Terjemahan disediakan oleh mesin penerjemah. Jika konten terjemahan yang diberikan bertentangan dengan versi bahasa Inggris aslinya, utamakan versi bahasa Inggris.
Mempertahankan tabel dengan menggunakan pemadatan
Iceberg mencakup fitur yang memungkinkan Anda untuk melakukan operasi pemeliharaan tabel
Pemadatan gunung es
Di Iceberg, Anda dapat menggunakan pemadatan untuk melakukan empat tugas:
-
Menggabungkan file kecil menjadi file yang lebih besar yang umumnya berukuran lebih dari 100 MB. Teknik ini dikenal sebagai bin packing.
-
Menggabungkan menghapus file dengan file data. Hapus file dihasilkan oleh pembaruan atau penghapusan yang menggunakan merge-on-read pendekatan.
-
(Re) menyortir data sesuai dengan pola kueri. Data dapat ditulis tanpa urutan apapun atau dengan urutan sortir yang cocok untuk menulis dan update.
-
Mengelompokkan data dengan menggunakan kurva pengisian ruang untuk mengoptimalkan pola kueri yang berbeda, terutama penyortiran urutan-z.
Pada AWS, Anda dapat menjalankan operasi pemadatan dan pemeliharaan tabel untuk Iceberg melalui Amazon Athena atau dengan menggunakan Spark di Amazon EMR atau. AWS Glue
Saat Anda menjalankan pemadatan dengan menggunakan prosedur rewrite_data_files
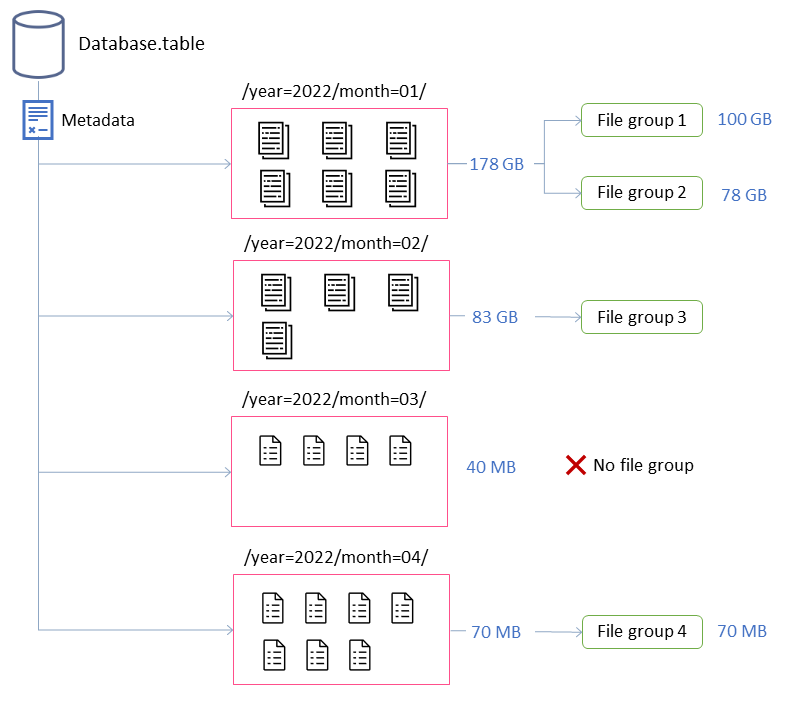
Dalam contoh ini, tabel Iceberg terdiri dari empat partisi. Setiap partisi memiliki ukuran dan jumlah file yang berbeda. Jika Anda memulai aplikasi Spark untuk menjalankan pemadatan, aplikasi membuat total empat grup file untuk diproses. Grup file adalah abstraksi Gunung Es yang mewakili kumpulan file yang akan diproses oleh satu pekerjaan Spark. Artinya, aplikasi Spark yang menjalankan pemadatan akan menciptakan empat pekerjaan Spark untuk memproses data.
Menyetel perilaku pemadatan
Properti kunci berikut mengontrol bagaimana file data dipilih untuk pemadatan:
-
MAX_FILE_GROUP_SIZE_BYTES
menetapkan batas data untuk satu grup file (Spark job) pada 100 GB secara default. Properti ini sangat penting untuk tabel tanpa partisi atau tabel dengan partisi yang menjangkau ratusan gigabyte. Dengan menetapkan batas ini, Anda dapat memecah operasi untuk merencanakan pekerjaan dan membuat kemajuan sekaligus mencegah kehabisan sumber daya di cluster. Catatan: Setiap grup file diurutkan secara terpisah. Oleh karena itu, jika Anda ingin melakukan pengurutan tingkat partisi, Anda harus menyesuaikan batas ini agar sesuai dengan ukuran partisi.
