Terjemahan disediakan oleh mesin penerjemah. Jika konten terjemahan yang diberikan bertentangan dengan versi bahasa Inggris aslinya, utamakan versi bahasa Inggris.
Menyetel kueri Gremlin menggunakan explain dan profile
Anda sering dapat menyetel kueri Gremlin Anda di Amazon Neptunus untuk mendapatkan kinerja yang lebih baik, menggunakan informasi yang tersedia untuk Anda dalam laporan yang Anda dapatkan dari penjelasan dan profil Neptunus. APIs Untuk melakukannya, ia membantu untuk memahami bagaimana Neptune memproses traversals Gremlin.
penting
Perubahan dibuat di TinkerPop versi 3.4.11 yang meningkatkan kebenaran bagaimana kueri diproses, tetapi untuk saat ini terkadang dapat berdampak serius pada kinerja kueri.
Misalnya, kueri semacam ini dapat berjalan jauh lebih lambat:
g.V().hasLabel('airport'). order(). by(out().count(),desc). limit(10). out()
Simpul setelah langkah batas sekarang diambil dengan cara yang tidak optimal karena perubahan 3.4.11. TinkerPop Untuk menghindari hal ini, Anda dapat memodifikasi kueri dengan menambahkan langkah penghalang () kapan saja setelahorder().by(). Misalnya:
g.V().hasLabel('airport'). order(). by(out().count(),desc). limit(10). barrier(). out()
TinkerPop 3.4.11 diaktifkan di mesin Neptunus versi 1.0.5.0.
Memahami pemrosesan traversal Gremlin di Neptune
Ketika traversal Gremlin dikirim ke Neptune, ada tiga proses utama yang mengubah traversal menjadi rencana eksekusi yang mendasari untuk dieksekusi mesin. Ketiganya adalah parsing, conversion, dan optimization:
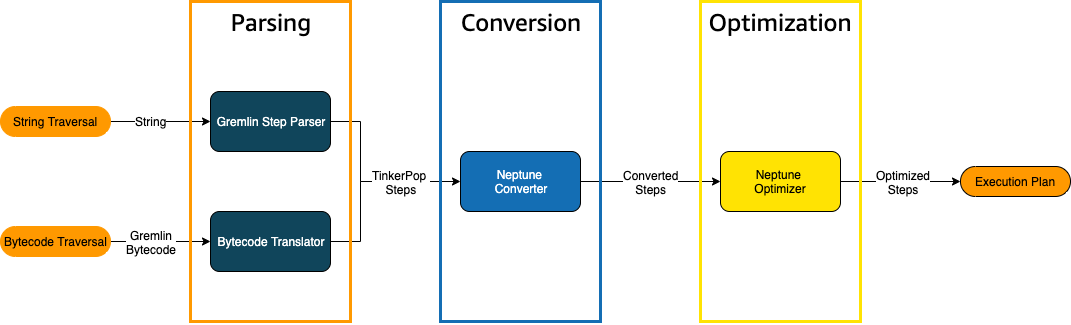
Proses penguraian traversal
Langkah pertama dalam memproses traversal adalah mengurainya ke dalam bahasa yang sama. Di Neptunus, bahasa umum itu adalah serangkaian langkah yang merupakan bagian TinkerPop dari API. TinkerPop
Anda dapat mengirim traversal Gremlin ke Neptune baik sebagai string atau sebagai bytecode. Titik akhir REST dan metode submit() driver klien Java mengirim traversals sebagai string, seperti dalam contoh ini:
client.submit("g.V()")
Driver aplikasi dan bahasa yang menggunakan Varian bahasa Gremlin (GLV)
Proses konversi traversal
Langkah kedua dalam memproses traversal adalah mengubah TinkerPop langkah-langkahnya menjadi serangkaian langkah Neptunus yang dikonversi dan tidak dikonversi. Sebagian besar langkah dalam bahasa kueri Apache TinkerPop Gremlin dikonversi ke langkah-langkah khusus Neptunus yang dioptimalkan untuk dijalankan pada mesin Neptunus yang mendasarinya. Ketika sebuah TinkerPop langkah tanpa ekuivalen Neptunus ditemui dalam traversal, langkah itu dan semua langkah selanjutnya dalam traversal diproses oleh mesin kueri. TinkerPop
Untuk informasi selengkapnya tentang langkah-langkah apa yang dapat dikonversi dalam keadaan apa, lihat Dukungan langkah Gremlin.
