Terjemahan disediakan oleh mesin penerjemah. Jika konten terjemahan yang diberikan bertentangan dengan versi bahasa Inggris aslinya, utamakan versi bahasa Inggris.
Membuat tabel
Meskipun menjalankan crawler adalah metode yang disarankan untuk mengambil inventaris data di penyimpanan data Anda, Anda dapat menambahkan tabel metadata secara manual. AWS Glue Data Catalog Pendekatan ini memungkinkan Anda untuk memiliki kontrol lebih besar atas definisi metadata dan menyesuaikannya sesuai dengan kebutuhan spesifik Anda.
Anda juga dapat menambahkan tabel ke Katalog Data secara manual dengan cara berikut:
-
Gunakan konsol AWS Glue untuk secara manual membuat tabel di AWS Glue Data Catalog. Untuk informasi selengkapnya, lihat Membuat tabel menggunakan konsol.
-
Gunakan operasi
CreateTabledi AWS Glue API untuk membuat tabel di AWS Glue Data Catalog. Untuk informasi selengkapnya, lihat CreateTable tindakan (Python: create_table). -
Gunakan AWS CloudFormation templat. Untuk informasi selengkapnya, lihat AWS CloudFormation untuk AWS Glue.
Ketika Anda menentukan sebuah tabel secara manual dengan menggunakan konsol atau API, Anda menentukan skema tabel dan nilai dari sebuah bidang klasifikasi yang menunjukkan jenis dan format data dalam sumber data. Jika sebuah crawler membuat tabel, maka format data dan skemanya ditentukan oleh pengklasifikasi bawaan atau pengklasifikasi kustom. Untuk informasi lebih lanjut tentang membuat sebuah tabel menggunakan konsol AWS Glue, lihat Membuat tabel menggunakan konsol.
Topik
Partisi tabel
Sebuah definisi tabel AWS Glue dari sebuah folder Amazon Simple Storage Service (Amazon S3) dapat menggambarkan sebuah tabel yang dipartisi. Sebagai contoh, untuk meningkatkan performa kueri, sebuah tabel yang dipartisi mungkin memisahkan data bulanan ke file yang berbeda dengan menggunakan nama bulan sebagai kunci. Di AWS Glue, definisi tabel termasuk kunci partisi dari sebuah tabel. Saat AWS Glue mengevaluasi data dalam folder Amazon S3 untuk membuat katalog sebuah tabel, ia menentukan apakah tabel individu atau tabel dipartisi ditambahkan.
Anda dapat membuat indeks partisi pada sebuah tabel untuk mengambil subset dari partisi alih-alih memuat semua partisi dalam tabel. Untuk informasi tentang cara menggunakan indeks partisi, lihat Membuat indeks partisi .
Semua syarat berikut harus BETUL untuk AWS Glue untuk membuat sebuah tabel dipartisi untuk folder Amazon S3:
-
Skema file-nya serupa, seperti yang ditentukan oleh AWS Glue.
-
Format data dari file tersebut sama.
-
Format kompresi dari file tersebut sama.
Sebagai contoh, Anda mungkin memiliki sebuah bucket Amazon S3 bernama my-app-bucket, tempat Anda menyimpan data penjualan aplikasi iOS dan Android. Data tersebut dipartisi berdasarkan tahun, bulan, dan hari. File data untuk penjualan iOS dan Android memiliki skema yang sama, format data, dan format kompresi yang juga sama. Dalam AWS Glue Data Catalog, AWS Glue crawler membuat satu definisi tabel dengan kunci partisi untuk tahun, bulan, dan hari.