-
MIN_FILE_SIZE_BYTES atau MIN_FILE_SIZE_DEFAULT_RATIO
default ke 75 persen dari ukuran file target yang ditetapkan pada tingkat tabel. Misalnya, jika tabel memiliki ukuran target 512 MB, file apa pun yang lebih kecil dari 384 MB disertakan dalam kumpulan file yang akan dipadatkan. -
MAX_FILE_SIZE_BYTES atau MAX_FILE_SIZE_DEFAULT_RATIO
default 180 persen dari ukuran file target . Seperti dua properti yang mengatur ukuran file minimum, properti ini digunakan untuk mengidentifikasi file kandidat untuk pekerjaan pemadatan. -
MIN_INPUT_FILES
menentukan jumlah minimum file yang akan dipadatkan jika ukuran partisi tabel lebih kecil dari ukuran file target. Nilai properti ini digunakan untuk menentukan apakah layak untuk memadatkan file berdasarkan jumlah file (default ke 5). -
DELETE_FILE_THRESHOLD
menentukan jumlah minimum operasi penghapusan untuk file sebelum disertakan dalam pemadatan. Kecuali Anda menentukan sebaliknya, pemadatan tidak menggabungkan file hapus dengan file data. Untuk mengaktifkan fungsi ini, Anda harus menetapkan nilai ambang dengan menggunakan properti ini. Ambang batas ini khusus untuk file data individual, jadi jika Anda mengaturnya ke 3, file data akan ditulis ulang hanya jika ada tiga atau lebih file hapus yang mereferensikannya.
Properti ini memberikan wawasan tentang pembentukan kelompok file dalam diagram sebelumnya.
Misalnya, partisi berlabel month=01 mencakup dua grup file karena melebihi batasan ukuran maksimum 100 GB. Sebaliknya, month=02 partisi berisi satu grup file karena di bawah 100 GB. month=03Partisi tidak memenuhi persyaratan file input minimum default dari lima file. Akibatnya, itu tidak akan dipadatkan. Terakhir, meskipun month=04 partisi tidak berisi data yang cukup untuk membentuk satu file dengan ukuran yang diinginkan, file akan dipadatkan karena partisi mencakup lebih dari lima file kecil.
Anda dapat mengatur parameter ini untuk Spark yang berjalan di Amazon AWS Glue EMR atau. Untuk Amazon Athena, Anda dapat mengelola properti serupa dengan menggunakan properti tabel yang dimulai dengan awalanoptimize_).
Menjalankan pemadatan dengan Spark di Amazon EMR atau AWS Glue
Bagian ini menjelaskan cara mengukur cluster Spark dengan benar untuk menjalankan utilitas pemadatan Iceberg. Contoh berikut menggunakan Amazon EMR Tanpa Server, tetapi Anda dapat menggunakan metodologi yang sama di Amazon EMR di Amazon atau Amazon EKS, EC2 atau di. AWS Glue
Anda dapat memanfaatkan korelasi antara grup file dan pekerjaan Spark untuk merencanakan sumber daya cluster. Untuk memproses grup file secara berurutan, dengan mempertimbangkan ukuran maksimum 100 GB per grup file, Anda dapat mengatur properti Spark berikut:
-
spark.dynamicAllocation.enabled=FALSE -
spark.executor.memory=20 GB -
spark.executor.instances=5
Jika Anda ingin mempercepat pemadatan, Anda dapat menskalakan secara horizontal dengan meningkatkan jumlah grup file yang dipadatkan secara paralel. Anda juga dapat menskalakan EMR Amazon dengan menggunakan penskalaan manual atau dinamis.
-
Penskalaan secara manual (misalnya, dengan faktor 4)
-
MAX_CONCURRENT_FILE_GROUP_REWRITES=4(faktor kami) -
spark.executor.instances=5(nilai yang digunakan dalam contoh) x4(faktor kami) =20 -
spark.dynamicAllocation.enabled=FALSE
-
-
Penskalaan dinamis
-
spark.dynamicAllocation.enabled=TRUE(default, tidak ada tindakan yang diperlukan) -
MAX_CONCURRENT_FILE_GROUP_REWRITES
= N(sejajarkan nilai ini denganspark.dynamicAllocation.maxExecutors, yang 100 secara default; berdasarkan konfigurasi pelaksana dalam contoh, Anda dapat mengatur ke 20)N
Ini adalah pedoman untuk membantu mengukur cluster. Namun, Anda juga harus memantau kinerja pekerjaan Spark Anda untuk menemukan pengaturan terbaik untuk beban kerja Anda.
-
Menjalankan pemadatan dengan Amazon Athena
Athena menawarkan implementasi utilitas pemadatan Iceberg sebagai fitur terkelola melalui pernyataan OPTIMIZE. Anda dapat menggunakan pernyataan ini untuk menjalankan pemadatan tanpa harus mengevaluasi infrastruktur.
Pernyataan ini mengelompokkan file kecil ke dalam file yang lebih besar dengan menggunakan algoritma pengemasan bin dan menggabungkan file hapus dengan file data yang ada. Untuk mengelompokkan data menggunakan pengurutan hierarkis atau pengurutan urutan z, gunakan Spark di Amazon EMR atau. AWS Glue
Anda dapat mengubah perilaku default OPTIMIZE pernyataan pada pembuatan tabel dengan meneruskan properti tabel dalam CREATE TABLE pernyataan, atau setelah pembuatan tabel dengan menggunakan ALTER TABLE pernyataan. Untuk nilai default, lihat dokumentasi Athena.
Rekomendasi untuk menjalankan pemadatan
Kasus penggunaan |
Rekomendasi |
|---|---|
Menjalankan pemadatan kemasan bin berdasarkan jadwal |
|
Menjalankan pemadatan pengepakan bin berdasarkan peristiwa |
|
Menjalankan pemadatan untuk mengurutkan data |
|
Menjalankan pemadatan untuk mengelompokkan data menggunakan pengurutan urutan z |
|
Menjalankan pemadatan pada partisi yang mungkin diperbarui oleh aplikasi lain karena data yang datang terlambat |
|
Menjalankan pemadatan pada partisi dingin (partisi data yang tidak lagi menerima penulisan aktif) |
|