Proses optimasi traversal
Langkah terakhir dalam pemrosesan traversal adalah menjalankan serangkaian langkah dikonversi dan non-dikonversi melalui optimizer, untuk mencoba menentukan rencana eksekusi terbaik. Output dari optimasi ini adalah rencana eksekusi yang diproses mesin Neptune.
Menggunakan API explain Gremlin Neptune untuk menyetel kueri
API explain Neptune tidak sama dengan langkah explain() Gremlin. Ia mengembalikan rencana eksekusi akhir yang akan diproses mesin Neptune ketika mengeksekusi kueri. Karena tidak melakukan pemrosesan apa pun, ia mengembalikan rencana yang sama terlepas dari parameter yang digunakan, dan outputnya tidak mengandung statistik tentang eksekusi aktual.
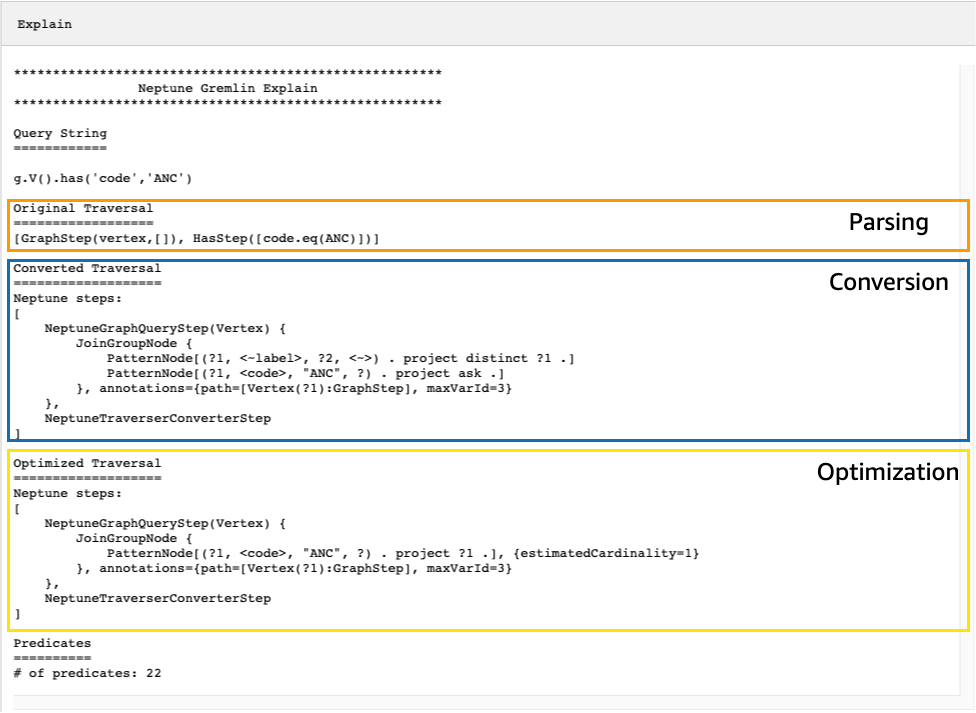
Pertimbangkan traversal sederhana berikut yang menemukan semua vertex bandara untuk Anchorage:
g.V().has('code','ANC')
Ada dua cara untuk menjalankan traversal ini melalui API explain Neptune. Cara pertama adalah untuk membuat panggilan REST ke titik akhir explain, seperti ini:
curl -X POST https://your-neptune-endpoint:port/gremlin/explain -d '{"gremlin":"g.V().has('code','ANC')"}'
Cara kedua adalah menggunakan workbench cell magic %%gremlin Neptune dengan parameter explain. Ini melewati traversal yang terkandung dalam tubuh sel ke API explain Neptune dan kemudian menampilkan output yang dihasilkan ketika Anda menjalankan sel:
%%gremlin explain g.V().has('code','ANC')
Output explain API yang dihasilkan menjelaskan rencana eksekusi Neptunus untuk traversal. Seperti yang bisa Anda lihat pada gambar di bawah ini, rencananya mencakup masing-masing dari 3 langkah dalam alur pemrosesan:
Penyetelan traversal dengan melihat langkah-langkah yang tidak dikonversi
Salah satu hal pertama yang harus dicari di output API explain Neptune adalah untuk langkah-langkah Gremlin yang tidak dikonversi ke langkah asli Neptune. Dalam rencana kueri, ketika langkah yang ditemui tidak dapat dikonversi ke langkah asli Neptune, langkah tersebut dan semua langkah berikutnya dalam rencana diproses oleh server Gremlin.