Pendaftaran Amazon S3 atas my-app-bucket berikut ini menunjukkan beberapa partisi. Simbol = digunakan untuk menetapkan nilai kunci partisi.
my-app-bucket/Sales/year=2010/month=feb/day=1/iOS.csv my-app-bucket/Sales/year=2010/month=feb/day=1/Android.csv my-app-bucket/Sales/year=2010/month=feb/day=2/iOS.csv my-app-bucket/Sales/year=2010/month=feb/day=2/Android.csv ... my-app-bucket/Sales/year=2017/month=feb/day=4/iOS.csv my-app-bucket/Sales/year=2017/month=feb/day=4/Android.csv
Tautan sumber daya tabel
| AWS GlueKonsol baru-baru ini diperbarui. Versi konsol saat ini tidak mendukung Tautan Sumber Daya Tabel. |
Katalog Data juga dapat berisi tautan sumber daya ke tabel. Sebuah tautan sumber daya tabel adalah tautan ke tabel lokal atau bersama. Saat ini, Anda dapat membuat tautan sumber daya hanya di AWS Lake Formation. Setelah Anda membuat tautan sumber daya ke sebuah tabel, Anda dapat menggunakan nama tautan sumber daya di mana pun Anda akan menggunakan nama tabel tersebut. Bersama dengan tabel yang Anda miliki atau yang dibagi dengan Anda, tautan sumber daya tabel dikembalikan oleh glue:GetTables() dan muncul sebagai entri pada halaman Tabel pada konsol AWS Glue.
Katalog Data juga dapat berisi tautan sumber daya basis data.
Untuk informasi lebih lanjut tentang tautan sumber daya, lihat Membuat Tautan Sumber Daya di Panduan Developer AWS Lake Formation .
Membuat tabel menggunakan konsol
Tabel dalam AWS Glue Data Catalog adalah definisi metadata yang mewakili data dalam penyimpanan data. Anda membuat tabel ketika Anda menjalankan sebuah crawler, atau Anda dapat membuat sebuah tabel secara manual di konsol AWS Glue . Daftar Tabel di konsol AWS Glue menampilkan nilai-nilai metadata tabel Anda. Anda menggunakan definisi tabel untuk menentukan sumber dan target ketika Anda membuat tugas ETL (ekstrak, transform, and load).
catatan
Dengan perubahan terbaru pada konsol AWS manajemen, Anda mungkin perlu mengubah peran IAM yang ada untuk mendapatkan SearchTablesizin. Untuk pembuatan peran baru, izin SearchTables API telah ditambahkan sebagai default.
Untuk memulai, masuk ke AWS Management Console dan buka AWS Glue konsol di https://console.aws.amazon.com/glue/
Menambahkan tabel di konsol
Untuk menggunakan sebuah crawler untuk menambahkan tabel, pilih Tambahkan tabel, Tambahkan tabel menggunakan crawler. Kemudian ikuti instruksi di penuntun Tambahkan crawler. Ketika sebuah crawler berjalan, tabel ditambahkan ke AWS Glue Data Catalog. Untuk informasi selengkapnya, lihat Menggunakan crawler untuk mengisi Katalog Data .
Jika Anda tahu atribut yang diperlukan untuk membuat definisi tabel Amazon Simple Storage Service (Amazon S3) dalam Katalog Data Anda, maka Anda dapat membuatnya dengan penuntun tabel. Pilih Tambahkan tabel, Tambahkan Tabel secara manual, lalu ikuti petunjuk di penuntun Tambahkan tabel.
Saat menambahkan tabel secara manual melalui konsol, pertimbangkan hal-hal berikut:
-
Jika Anda berencana untuk mengakses tabel dari Amazon Athena, maka berikan nama dengan hanya karakter alfanumerik dan garis bawah. Untuk informasi selengkapnya, lihat Nama Athena.
-
Lokasi sumber data Anda harus sebuah path Amazon S3.
-
Format data dari data tersebut harus sesuai dengan salah satu format yang tercantum di penuntun. Klasifikasi yang sesuai SerDe,, dan properti tabel lainnya secara otomatis diisi berdasarkan format yang dipilih. Anda dapat menentukan tabel dengan format berikut ini:
- Avro
-
Format biner Apache Avro JSON.
- CSV
-
Nilai dipisahkan karakter. Anda juga menentukan pembatas baik koma, pipa, titik koma, tab, atau Ctrl-A.
- JSON
-
JavaScript Notasi Objek.
