Terjemahan disediakan oleh mesin penerjemah. Jika konten terjemahan yang diberikan bertentangan dengan versi bahasa Inggris aslinya, utamakan versi bahasa Inggris.
Fitur pencarian vektor dan batas
Ketersediaan pencarian vektor
Konfigurasi MemoryDB yang diaktifkan pencarian vektor didukung pada tipe node R6g, R7g, dan T4G dan tersedia di semua Wilayah di mana MemoryDB tersedia. AWS
Cluster yang ada tidak dapat dimodifikasi untuk mengaktifkan pencarian. Namun, cluster yang mendukung pencarian dapat dibuat dari snapshot cluster dengan penelusuran dinonaktifkan.
Pembatasan parametrik
Tabel berikut menunjukkan batas untuk berbagai item pencarian vektor:
| Item | Nilai maksimum |
|---|---|
| Jumlah dimensi dalam vektor | 32768 |
| Jumlah indeks yang dapat dibuat | 10 |
| Jumlah bidang dalam indeks | 50 |
| Klausa FT.SEARCH dan FT.AGGREGATE TIMEOUT (milidetik) | 10000 |
| Jumlah tahapan pipeline dalam perintah FT.AGGREGATE | 32 |
| Jumlah bidang dalam klausa FT.AGGREGATE LOAD | 1024 |
| Jumlah bidang dalam klausa FT.AGGREGATE GROUPBY | 16 |
| Jumlah bidang dalam klausa FT.AGGREGATE SORTBY | 16 |
| Jumlah parameter dalam klausa FT.AGGREGATE PARAM | 32 |
| Parameter HNSW M | 512 |
| Parameter HNSW EF_CONSTRUCTION | 4096 |
| Parameter HNSW EF_RUNTIME | 4096 |
Batas penskalaan
Pencarian vektor untuk MemoryDB saat ini terbatas pada pecahan tunggal dan penskalaan horizontal tidak didukung. Pencarian vektor mendukung penskalaan vertikal dan replika.
Pembatasan operasional
Indeks Persistensi dan Penimbunan Ulang
Fitur pencarian vektor mempertahankan definisi indeks, dan isi indeks. Ini berarti bahwa selama permintaan operasional atau peristiwa apa pun yang menyebabkan node memulai atau memulai ulang, definisi indeks dan konten dipulihkan dari snapshot terbaru dan setiap transaksi yang tertunda dibaca dari log transaksi Multi-AZ. Tidak ada tindakan pengguna yang diperlukan untuk memulai ini. Pembangunan kembali dilakukan sebagai operasi pengurukan segera setelah data dipulihkan. Ini secara fungsional setara dengan sistem yang secara otomatis menjalankan perintah FT.CREATE untuk setiap indeks yang ditentukan. Perhatikan bahwa node menjadi tersedia untuk operasi aplikasi segera setelah data dipulihkan tetapi kemungkinan sebelum pengurukan indeks selesai, yang berarti bahwa isi ulang akan kembali terlihat oleh aplikasi, misalnya, perintah pencarian menggunakan indeks backfilling dapat ditolak. Untuk informasi lebih lanjut tentang penimbunan ulang, lihatIkhtisar pencarian vektor.
Penyelesaian isi ulang indeks tidak disinkronkan antara primer dan replika. Kurangnya sinkronisasi ini secara tak terduga dapat terlihat oleh aplikasi dan oleh karena itu disarankan agar aplikasi memverifikasi penyelesaian pengisian ulang pada primer dan semua replika sebelum memulai operasi pencarian.
Snapshot import/export dan Migrasi Langsung
Kehadiran indeks pencarian dalam file RDB membatasi transportabilitas yang kompatibel dari data tersebut. Format indeks vektor yang ditentukan oleh fungsionalitas pencarian vektor MemoryDB hanya dipahami oleh cluster yang diaktifkan vektor MemoryDB lainnya. Selain itu, file RDB dari kluster pratinjau dapat diimpor oleh klaster MemoryDB versi GA, yang akan membangun kembali konten indeks saat memuat file RDB.
Namun, file RDB yang tidak mengandung indeks tidak dibatasi dengan cara ini. Dengan demikian data dalam klaster pratinjau dapat diekspor ke kluster non-pratinjau dengan menghapus indeks sebelum ekspor.