Dalam contoh di atas, semua langkah dalam traversal dikonversi. Mari kita periksa output API explain untuk traversal ini:
g.V().has('code','ANC').out().choose(hasLabel('airport'), values('code'), constant('Not an airport'))
Seperti yang bisa Anda lihat pada gambar di bawah ini, Neptune tidak bisa mengonversi langkah choose():
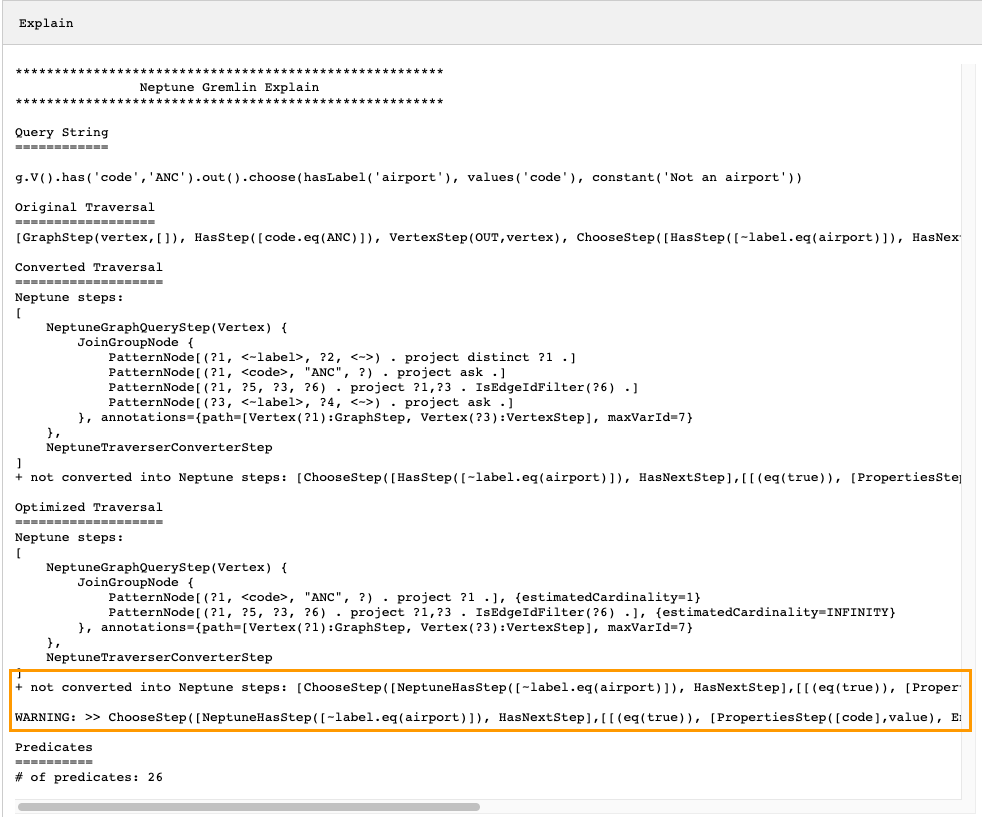
Ada beberapa hal yang dapat Anda lakukan untuk menyetel performa traversal. Yang pertama adalah menulis ulang sedemikian rupa untuk menghilangkan langkah yang tidak dapat dikonversi. Lainnya adalah memindahkan langkah ke akhir traversal sehingga semua langkah lain dapat dikonversi ke yang asli.