- XML
-
Format Markup Extensible Language. Tentukan tag XML yang mendefinisikan sebuah baris dalam data. Kolom didefinisikan dalam tag baris.
- Parquet
-
penyimpanan kolumnar Apache Parquet.
- ORC
-
Format file Row Columnar (ORC) yang dioptimalkan. Format yang dirancang untuk menyimpan data Hive secara efisien.
-
Anda dapat menentukan sebuah kunci partisi untuk tabel.
-
Saat ini, tabel dipartisi yang Anda buat dengan konsol tidak dapat digunakan dalam tugas ETL.
Atribut tabel
Berikut ini adalah beberapa atribut penting dari tabel Anda:
- Nama
-
Nama ditentukan ketika tabel dibuat, dan Anda tidak dapat mengubahnya. Anda mengacu pada nama tabel di banyak operasi AWS Glue.
- Basis Data
-
Objek kontainer di mana tabel Anda berada. Objek ini berisi organisasi tabel Anda yang ada di dalam AWS Glue Data Catalog dan mungkin berbeda dari organisasi di penyimpanan data Anda. Ketika Anda menghapus basis data, semua tabel yang terkandung dalam basis data juga dihapus dari Katalog Data.
- Deskripsi
-
Deskripsi tabel. Anda dapat menulis deskripsi untuk membantu Anda memahami isi tabel tersebut.
- Format tabel
-
Tentukan membuat AWS Glue tabel standar, atau tabel dalam format Apache Iceberg.
Katalog Data menyediakan opsi pengoptimalan tabel berikut untuk mengelola penyimpanan tabel dan meningkatkan kinerja kueri untuk tabel Iceberg.
-
Pemadatan — File data digabungkan dan ditulis ulang menghapus data usang dan mengkonsolidasikan data yang terfragmentasi menjadi file yang lebih besar dan lebih efisien.
Retensi snapshot — Snapshot adalah versi stempel waktu dari tabel Iceberg. Konfigurasi retensi snapshot memungkinkan pelanggan untuk menerapkan berapa lama untuk menyimpan snapshot dan berapa banyak snapshot yang akan disimpan. Mengonfigurasi pengoptimal retensi snapshot dapat membantu mengelola overhead penyimpanan dengan menghapus snapshot yang lebih lama dan tidak perlu serta file yang mendasarinya yang terkait.
Penghapusan file yatim piatu — File yatim piatu adalah file yang tidak lagi direferensikan oleh metadata tabel Iceberg. File-file ini dapat terakumulasi dari waktu ke waktu, terutama setelah operasi seperti penghapusan tabel atau pekerjaan ETL yang gagal. Mengaktifkan penghapusan file yatim memungkinkan AWS Glue untuk secara berkala mengidentifikasi dan menghapus file-file yang tidak perlu ini, membebaskan penyimpanan.
Untuk informasi selengkapnya, lihat Mengoptimalkan tabel Iceberg.
-
- Konfigurasi optimasi
Anda dapat menggunakan pengaturan default atau menyesuaikan pengaturan untuk mengaktifkan pengoptimal tabel.
- Peran IAM
Untuk menjalankan pengoptimal tabel, layanan mengasumsikan peran IAM atas nama Anda. Anda dapat memilih peran IAM menggunakan drop-down. Pastikan peran memiliki izin yang diperlukan untuk mengaktifkan pemadatan.
Untuk mempelajari lebih lanjut tentang izin yang diperlukan untuk peran IAM, lihat. Prasyarat pengoptimalan tabel
- Lokasi
-
Penunjuk ke lokasi data dalam penyimpanan data yang diwakili oleh definisi tabel ini.
- Klasifikasi
-
Nilai kategorisasi yang diberikan saat tabel dibuat. Biasanya, nilai ini ditulis ketika crawler menjalankan dan menentukan format data sumber.
- Terakhir diperbarui
-
Waktu dan tanggal (UTC) saat tabel ini diperbarui dalam Katalog Data.
