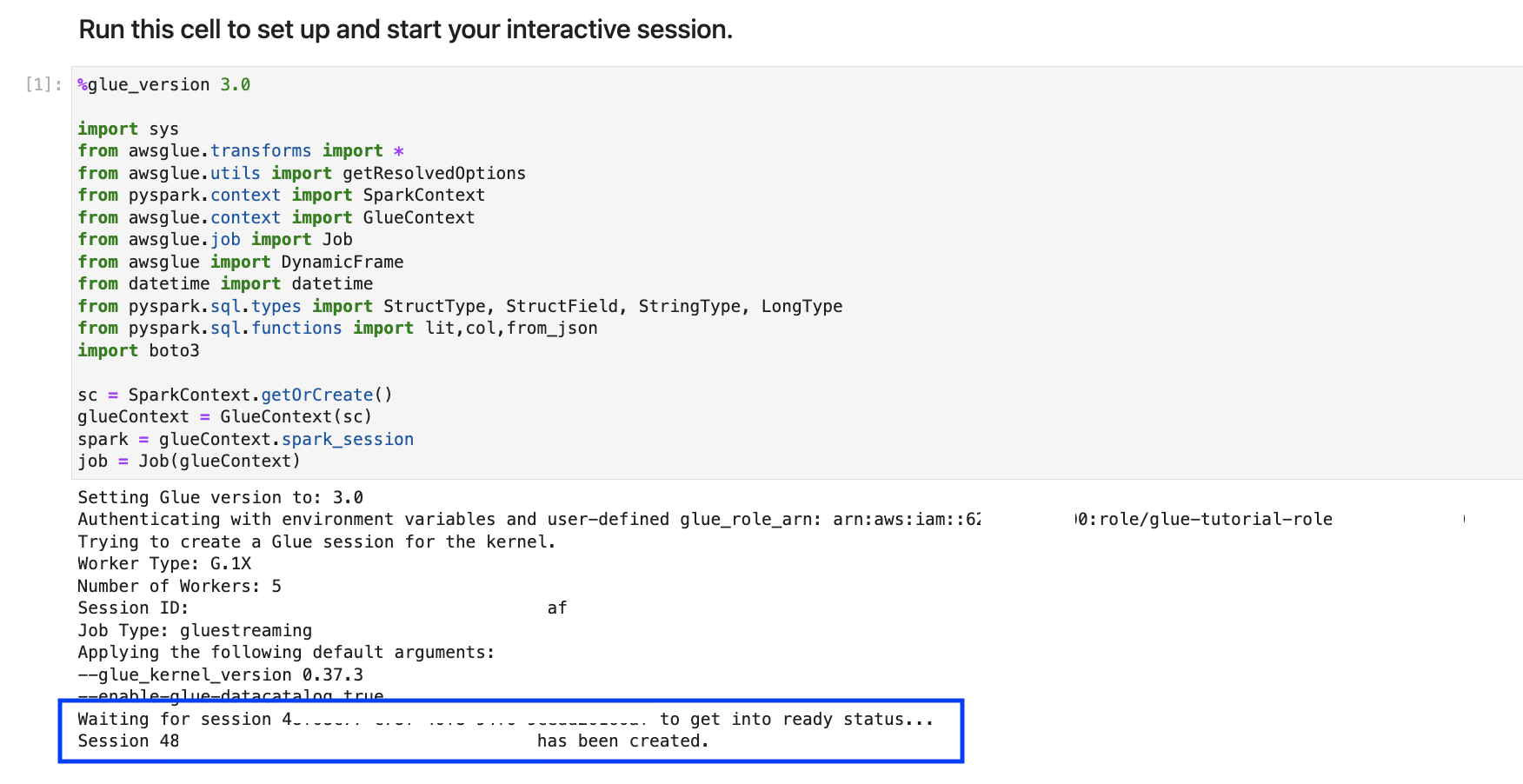
%streaming. Keajaiban ini mengatur jenis pekerjaan ke streaming yang memungkinkan Anda mengembangkan, men-debug, dan menerapkan pekerjaan ETL AWS Glue streaming.Jalankan sel berikutnya untuk membuat sesi AWS Glue interaktif. Sel output memiliki pesan yang mengonfirmasi pembuatan sesi.
Sel berikutnya mendefinisikan variabel. Ganti nilai dengan yang sesuai dengan pekerjaan Anda dan jalankan sel. Misalnya:

Karena data sudah dialirkan ke Kinesis Data Streams, sel Anda berikutnya akan mengkonsumsi hasil dari aliran. Jalankan sel berikutnya. Karena tidak ada pernyataan cetak, tidak ada output yang diharapkan dari sel ini.