Rencana kueri dengan langkah-langkah yang tidak dikonversi tidak selalu perlu disetel. Jika langkah-langkah yang tidak dapat dikonversi berada di akhir traversal, dan terkait dengan bagaimana output diformat alih-alih bagaimana grafik ditraversalkan, langkah mungkin memiliki sedikit efek pada performa.
Hal lain yang harus dicari ketika memeriksa output dari API explain Neptune adalah langkah-langkah yang tidak menggunakan indeks. Traversal berikut menemukan semua bandara dengan penerbangan yang mendarat di Anchorage:
g.V().has('code','ANC').in().values('code')
Output dari API explain untuk traversal ini adalah:
******************************************************* Neptune Gremlin Explain ******************************************************* Query String ============ g.V().has('code','ANC').in().values('code') Original Traversal ================== [GraphStep(vertex,[]), HasStep([code.eq(ANC)]), VertexStep(IN,vertex), PropertiesStep([code],value)] Converted Traversal =================== Neptune steps: [ NeptuneGraphQueryStep(PropertyValue) { JoinGroupNode { PatternNode[(?1, <~label>, ?2, <~>) . project distinct ?1 .] PatternNode[(?1, <code>, "ANC", ?) . project ask .] PatternNode[(?3, ?5, ?1, ?6) . project ?1,?3 . IsEdgeIdFilter(?6) .] PatternNode[(?3, <~label>, ?4, <~>) . project ask .] PatternNode[(?3, ?7, ?8, <~>) . project ?3,?8 . ContainsFilter(?7 in (<code>)) .] }, annotations={path=[Vertex(?1):GraphStep, Vertex(?3):VertexStep, PropertyValue(?8):PropertiesStep], maxVarId=9} }, NeptuneTraverserConverterStep ] Optimized Traversal =================== Neptune steps: [ NeptuneGraphQueryStep(PropertyValue) { JoinGroupNode { PatternNode[(?1, <code>, "ANC", ?) . project ?1 .], {estimatedCardinality=1} PatternNode[(?3, ?5, ?1, ?6) . project ?1,?3 . IsEdgeIdFilter(?6) .], {estimatedCardinality=INFINITY} PatternNode[(?3, ?7=<code>, ?8, <~>) . project ?3,?8 .], {estimatedCardinality=7564} }, annotations={path=[Vertex(?1):GraphStep, Vertex(?3):VertexStep, PropertyValue(?8):PropertiesStep], maxVarId=9} }, NeptuneTraverserConverterStep ] Predicates ========== # of predicates: 26 WARNING: reverse traversal with no edge label(s) - .in() / .both() may impact query performance
Pesan WARNING di bagian bawah output terjadi karena langkah in() dalam traversal tidak dapat ditangani menggunakan salah satu dari 3 indeks yang Neptune pertahankan (lihat Bagaimana Pernyataan Diindeks di Neptune dan Pernyataan Gremlin di Neptune). Karena langkah in() tidak berisi filter edge, langkah itu tidak dapat diselesaikan menggunakan indeks SPOG, POGS atau GPSO. Sebaliknya, Neptune harus melakukan pemindaian serikat untuk menemukan vertex yang diminta, yang jauh lebih efisien.