- Tanggal ditambahkan
-
Waktu dan tanggal (UTC) saat tabel ini ditambahkan ke Katalog Data.
- Dihentikan
-
Jika AWS Glue menemukan bahwa tabel di Katalog Data tidak lagi ada di penyimpanan data semula, maka ia akan menandai tabel sebagai tidak lagi digunakan dalam katalog data. Jika Anda menjalankan tugas yang me-referensi tabel yang tidak lagi digunakan, tugas mungkin gagal. Edit tugas yang me-referensi tabel yang tidak lagi digunakan untuk menghapusnya sebagai sumber dan target. Kami sarankan Anda menghapus tabel yang tidak lagi digunakan ketika tidak lagi diperlukan.
- Koneksi
-
Jika AWS Glue memerlukan koneksi ke penyimpanan data Anda, maka nama koneksi dikaitkan dengan tabel tersebut.
Melihat dan mengelola detail tabel
Untuk melihat detail tabel yang ada, pilih nama tabel dalam daftar, dan kemudian pilih Tindakan, Lihat detail.
Detail tabel termasuk properti dari tabel Anda dan skema-nya. Tampilan ini menampilkan skema tabel, termasuk nama kolom dalam urutan yang ditetapkan untuk tabel, tipe data, dan kolom kunci untuk partisi. Jika kolom merupakan tipe kolom yang kompleks, Anda dapat memilih Lihat properti untuk menampilkan detail struktur dari bidang itu, seperti yang ditunjukkan dalam contoh berikut:
{ "StorageDescriptor": { "cols": { "FieldSchema": [ { "name": "primary-1", "type": "CHAR", "comment": "" }, { "name": "second ", "type": "STRING", "comment": "" } ] }, "location": "s3://aws-logs-111122223333-us-east-1", "inputFormat": "", "outputFormat": "org.apache.hadoop.hive.ql.io.HiveIgnoreKeyTextOutputFormat", "compressed": "false", "numBuckets": "0", "SerDeInfo": { "name": "", "serializationLib": "org.apache.hadoop.hive.serde2.OpenCSVSerde", "parameters": { "separatorChar": "|" } }, "bucketCols": [], "sortCols": [], "parameters": {}, "SkewedInfo": {}, "storedAsSubDirectories": "false" }, "parameters": { "classification": "csv" } }
Untuk informasi lebih lanjut tentang properti tabel, seperti StorageDescriptor, lihat StorageDescriptor struktur.
Untuk mengubah skema tabel, pilih Edit skema untuk menambah dan menghapus kolom, mengubah nama kolom, dan mengubah tipe data.
Untuk membandingkan versi tabel yang berbeda, termasuk skemanya, pilih Bandingkan versi untuk melihat side-by-side perbandingan dua versi skema untuk tabel. Untuk informasi selengkapnya, lihat Membandingkan versi skema tabel .
Untuk menampilkan file yang membentuk sebuah partisi Amazon S3, pilih Lihat partisi. Untuk tabel Amazon S3, kolom Kunci menampilkan kunci partisi yang digunakan untuk partisi tabel di penyimpanan data sumber. Pemartisian adalah cara untuk membagi tabel menjadi bagian-bagian terkait berdasarkan nilai-nilai kolom kunci, seperti tanggal, lokasi, atau departemen. Untuk informasi lebih lanjut tentang partisi, cari di internet untuk informasi tentang "pemartisian hive."
catatan
Untuk mendapatkan step-by-step panduan untuk melihat detail tabel, lihat tutorial Jelajahi tabel di konsol.
