Kami tidak lagi memperbarui layanan Amazon Machine Learning atau menerima pengguna baru untuk itu. Dokumentasi ini tersedia untuk pengguna yang sudah ada, tetapi kami tidak lagi memperbaruinya. Untuk informasi selengkapnya, lihat Apa itu Amazon Machine Learning.
Terjemahan disediakan oleh mesin penerjemah. Jika konten terjemahan yang diberikan bertentangan dengan versi bahasa Inggris aslinya, utamakan versi bahasa Inggris.
Validasi Lintas
Validasi silang adalah teknik untuk mengevaluasi model ML dengan melatih beberapa model ML pada himpunan bagian dari data input yang tersedia dan mengevaluasinya pada subset data yang saling melengkapi. Gunakan validasi silang untuk mendeteksi overfitting, yaitu gagal menggeneralisasi pola.
Di Amazon, Anda dapat menggunakan metode validasi silang k-fold untuk melakukan validasi silang. Dalam validasi silang k-fold, Anda membagi data input menjadi k subset data (juga dikenal sebagai lipatan). Anda melatih model MLpada semua kecuali satu (k-1) dari himpunan bagian, dan kemudian mengevaluasi model pada subset yang tidak digunakan untuk pelatihan. Proses ini diulang k kali, dengan subset berbeda disediakan untuk evaluasi (dan dikecualikan dari pelatihan) setiap kali.
Diagram berikut menunjukkan contoh himpunan bagian pelatihan dan himpunan bagian evaluasi komplementer yang dihasilkan untuk masing-masing dari empat model yang dibuat dan dilatih selama validasi silang 4 kali lipat. Model pertama menggunakan 25 persen data pertama untuk evaluasi, dan 75 persen sisanya untuk pelatihan. Model dua menggunakan subset kedua 25 persen (25 persen hingga 50 persen) untuk evaluasi, dan tiga himpunan bagian data sisanya untuk pelatihan, dan seterusnya.
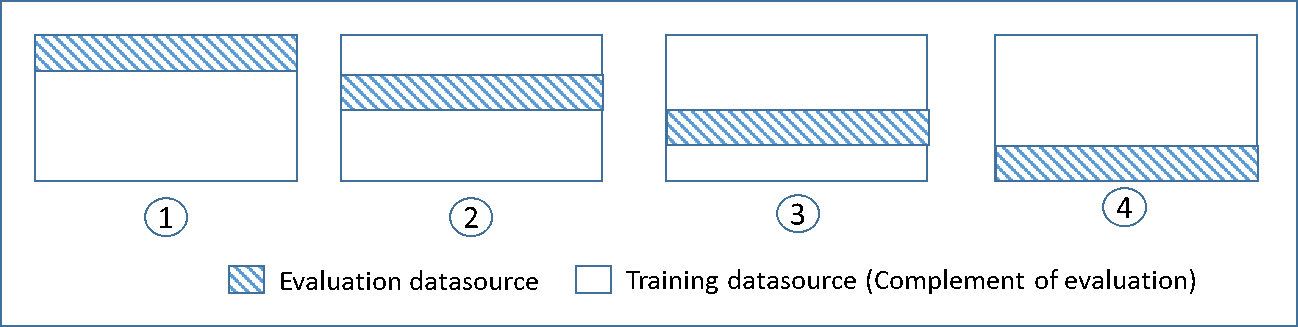
Setiap model dilatih dan dievaluasi menggunakan sumber data pelengkap - data dalam sumber data evaluasi mencakup dan terbatas pada semua data yang tidak ada dalam sumber data pelatihan. Anda membuat sumber data untuk masing-masing himpunan bagian ini dengan DataRearrangement parameter di,, dancreateDatasourceFromS3. createDatasourceFromRedShift createDatasourceFromRDS APIs Dalam DataRearrangement parameter, tentukan subset data mana yang akan disertakan dalam sumber data dengan menentukan di mana harus memulai dan mengakhiri setiap segmen. Untuk membuat sumber data pelengkap yang diperlukan untuk validasi silang 4 kali lipat, tentukan DataRearrangement parameter seperti yang ditunjukkan pada contoh berikut:
Model satu:
Sumber data untuk evaluasi:
{"splitting":{"percentBegin":0, "percentEnd":25}}
Sumber data untuk pelatihan:
{"splitting":{"percentBegin":0, "percentEnd":25, "complement":"true"}}
Model dua:
Sumber data untuk evaluasi:
{"splitting":{"percentBegin":25, "percentEnd":50}}
Sumber data untuk pelatihan:
{"splitting":{"percentBegin":25, "percentEnd":50, "complement":"true"}}
Model tiga:
Sumber data untuk evaluasi:
{"splitting":{"percentBegin":50, "percentEnd":75}}
Sumber data untuk pelatihan:
{"splitting":{"percentBegin":50, "percentEnd":75, "complement":"true"}}
Model empat:
Sumber data untuk evaluasi:
{"splitting":{"percentBegin":75, "percentEnd":100}}
Sumber data untuk pelatihan:
{"splitting":{"percentBegin":75, "percentEnd":100, "complement":"true"}}
Melakukan validasi silang 4 kali lipat menghasilkan empat model, empat sumber data untuk melatih model, empat sumber data untuk mengevaluasi model, dan empat evaluasi, satu untuk setiap model. Amazon ML menghasilkan metrik kinerja model untuk setiap evaluasi. Misalnya, dalam validasi silang 4 kali lipat untuk masalah klasifikasi biner, masing-masing evaluasi melaporkan metrik area di bawah kurva (AUC). Anda bisa mendapatkan ukuran kinerja keseluruhan dengan menghitung rata-rata dari empat metrik AUC. Untuk informasi tentang metrik AUC, lihatMengukur Akurasi Model ML.
Untuk kode contoh yang menunjukkan cara membuat validasi silang dan rata-rata skor model, lihat kode sampel Amazon Amazon
Menyesuaikan Model Anda
Setelah Anda memvalidasi silang model, Anda dapat menyesuaikan pengaturan untuk model berikutnya jika model Anda tidak sesuai dengan standar Anda. Untuk informasi lebih lanjut tentang overfitting, lihatModel Fit: Underfitting vs. Overfitting. Untuk informasi lebih lanjut tentang regularisasi, lihat. Regularisasi Untuk informasi selengkapnya tentang mengubah pengaturan regularisasi, lihat. Membuat Model ML dengan Opsi Kustom