Konsumsi memori
Konsumsi memori didasarkan pada jumlah vektor, jumlah dimensi, nilai-M, dan jumlah data non-vektor, seperti metadata yang terkait dengan vektor atau data lain yang disimpan dalam instance.
Total memori yang dibutuhkan adalah kombinasi dari ruang yang dibutuhkan untuk data vektor aktual, dan ruang yang diperlukan untuk indeks vektor. Ruang yang diperlukan untuk data Vektor dihitung dengan mengukur kapasitas aktual yang diperlukan untuk menyimpan vektor dalam struktur data HASH atau JSON dan overhead ke pelat memori terdekat, untuk alokasi memori yang optimal. Setiap indeks vektor menggunakan referensi ke data vektor yang disimpan dalam struktur data ini, dan menggunakan pengoptimalan memori yang efisien untuk menghapus salinan duplikat data vektor dalam indeks.
Jumlah vektor tergantung pada bagaimana Anda memutuskan untuk mewakili data Anda sebagai vektor. Misalnya, Anda dapat memilih untuk mewakili satu dokumen menjadi beberapa potongan, di mana setiap potongan mewakili vektor. Atau, Anda dapat memilih untuk mewakili seluruh dokumen sebagai vektor tunggal.
Jumlah dimensi vektor Anda tergantung pada model penyematan yang Anda pilih. Misalnya, jika Anda memilih untuk menggunakan model embedding AWS Titan
Parameter M mewakili jumlah tautan dua arah yang dibuat untuk setiap elemen baru selama konstruksi indeks. MemoryDB default nilai ini ke 16; Namun, Anda dapat mengganti ini. Parameter M yang lebih tinggi bekerja lebih baik untuk persyaratan penarikan and/or tinggi dimensi tinggi sementara parameter M rendah bekerja lebih baik untuk persyaratan penarikan rendah dimensi and/or rendah. Nilai M meningkatkan konsumsi memori karena indeks menjadi lebih besar, meningkatkan konsumsi memori.
Dalam pengalaman konsol, MemoryDB menawarkan cara mudah untuk memilih jenis instans yang tepat berdasarkan karakteristik beban kerja vektor Anda setelah memeriksa Aktifkan pencarian vektor di bawah pengaturan cluster.
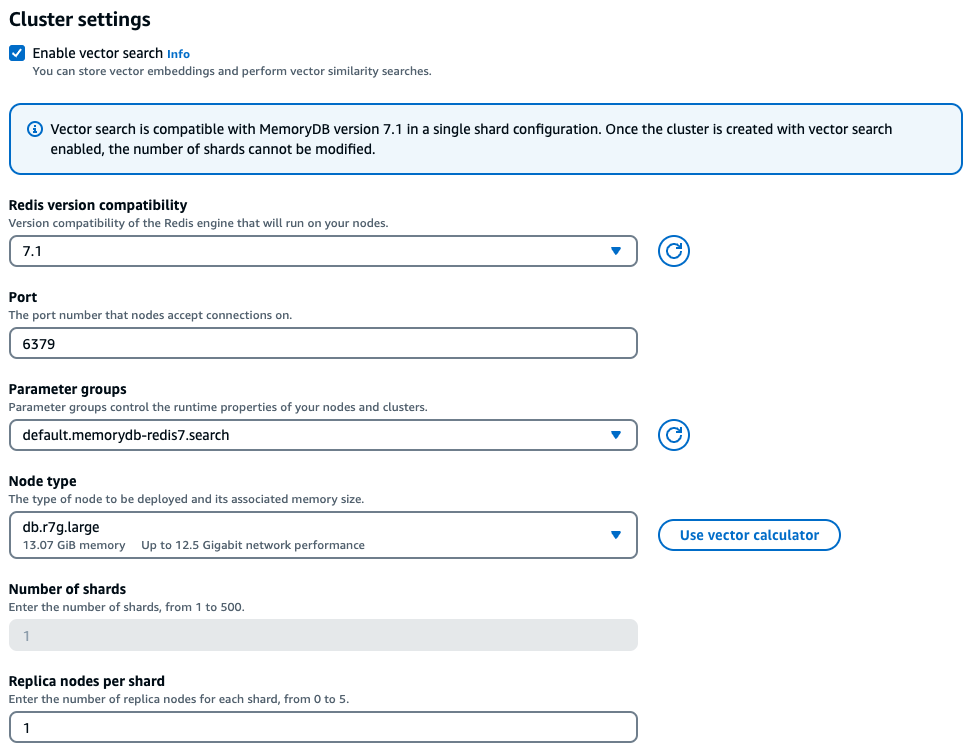
Contoh beban kerja
Seorang pelanggan ingin membangun mesin pencari semantik yang dibangun di atas dokumen keuangan internal mereka. Mereka saat ini memegang 1M dokumen keuangan yang dipotong menjadi 10 vektor per dokumen menggunakan model embedding titan dengan 1536 dimensi dan tidak memiliki data non-vektor. Pelanggan memutuskan untuk menggunakan default 16 sebagai parameter M.