Ada dua cara untuk menyetel traversal dalam situasi ini. Yang pertama adalah menambahkan satu atau lebih kriteria penyaringan ke langkah in() sehingga pencarian yang diindeks dapat digunakan untuk menyelesaikan kueri. Untuk contoh di atas, ini mungkin:
g.V().has('code','ANC').in('route').values('code')
Output dari API explain Neptune untuk traversal yang direvisi tidak lagi berisi pesan WARNING:
******************************************************* Neptune Gremlin Explain ******************************************************* Query String ============ g.V().has('code','ANC').in('route').values('code') Original Traversal ================== [GraphStep(vertex,[]), HasStep([code.eq(ANC)]), VertexStep(IN,[route],vertex), PropertiesStep([code],value)] Converted Traversal =================== Neptune steps: [ NeptuneGraphQueryStep(PropertyValue) { JoinGroupNode { PatternNode[(?1, <~label>, ?2, <~>) . project distinct ?1 .] PatternNode[(?1, <code>, "ANC", ?) . project ask .] PatternNode[(?3, ?5, ?1, ?6) . project ?1,?3 . IsEdgeIdFilter(?6) . ContainsFilter(?5 in (<route>)) .] PatternNode[(?3, <~label>, ?4, <~>) . project ask .] PatternNode[(?3, ?7, ?8, <~>) . project ?3,?8 . ContainsFilter(?7 in (<code>)) .] }, annotations={path=[Vertex(?1):GraphStep, Vertex(?3):VertexStep, PropertyValue(?8):PropertiesStep], maxVarId=9} }, NeptuneTraverserConverterStep ] Optimized Traversal =================== Neptune steps: [ NeptuneGraphQueryStep(PropertyValue) { JoinGroupNode { PatternNode[(?1, <code>, "ANC", ?) . project ?1 .], {estimatedCardinality=1} PatternNode[(?3, ?5=<route>, ?1, ?6) . project ?1,?3 . IsEdgeIdFilter(?6) .], {estimatedCardinality=32042} PatternNode[(?3, ?7=<code>, ?8, <~>) . project ?3,?8 .], {estimatedCardinality=7564} }, annotations={path=[Vertex(?1):GraphStep, Vertex(?3):VertexStep, PropertyValue(?8):PropertiesStep], maxVarId=9} }, NeptuneTraverserConverterStep ] Predicates ========== # of predicates: 26
Pilihan lain jika Anda menjalankan banyak traversals semacam ini adalah untuk menjalankan traversal tersebut dalam sebuah klaster DB Neptune yang memiliki indeks OSGP opsional diaktifkan (lihat Mengaktifkan Indeks OSGP). Mengaktifkan indeks OSGP memiliki kelemahan:
Indeks ini harus diaktifkan dalam klaster DB sebelum data dimuat.
Tingkat penyisipan untuk vertex dan edge dapat melambat hingga 23%.
Penggunaan penyimpanan akan meningkat sekitar 20%.
Kueri Baca yang menyebarkan permintaan di semua indeks mungkin telah meningkatkan latensi.
Memiliki indeks OSGP lebih masuk akal untuk serangkaian pola kueri terbatas, tetapi kecuali jika Anda sering menjalankannya, biasanya lebih baik untuk mencoba untuk memastikan bahwa traversals yang Anda tulis dapat diselesaikan menggunakan tiga indeks utama.
Menggunakan jumlah besar predikat
Neptune memperlakukan setiap label edge dan setiap nama properti vertex atau edge yang berbeda dalam grafik Anda sebagai predikat, dan dirancang secara default untuk bekerja dengan jumlah predikat berbeda yang relatif rendah. Bila Anda memiliki lebih dari beberapa ribu predikat dalam data grafik Anda, performa dapat menurun.
Output explain Neptune akan memperingatkan Anda jika hal ini terjadi:
Predicates ========== # of predicates: 9549 WARNING: high predicate count (# of distinct property names and edge labels)
Jika tidak nyaman untuk mengulang pengerjaan model data Anda untuk mengurangi jumlah label dan properti, dan karenanya jumlah predikatnya, cara terbaik untuk menyetel traversal adalah menjalankannya dalam sebuah klaster DB yang memiliki indeks OSGP diaktifkan, seperti yang dibahas di atas.
Menggunakan API profile Gremlin Neptune untuk menyetel traversal
API profile Neptune sangat berbeda dari langkah profile() Gremlin. Seperti halnya API explain, outputnya mencakup rencana kueri yang digunakan mesin Neptune saat mengeksekusi traversal. Selain itu, output profile menyertakan statistik eksekusi aktual untuk traversal, mengingat bagaimana parameternya ditetapkan.