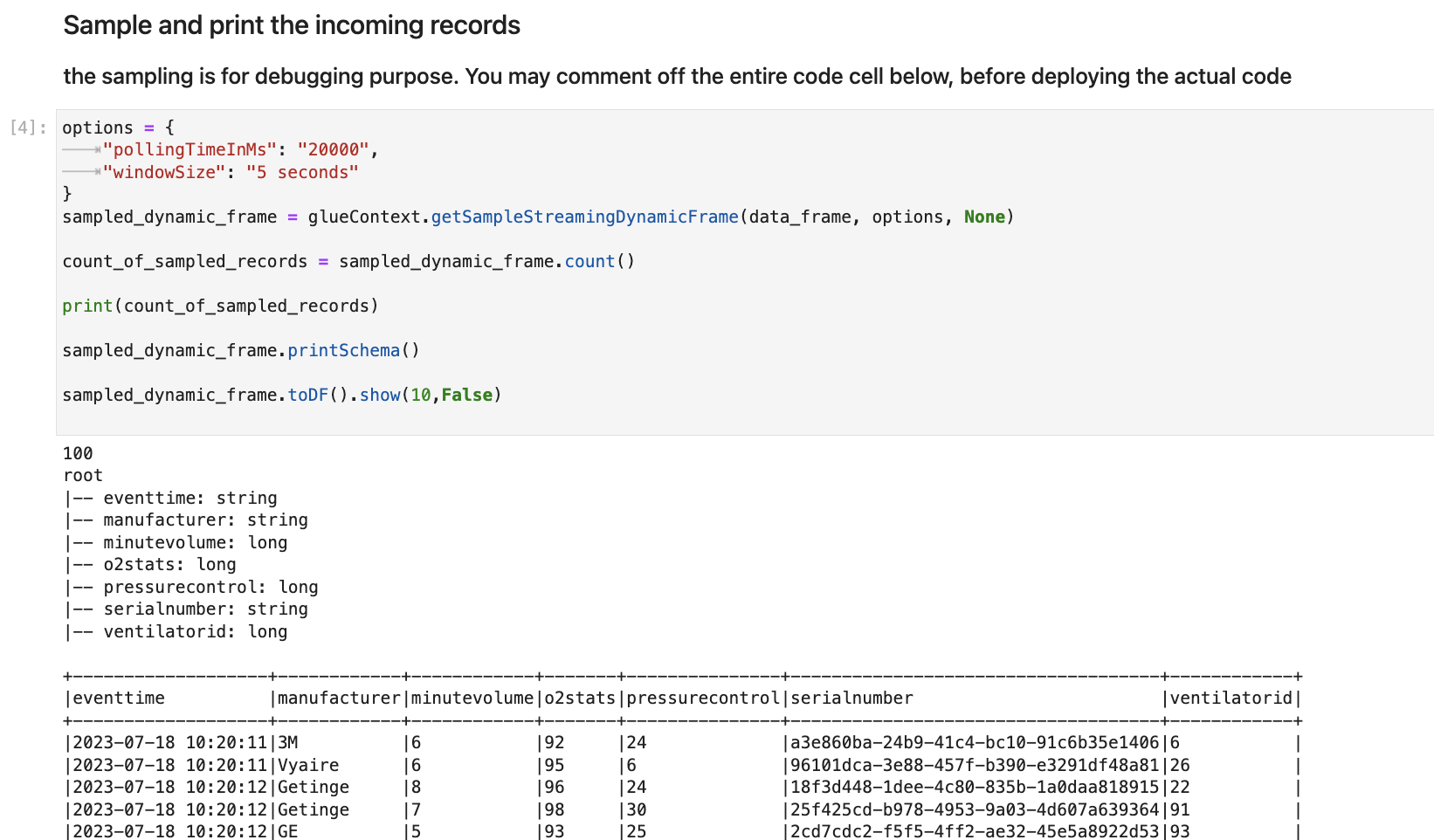
Di sel berikut, Anda menjelajahi aliran masuk dengan mengambil kumpulan sampel dan mencetak skema dan data aktualnya. Misalnya:
Selanjutnya, tentukan logika transformasi data aktual. Sel terdiri dari
processBatchmetode yang dipicu selama setiap batch mikro. Jalankan sel. Pada tingkat tinggi, kami melakukan hal berikut ke aliran masuk:Pilih subset dari kolom input.
