Kami tidak lagi memperbarui layanan Amazon Machine Learning atau menerima pengguna baru untuk itu. Dokumentasi ini tersedia untuk pengguna yang sudah ada, tetapi kami tidak lagi memperbaruinya. Untuk informasi selengkapnya, lihat Apa itu Amazon Machine Learning.
Terjemahan disediakan oleh mesin penerjemah. Jika konten terjemahan yang diberikan bertentangan dengan versi bahasa Inggris aslinya, utamakan versi bahasa Inggris.
Wawasan Data
Amazon ML menghitung statistik deskriptif pada data masukan yang dapat Anda gunakan untuk memahami data Anda.
Statistik Deskriptif
Amazon ML menghitung statistik deskriptif berikut untuk jenis atribut yang berbeda:
Numerik:
-
Histogram distribusi
-
Jumlah nilai yang tidak valid
-
Nilai minimum, median, rata-rata, dan maksimum
Biner dan kategoris:
-
Hitung (dari nilai berbeda per kategori)
-
Histogram distribusi nilai
-
Nilai yang paling sering
-
Nilai unik diperhitungkan
-
Persentase nilai sebenarnya (hanya biner)
-
Kata-kata yang paling menonjol
-
Kata-kata yang paling sering
Teks:
-
Nama atribut
-
Korelasi dengan target (jika target ditetapkan)
-
Total kata
-
Kata-kata unik
-
Rentang jumlah kata dalam satu baris
-
Rentang panjang kata
-
Kata-kata yang paling menonjol
Mengakses Data Insights di konsol Amazon
Di konsol Amazon Amazon, Anda dapat memilih nama atau ID sumber data apa pun untuk melihat halaman Data Insights. Halaman ini menyediakan metrik dan visualisasi yang memungkinkan Anda mempelajari data masukan yang terkait dengan sumber data, termasuk informasi berikut:
-
Ringkasan data
-
Distribusi target
-
Nilai yang hilang
-
Nilai tidak valid
-
Ringkasan statistik variabel menurut tipe data
-
Distribusi variabel menurut tipe data
Bagian berikut menjelaskan metrik dan visualisasi secara lebih rinci.
Ringkasan Data
Laporan ringkasan data dari sumber data menampilkan informasi ringkasan, termasuk ID sumber data, nama, tempat selesai, status saat ini, atribut target, informasi data masukan (lokasi bucket S3, format data, jumlah catatan yang diproses, dan jumlah catatan buruk yang ditemui selama pemrosesan) serta jumlah variabel menurut tipe data.
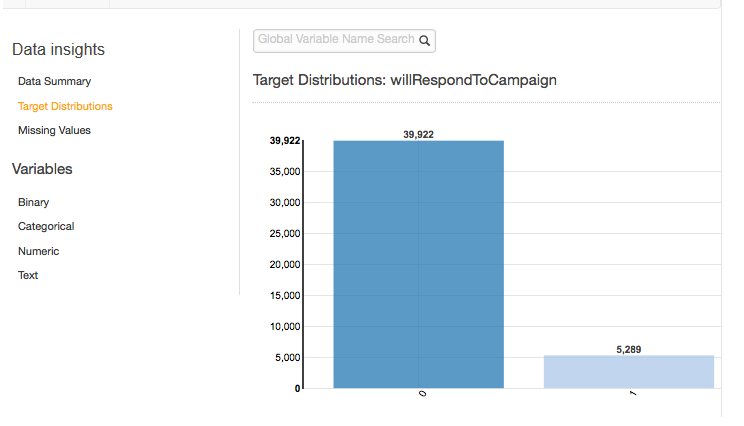
Distribusi Target
Laporan distribusi target menunjukkan distribusi atribut target dari sumber data. Dalam contoh berikut, ada 39.922 pengamatan di mana atribut target willRespondTo Kampanye sama dengan 0. Ini adalah jumlah pelanggan yang tidak menanggapi kampanye email. Ada 5.289 pengamatan di mana willRespondTo Kampanye sama dengan 1. Ini adalah jumlah pelanggan yang menanggapi kampanye email.
Nilai Hilang
Laporan nilai yang hilang mencantumkan atribut dalam data input yang nilainya hilang. Hanya atribut dengan tipe data numerik yang dapat memiliki nilai yang hilang. Karena nilai yang hilang dapat memengaruhi kualitas pelatihan model ML, kami merekomendasikan agar nilai yang hilang diberikan, jika memungkinkan.
Selama pelatihan model ML, jika atribut target hilang, Amazon MLakan menolak record yang sesuai. Jika atribut target ada dalam catatan, tetapi nilai untuk atribut numerik lain tidak ada, maka Amazon ML mengabaikan nilai yang hilang. Dalam kasus ini, Amazon ML membuat atribut pengganti dan menyetelnya ke 1 untuk menunjukkan bahwa atribut ini hilang. Hal ini memungkinkan Amazon ML untuk mempelajari pola dari terjadinya nilai yang hilang.