Sekali lagi, ambil traversal sederhana yang menemukan semua vertex bandara untuk Anchorage:
g.V().has('code','ANC')
Seperti halnya dengan API explain, Anda dapat memanggil API profile menggunakan panggilan REST:
curl -X POST https://your-neptune-endpoint:port/gremlin/profile -d '{"gremlin":"g.V().has('code','ANC')"}'
Anda juga menggunakan workbench cell magic %%gremlin Neptune dengan parameter profile. Ini melewati traversal yang terkandung dalam tubuh sel ke API profile Neptune dan kemudian menampilkan output yang dihasilkan ketika Anda menjalankan sel:
%%gremlin profile g.V().has('code','ANC')
Output profile API yang dihasilkan berisi rencana eksekusi Neptunus untuk traversal dan statistik tentang eksekusi rencana, seperti yang Anda lihat pada gambar ini:
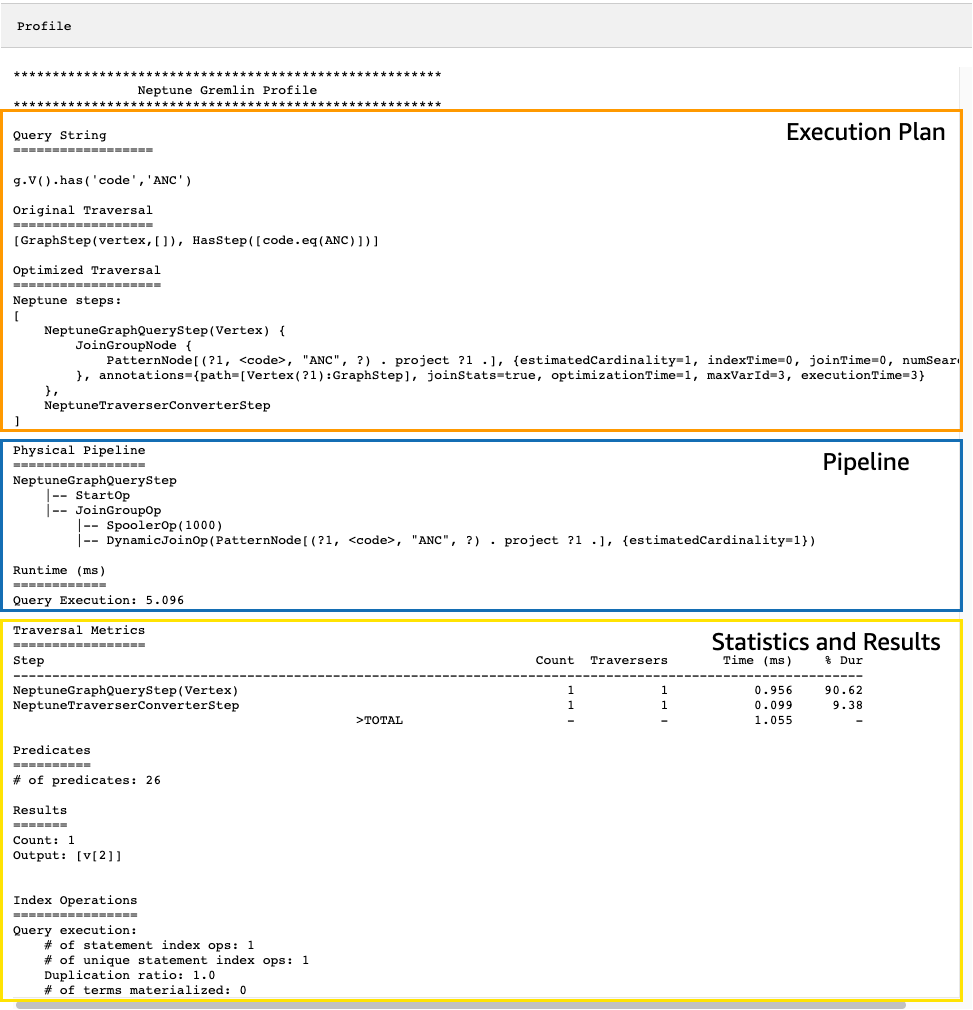
Dalam output profile, bagian rencana eksekusi hanya berisi rencana eksekusi akhir untuk traversal, bukan langkah menengahnya. Bagian alur berisi operasi alur fisik yang dilakukan serta waktu aktual (dalam milidetik) yang diperlukan eksekusi traversal. Metrik runtime sangat membantu dalam membandingkan waktu yang diperlukan dua versi traversal yang berbeda saat Anda mengoptimalkan mereka.
catatan
Runtime awal traversal umumnya lebih panjang dari runtime berikutnya, karena yang pertama menyebabkan data yang relevan untuk di-cache.