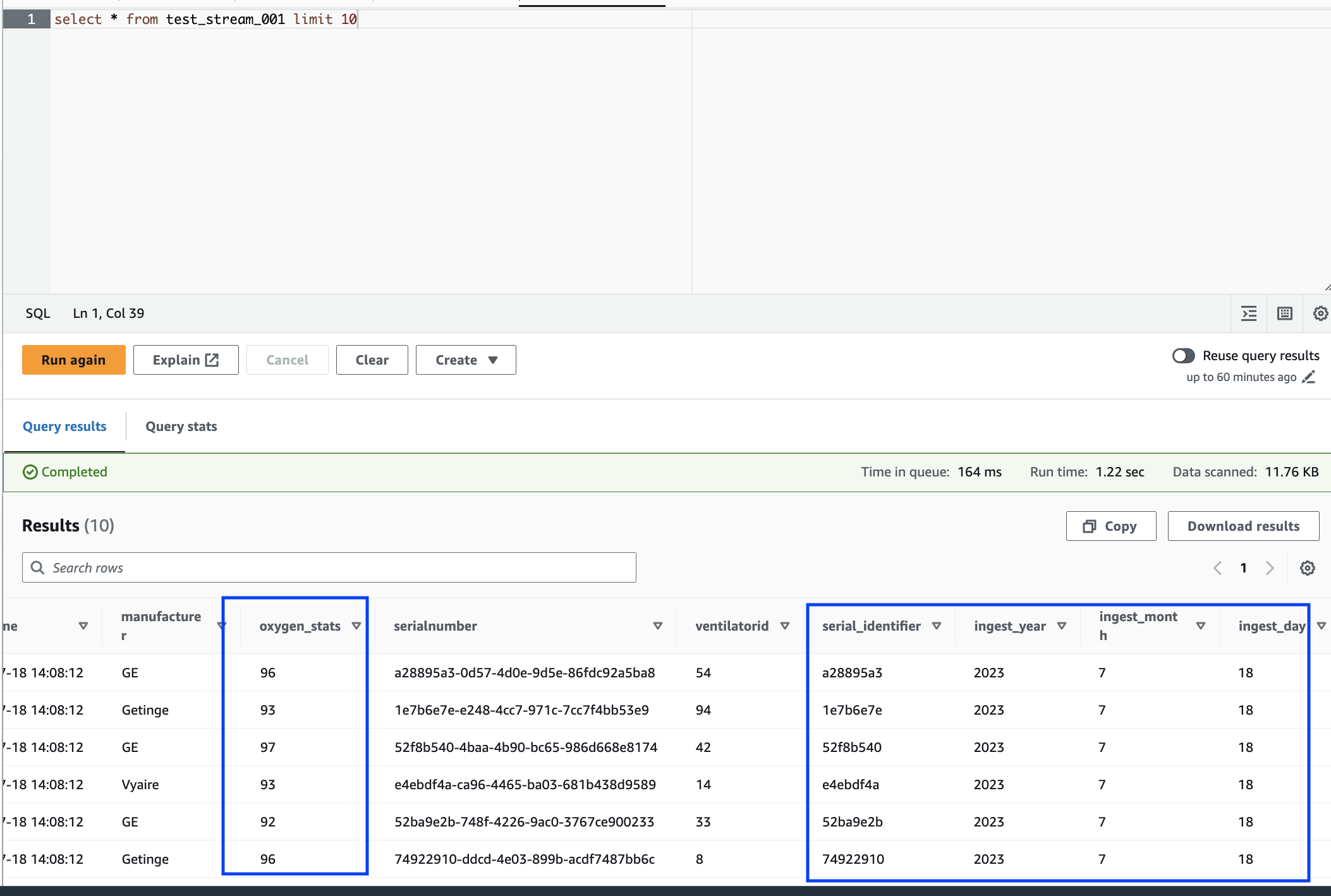
Ganti nama kolom (o2stats menjadi oxygen_stats).
Turunkan kolom baru (serial_identifier, ingest_year, ingest_month dan ingest_day).
Simpan hasilnya ke dalam ember Amazon S3 dan buat juga tabel katalog yang dipartisi AWS Glue
Di sel terakhir, Anda memicu batch proses setiap 10 detik. Jalankan sel dan tunggu sekitar 30 detik untuk mengisi ember Amazon S3 dan tabel katalog AWS Glue .
Terakhir, telusuri data yang disimpan menggunakan editor kueri Amazon Athena. Anda dapat melihat kolom yang diganti namanya dan juga partisi baru.
Notebook memiliki semua instruksi yang diperlukan untuk melanjutkan tutorial. Anda dapat menjalankan instruksi pada notebook atau mengikuti tutorial ini untuk melanjutkan pengembangan pekerjaan.
Simpan dan jalankan AWS Glue pekerjaan
Dengan pengembangan dan pengujian aplikasi Anda selesai menggunakan notebook sesi interaktif, klik Simpan di bagian atas antarmuka notebook. Setelah disimpan, Anda juga dapat menjalankan aplikasi sebagai pekerjaan.

Bersihkan
Untuk menghindari biaya tambahan ke akun Anda, hentikan pekerjaan streaming yang Anda mulai sebagai bagian dari instruksi. Anda dapat melakukan ini dengan menghentikan notebook, yang akan mengakhiri sesi. Kosongkan bucket Amazon S3 dan hapus AWS CloudFormation tumpukan yang Anda sediakan sebelumnya.
Kesimpulan
Dalam tutorial ini, kami menunjukkan bagaimana melakukan hal berikut menggunakan notebook AWS Glue Studio
Penulis pekerjaan streaming ETL menggunakan notebook
Pratinjau aliran data yang masuk
Kode dan perbaiki masalah tanpa harus mempublikasikan AWS Glue pekerjaan
Tinjau kode end-to-end kerja, hapus debugging, dan cetak pernyataan atau sel dari buku catatan
Publikasikan kode sebagai AWS Glue pekerjaan
Tujuan dari tutorial ini adalah untuk memberi Anda pengalaman langsung bekerja dengan AWS Glue Streaming dan sesi interaktif. Kami mendorong Anda untuk menggunakan ini sebagai referensi untuk kasus penggunaan AWS Glue Streaming individual Anda. Lihat informasi yang lebih lengkap di Memulai dengan sesi AWS Glue interaktif.