Vektor: 1 M * 10 potongan = 10M vektor
Dimensi: 1536
Data Non-Vektor (GB): 0 GB
Parameter M: 16
Dengan data ini, pelanggan dapat mengklik tombol Gunakan kalkulator vektor di dalam konsol untuk mendapatkan jenis instans yang direkomendasikan berdasarkan parameternya:
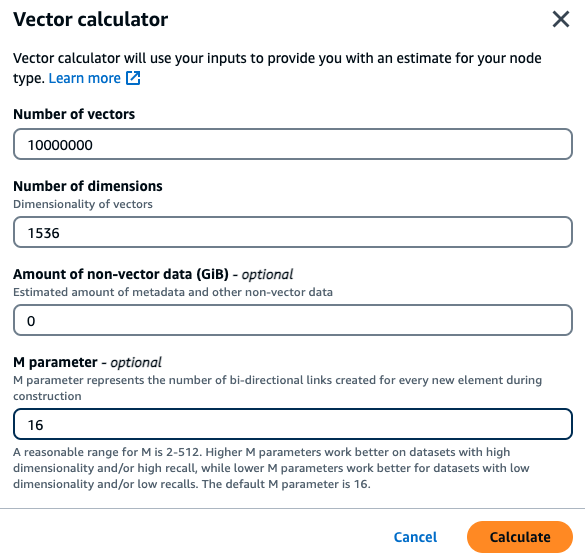

Dalam contoh ini, kalkulator vektor akan mencari jenis node r7g MemoryDB
Berdasarkan metode perhitungan di atas dan parameter dalam beban kerja sampel, data vektor ini akan membutuhkan 104,9 GB untuk menyimpan data dan indeks tunggal. Dalam hal ini, jenis db.r7g.4xlarge instance akan direkomendasikan karena memiliki 105,81 GB memori yang dapat digunakan. Tipe node terkecil berikutnya akan terlalu kecil untuk menahan beban kerja vektor.
Karena masing-masing indeks vektor menggunakan referensi ke data vektor yang disimpan dan tidak membuat salinan tambahan dari data vektor dalam indeks vektor, indeks juga akan mengkonsumsi ruang yang relatif lebih sedikit. Ini sangat berguna dalam membuat beberapa indeks, dan juga dalam situasi di mana bagian dari data vektor telah dihapus dan merekonstruksi grafik HNSW akan membantu menciptakan koneksi node yang optimal untuk hasil pencarian vektor berkualitas tinggi.
Keluar dari Memori saat mengisi ulang
Mirip dengan operasi penulisan Valkey dan Redis OSS, isi ulang indeks dikenakan batasan. out-of-memory Jika memori mesin terisi saat pengisian ulang sedang berlangsung, semua isi ulang dijeda. Jika memori tersedia, proses pengurukan dilanjutkan. Dimungkinkan juga untuk menghapus dan mengindeks saat pengisian ulang dijeda karena kehabisan memori.
Transaksi
PerintahFT.CREATE,FT.DROPINDEX,FT.ALIASADD,FT.ALIASDEL, dan FT.ALIASUPDATE tidak dapat dieksekusi dalam konteks transaksional, yaitu, tidak di dalam MULTI/EXEC blok atau dalam LUA atau skrip FUNGSI.