Bagian ketiga dari output profile berisi statistik eksekusi dan hasil traversal. Untuk melihat bagaimana informasi ini dapat berguna dalam menyetel traversal, pertimbangkan traversal berikut, yang menemukan setiap bandara yang namanya dimulai dengan “Anchora”, dan semua bandara yang dapat dijangkau dalam dua hop dari bandara tersebut, mengembalikan kode bandara, rute penerbangan, dan jarak:
%%gremlin profile g.withSideEffect("Neptune#fts.endpoint", "{your-OpenSearch-endpoint-URL"). V().has("city", "Neptune#fts Anchora~"). repeat(outE('route').inV().simplePath()).times(2). project('Destination', 'Route'). by('code'). by(path().by('code').by('dist'))
Metrik traversal di output API profile Neptune
Set pertama metrik yang tersedia di semua output profile adalah metrik traversal. Ini mirip dengan metrik langkah profile() Gremlin, dengan beberapa perbedaan:
Traversal Metrics ================= Step Count Traversers Time (ms) % Dur ------------------------------------------------------------------------------------------------------------- NeptuneGraphQueryStep(Vertex) 3856 3856 91.701 9.09 NeptuneTraverserConverterStep 3856 3856 38.787 3.84 ProjectStep([Destination, Route],[value(code), ... 3856 3856 878.786 87.07 PathStep([value(code), value(dist)]) 3856 3856 601.359 >TOTAL - - 1009.274 -
Kolom pertama dari tabel traversal-metrik mencantumkan langkah-langkah yang dijalankan oleh traversal. Dua langkah pertama umumnya adalah langkah-langkah khusus Neptune, NeptuneGraphQueryStep dan NeptuneTraverserConverterStep.
NeptuneGraphQueryStep mewakili waktu eksekusi untuk seluruh bagian dari traversal yang dapat dikonversi dan dieksekusi secara native oleh mesin Neptune.
NeptuneTraverserConverterStepmewakili proses mengubah output dari langkah-langkah yang dikonversi menjadi TinkerPop traversers yang memungkinkan langkah-langkah yang tidak dapat dikonversi langkah-langkah, jika ada, untuk diproses, atau untuk mengembalikan hasil dalam format -kompatibel. TinkerPop
Pada contoh di atas, kita memiliki beberapa langkah yang tidak dikonversi, jadi kita melihat bahwa masing-masing TinkerPop langkah ini (ProjectStep,PathStep) kemudian muncul sebagai baris dalam tabel.
Dalam contoh kita ada 3.856 simpul dan 3.856 traversers dikembalikan olehNeptuneGraphQueryStep, dan angka-angka ini tetap sama sepanjang pengolahan yang tersisa karenaProjectStepdanPathStepmemformat hasil, tidak menyaring mereka.
catatan
Tidak seperti TinkerPop, mesin Neptunus tidak mengoptimalkan kinerja dengan menumpuk di langkah-langkahnya. NeptuneGraphQueryStep NeptuneTraverserConverterStep Bulking adalah TinkerPop operasi yang menggabungkan pelintas pada simpul yang sama untuk mengurangi overhead operasional, dan itulah yang menyebabkan dan angka berbeda. Count Traversers Karena bulking hanya terjadi pada langkah-langkah yang didelegasikan Neptunus, dan bukan pada langkah-langkah yang TinkerPop ditangani Neptunus secara asli, kolom dan kolom jarang berbeda. Count Traverser
Kolom Waktu melaporkan jumlah milidetik yang diambil langkah, dan kolom % Dur melaporkan berapa persen dari total waktu pemrosesan yang diambil langkah. Ini adalah metrik yang memberi tahu Anda tempat untuk memfokuskan upaya penyetelan dengan menunjukkan langkah-langkah yang memakan waktu paling lama.