Nilai Tidak Valid
Nilai tidak valid hanya dapat terjadi dengan tipe data Numerik dan Biner. Anda dapat menemukan nilai yang tidak valid dengan melihat statistik ringkasan variabel dalam laporan tipe data. Dalam contoh berikut, ada satu nilai yang tidak valid dalam durasi atribut Numerik dan dua nilai tidak valid dalam tipe data biner (satu di atribut housing dan satu di atribut pinjaman).


Korelasi Variabel-Target
Setelah Anda membuat sumber data, Amazon ML dapat mengevaluasi sumber data dan mengidentifikasi korelasi, atau dampak, antara variabel dan target. Misalnya, harga suatu produk mungkin memiliki dampak yang signifikan pada apakah itu adalah best seller atau tidak, sedangkan dimensi produk mungkin memiliki daya prediksi yang kecil.
Ini umumnya merupakan praktik terbaik untuk memasukkan sebanyak mungkin variabel dalam data pelatihan Anda. Namun, noise yang diperkenalkan dengan memasukkan banyak variabel dengan daya prediksi kecil dapat berdampak negatif pada kualitas dan akurasi model ML Anda.
Anda mungkin dapat meningkatkan kinerja prediktif model Anda dengan menghapus variabel yang memiliki dampak kecil saat Anda melatih model Anda. Anda dapat menentukan variabel mana yang tersedia untuk proses pembelajaran mesin dalam resep, yang merupakan mekanisme transformasi Amazon ML. Untuk mempelajari lebih lanjut tentang resep, lihat Transformasi Data untuk Machine Learning.
Ringkasan Statistik Atribut menurut Tipe Data
Dalam laporan wawasan data, Anda dapat melihat statistik ringkasan atribut berdasarkan tipe data berikut:
-
Biner
-
Kategoris
-
Numerik
-
Teks
Statistik ringkasan untuk tipe data Biner menunjukkan semua atribut biner. Kolom Korelasi ke target menunjukkan informasi yang dibagikan antara kolom target dan kolom atribut. Kolom Persen benar menunjukkan persentase pengamatan yang memiliki nilai 1. Kolom Nilai tidak valid menunjukkan jumlah nilai yang tidak valid serta persentase nilai yang tidak valid untuk setiap atribut. Kolom Preview menyediakan link ke distribusi grafis untuk setiap atribut.
Statistik ringkasan untuk tipe data Categorical menunjukkan semua atribut Kategoris dengan jumlah nilai unik, nilai paling sering, dan nilai yang paling sering. Kolom Preview menyediakan link ke distribusi grafis untuk setiap atribut.

Statistik ringkasan untuk tipe data numerik menunjukkan semua atribut Numerik dengan jumlah nilai yang hilang, nilai tidak valid, rentang nilai, rata-rata, dan median. Kolom Preview menyediakan link ke distribusi grafis untuk setiap atribut.
Statistik ringkasan untuk tipe data Teks menunjukkan semua atribut Teks, jumlah total kata dalam atribut itu, jumlah kata unik dalam atribut itu, rentang kata dalam atribut, rentang panjang kata, dan kata-kata yang paling menonjol. Kolom Preview menyediakan link ke distribusi grafis untuk setiap atribut.
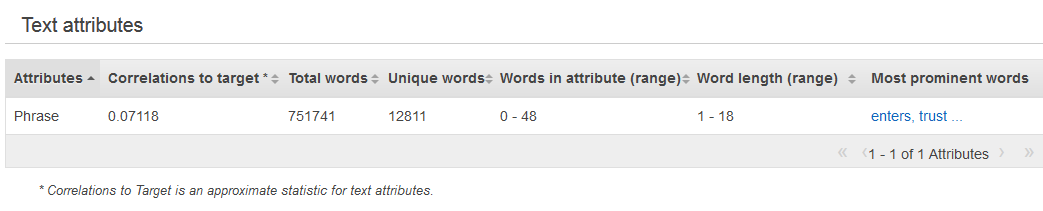
Contoh berikutnya menunjukkan statistik tipe data Teks untuk variabel teks yang disebut review, dengan empat catatan.
1. The fox jumped over the fence. 2. This movie is intriguing. 3. 4. Fascinating movie.
Kolom untuk contoh ini akan menampilkan informasi berikut.
-
Kolom Atribut menunjukkan nama variabel. Dalam contoh ini, kolom ini akan mengatakan “review.”
-
Kolom Korelasi ke target hanya ada jika target ditentukan. Korelasi mengukur jumlah informasi yang diberikan atribut ini tentang target. Semakin tinggi korelasinya, semakin banyak atribut ini memberi tahu Anda tentang target. Korelasi diukur dalam hal informasi timbal balik antara representasi sederhana dari atribut teks dan target.