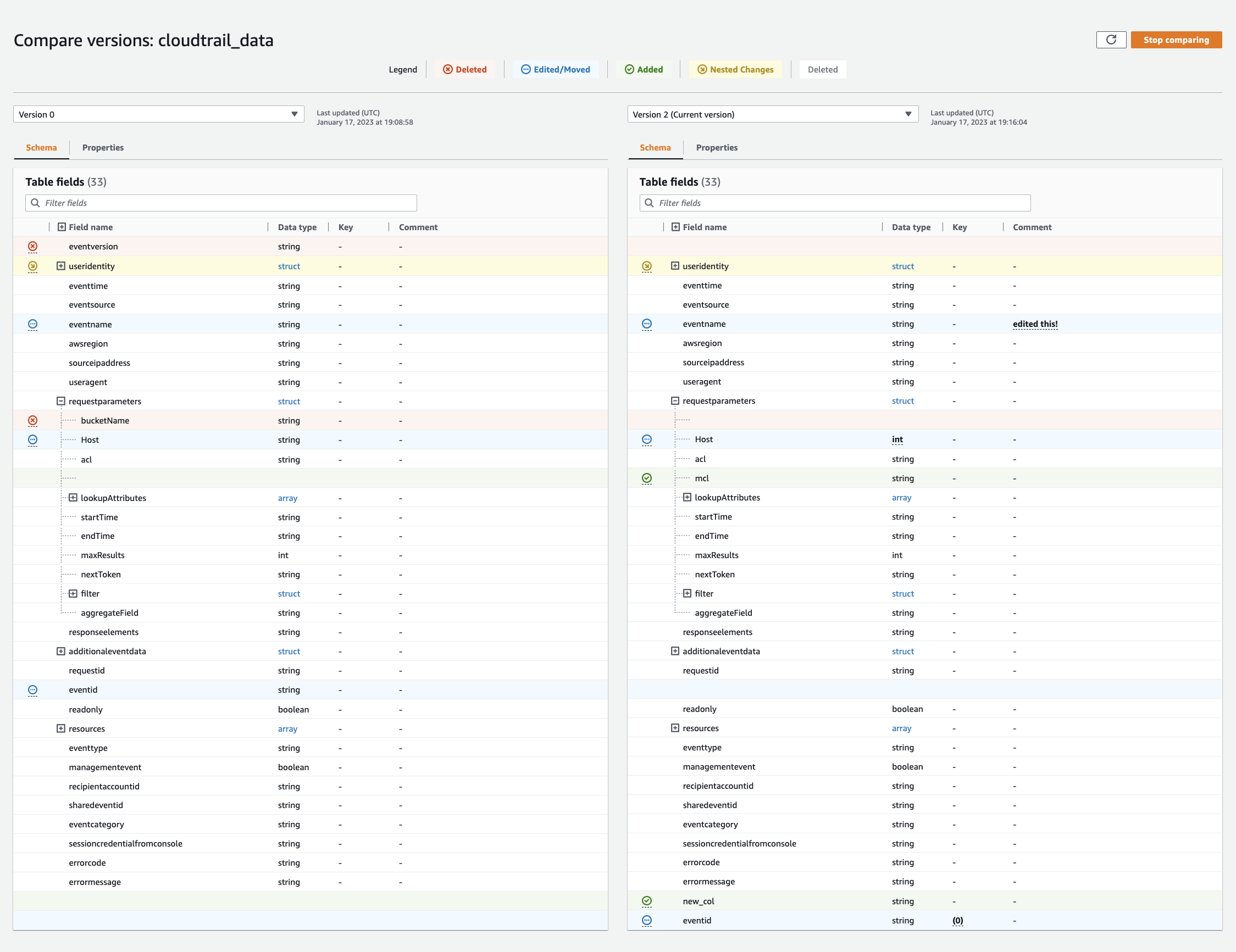
Membandingkan versi skema tabel
Saat membandingkan dua versi skema tabel, Anda dapat membandingkan perubahan baris bersarang dengan memperluas dan menciutkan baris bersarang, membandingkan skema dua versi side-by-side, dan melihat properti tabel. side-by-side
Untuk membandingkan versi
-
Dari AWS Glue konsol, pilih Tabel, lalu Tindakan dan pilih Bandingkan versi.
-
Pilih versi untuk membandingkan dengan memilih menu drop-down versi. Saat membandingkan skema, tab Skema disorot dengan warna oranye.