Metrik operasi indeks di output API profile Neptune
Satu set metrik dalam output dari API profil Neptune adalah operasi indeks:
Index Operations ================ Query execution: # of statement index ops: 23191 # of unique statement index ops: 5960 Duplication ratio: 3.89 # of terms materialized: 0
Laporan ini:
Jumlah total pencarian indeks.
Jumlah pencarian indeks unik yang dilakukan.
Rasio total pencarian indeks ke yang unik. Rasio yang lebih rendah menunjukkan redundansi yang lebih sedikit.
Jumlah istilah terwujud dari kamus istilah.
Metrik repeat di output API profile Neptune
Jika traversal Anda menggunakan repeat() seperti pada contoh di atas, maka bagian yang berisi metrik repeat muncul di output profile:
Repeat Metrics ============== Iteration Visited Output Until Emit Next ------------------------------------------------------ 0 2 0 0 0 2 1 53 0 0 0 53 2 3856 3856 3856 0 0 ------------------------------------------------------ 3911 3856 3856 0 55
Laporan ini:
Jumlah loop untuk satu baris (kolom
Iteration).Jumlah elemen yang dikunjungi oleh loop (kolom
Visited).Jumlah elemen yang dioutput oleh loop (kolom
Output).Elemen terakhir yang dioutput oleh loop (kolom
Until).Jumlah elemen yang dikeluarkan oleh loop (kolom
Emit).Jumlah elemen yang dilewatkan dari loop ke loop berikutnya (kolom
Next).
Metrik repeat ini sangat membantu dalam memahami faktor percabangan traversal Anda, untuk mendapatkan kesan berapa banyak pekerjaan yang sedang dilakukan oleh database. Anda dapat menggunakan angka-angka ini untuk mendiagnosis masalah performa, terutama ketika traversal yang sama berkinerja berbeda secara dramatis dengan parameter lainnya.
Metrik pencarian teks lengkap di output API profile Neptune
Ketika sebuah traversal menggunakan pencarian teks penuh seperti dalam contoh di atas, maka bagian yang berisi metrik pencarian teks lengkap (FTS) muncul di output profile:
FTS Metrics ============== SearchNode[(idVar=?1, query=Anchora~, field=city) . project ?1 .], {endpoint=your-OpenSearch-endpoint-URL, incomingSolutionsThreshold=1000, estimatedCardinality=INFINITY, remoteCallTimeSummary=[total=65, avg=32.500000, max=37, min=28], remoteCallTime=65, remoteCalls=2, joinTime=0, indexTime=0, remoteResults=2} 2 result(s) produced from SearchNode above
Ini menunjukkan kueri yang dikirim ke klaster ElasticSearch (ES) dan melaporkan beberapa metrik tentang interaksi yang dapat membantu Anda menentukan masalah kinerja ElasticSearch yang berkaitan dengan penelusuran teks lengkap:
-
Ringkasan informasi tentang panggilan ke ElasticSearch indeks:
Jumlah total milidetik yang dibutuhkan oleh semua remoteCalls untuk memenuhi kueri (
total).Jumlah rata-rata milidetik yang dihabiskan di remoteCall (
avg).Jumlah minimum milidetik yang dihabiskan di remoteCall (
min).Jumlah maksimum milidetik yang dihabiskan di remoteCall (
max).
Total waktu yang dikonsumsi oleh RemoteCalls to ElasticSearch ()
remoteCallTime.Jumlah RemoteCalls dibuat untuk ElasticSearch ()
remoteCalls.Jumlah milidetik yang dihabiskan dalam gabungan ElasticSearch hasil ()
joinTime.Jumlah milidetik yang dihabiskan dalam pencarian indeks (
indexTime).Jumlah total hasil yang dikembalikan oleh ElasticSearch (
remoteResults).