-
Kolom Total kata menunjukkan jumlah kata yang dihasilkan dari tokenisasi setiap catatan, membatasi kata-kata dengan spasi putih. Dalam contoh ini, kolom ini akan mengatakan “12".
-
Kolom Kata unik menunjukkan jumlah kata unik untuk atribut. Dalam contoh ini, kolom ini akan mengatakan “10.”
-
Kolom Words in attribute (range) menunjukkan jumlah kata dalam satu baris dalam atribut. Dalam contoh ini, kolom ini akan mengatakan “0-6.”
-
Kolom panjang kata (rentang) menunjukkan kisaran berapa banyak karakter dalam kata-kata. Dalam contoh ini, kolom ini akan mengatakan “2-11.”
-
Kolom Kata yang paling menonjol menunjukkan daftar peringkat kata yang muncul di atribut. Jika ada atribut target, kata-kata diberi peringkat berdasarkan korelasinya dengan target, artinya kata-kata yang memiliki korelasi tertinggi dicantumkan terlebih dahulu. Jika tidak ada target yang ada dalam data, maka kata-kata tersebut diberi peringkat berdasarkan entropi mereka.
Memahami Distribusi Atribut Kategoris dan Biner
Dengan mengklik tautan Pratinjau yang terkait dengan atribut kategoris atau biner, Anda dapat melihat distribusi atribut tersebut serta data sampel dari file masukan untuk setiap nilai kategoris atribut.
Misalnya, tangkapan layar berikut menunjukkan distribusi untuk atribut kategoris JoBid. Distribusi menampilkan 10 nilai kategoris teratas, dengan semua nilai lainnya dikelompokkan sebagai “lainnya”. Ini memberi peringkat masing-masing dari 10 nilai kategoris teratas dengan jumlah pengamatan dalam file input yang berisi nilai itu, serta tautan untuk melihat pengamatan sampel dari file data input.

Memahami Distribusi Atribut Numerik
Untuk melihat distribusi atribut numerik, klik tautan Pratinjau atribut. Saat melihat distribusi atribut numerik, Anda dapat memilih ukuran bin 500, 200, 100, 50, atau 20. Semakin besar ukuran bin, semakin kecil jumlah grafik batang yang akan ditampilkan. Selain itu, resolusi distribusi akan kasar untuk ukuran tempat sampah besar. Sebaliknya, pengaturan ukuran bucket ke 20 meningkatkan resolusi distribusi yang ditampilkan.
Nilai minimum, rata-rata, dan maksimum juga ditampilkan, seperti yang ditunjukkan pada gambar berikut.

Memahami Distribusi Atribut Teks
Untuk melihat distribusi atribut teks, klik tautan Pratinjau atribut. Saat melihat distribusi atribut teks, Anda akan melihat informasi berikut.
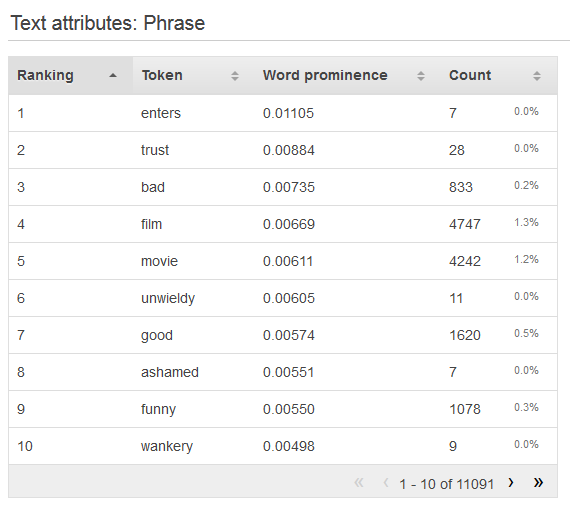
- Peringkat
-
Token teks diberi peringkat berdasarkan jumlah informasi yang mereka sampaikan, paling informatif hingga paling tidak informatif.
- Token
-
Token menunjukkan kata dari teks masukan yang berisi deretan statistik.
- Keunggulan kata
-
Jika ada atribut target, kata-kata diberi peringkat berdasarkan korelasinya dengan target, sehingga kata-kata yang memiliki korelasi tertinggi dicantumkan terlebih dahulu. Jika tidak ada target yang ada dalam data, maka kata-kata tersebut diberi peringkat berdasarkan entropi mereka, yaitu jumlah informasi yang dapat mereka komunikasikan.
- Hitung nomor
-
Nomor hitungan menunjukkan jumlah catatan masukan tempat token muncul.
- Hitung persentase
-
Persentase hitungan menunjukkan persentase baris data input tempat token muncul.