-
Ketika Anda membandingkan tabel antara dua versi, skema tabel disajikan kepada Anda di sisi kiri dan kanan layar. Ini memungkinkan Anda untuk menentukan perubahan secara visual dengan membandingkan nama Kolom, tipe data, kunci, dan kolom komentar side-by-side. Ketika ada perubahan, ikon berwarna menampilkan jenis perubahan yang dibuat.
-
Dihapus - ditampilkan oleh ikon merah menunjukkan di mana kolom telah dihapus dari versi sebelumnya dari skema tabel.
-
Diedit atau Dipindahkan — ditampilkan oleh ikon biru menunjukkan di mana kolom dimodifikasi atau dipindahkan dalam versi skema tabel yang lebih baru.
-
Ditambahkan - ditampilkan oleh ikon hijau menunjukkan di mana kolom ditambahkan ke versi yang lebih baru dari skema tabel.
-
Perubahan bersarang - ditampilkan oleh ikon kuning menunjukkan di mana kolom bersarang berisi perubahan. Pilih kolom untuk memperluas dan melihat kolom yang telah dihapus, diedit, dipindahkan, atau ditambahkan.
-
-
Gunakan bilah pencarian bidang filter untuk menampilkan bidang berdasarkan karakter yang Anda masukkan di sini. Jika Anda memasukkan nama kolom di salah satu versi tabel, bidang yang difilter akan ditampilkan di kedua versi tabel untuk menunjukkan di mana perubahan telah terjadi.
-
Untuk membandingkan properti, pilih tab Properties.
-
Untuk berhenti membandingkan versi, pilih Berhenti membandingkan untuk kembali ke daftar tabel.
Memperbarui tabel Katalog Data yang dibuat secara manual menggunakan crawler
Anda mungkin ingin membuat AWS Glue Data Catalog tabel secara manual dan kemudian memperbaruinya dengan AWS Glue crawler. Crawler yang berjalan berdasarkan jadwal dapat menambahkan partisi baru dan memperbarui tabel dengan perubahan skema. Hal ini juga berlaku untuk tabel yang telah bermigrasi dari metastore Apache Hive.
Caranya, ketika Anda menentukan sebuah crawler, alih-alih menentukan satu atau beberapa penyimpanan data sebagai sumber perayapan, Anda tentukan satu atau beberapa tabel Katalog Data yang ada. Crawler tersebut kemudian melakukan crawling pada penyimpanan data yang ditentukan oleh tabel katalog. Dalam kasus ini, tidak ada tabel baru yang dibuat; sebaliknya, tabel Anda yang dibuat secara manual diperbarui.
Berikut ini adalah alasan-alasan lain mengapa Anda mungkin ingin membuat tabel katalog secara manual dan menentukan tabel katalog sebagai sumber crawler:
-
Anda ingin memilih nama tabel katalog dan tidak bergantung pada algoritme penamaan tabel katalog.
-
Anda ingin mencegah tabel baru dibuat dalam kasus di mana file dengan format yang dapat mengganggu deteksi partisi keliru disimpan di path sumber data.
Untuk informasi selengkapnya, lihat Langkah 2: Pilih sumber data dan pengklasifikasi.
Properti tabel Katalog Data
Properti tabel, atau parameter, seperti yang dikenal dalam AWS CLI, adalah string kunci dan nilai yang tidak divalidasi. Anda dapat mengatur properti Anda sendiri di atas tabel untuk mendukung penggunaan Katalog Data di luar AWS Glue. Layanan lain yang menggunakan Katalog Data dapat melakukannya juga. AWS Glue menetapkan beberapa properti tabel saat menjalankan pekerjaan atau crawler. Kecuali dijelaskan lain, properti ini untuk penggunaan internal, kami tidak mendukung bahwa properti tersebut akan terus ada dalam bentuknya saat ini, atau mendukung perilaku produk jika properti ini diubah secara manual.
Untuk informasi selengkapnya tentang properti tabel yang ditetapkan oleh AWS Glue crawler, lihatParameter diatur pada tabel Katalog Data oleh crawler.
