Terjemahan disediakan oleh mesin penerjemah. Jika konten terjemahan yang diberikan bertentangan dengan versi bahasa Inggris aslinya, utamakan versi bahasa Inggris.
Danau data modern
Kasus penggunaan lanjutan di danau data modern
Data lake menawarkan salah satu opsi terbaik untuk menyimpan data dalam hal biaya, skalabilitas, dan fleksibilitas. Anda dapat menggunakan data lake untuk menyimpan volume besar data terstruktur dan tidak terstruktur dengan biaya rendah, dan menggunakan data ini untuk berbagai jenis beban kerja analitik, mulai dari pelaporan intelijen bisnis hingga pemrosesan data besar, analitik real-time, pembelajaran mesin, dan kecerdasan buatan generatif (AI), untuk membantu memandu keputusan yang lebih baik.
Terlepas dari manfaat ini, data lake pada awalnya tidak dirancang dengan kemampuan seperti database. Data lake tidak memberikan dukungan untuk semantik pemrosesan atomisitas, konsistensi, isolasi, dan daya tahan (ACID), yang mungkin Anda perlukan untuk mengoptimalkan dan mengelola data Anda secara efektif dalam skala di ratusan atau ribuan pengguna dengan menggunakan banyak teknologi yang berbeda. Data lake tidak menyediakan dukungan asli untuk fungsionalitas berikut:
-
Melakukan pembaruan dan penghapusan tingkat rekor yang efisien saat data berubah dalam bisnis Anda
-
Mengelola kinerja kueri saat tabel tumbuh menjadi jutaan file dan ratusan ribu partisi
-
Memastikan konsistensi data di beberapa penulis dan pembaca bersamaan
-
Mencegah korupsi data saat operasi penulisan gagal di tengah operasi
-
Skema tabel yang berkembang dari waktu ke waktu tanpa (sebagian) menulis ulang kumpulan data
Tantangan-tantangan ini telah menjadi sangat lazim dalam kasus penggunaan seperti penanganan pengambilan data perubahan (CDC) atau kasus penggunaan yang berkaitan dengan privasi, penghapusan data, dan streaming konsumsi data, yang dapat menghasilkan tabel yang kurang optimal.
Data lake yang menggunakan tabel HIVE-format tradisional mendukung operasi penulisan hanya untuk seluruh file. Ini membuat pembaruan dan penghapusan sulit diterapkan, memakan waktu, dan mahal. Selain itu, kontrol konkurensi dan jaminan yang ditawarkan dalam sistem yang sesuai dengan ACID diperlukan untuk memastikan integritas dan konsistensi data.
Pengantar Apache Iceberg
Apache Iceberg adalah format tabel open-source yang menyediakan fitur dalam tabel data lake yang secara historis hanya tersedia di database atau gudang data. Ini dirancang untuk skala dan kinerja, dan sangat cocok untuk mengelola tabel yang lebih dari ratusan gigabyte. Beberapa fitur utama dari tabel Iceberg adalah:
-
Hapus, perbarui, dan gabungkan.Iceberg mendukung perintah SQL standar untuk pergudangan data untuk digunakan dengan tabel danau data.
-
Perencanaan pemindaian cepat dan penyaringan lanjutan. Iceberg menyimpan metadata seperti partisi dan statistik tingkat kolom yang dapat digunakan oleh mesin untuk mempercepat perencanaan dan menjalankan kueri.
-
Evolusi skema penuh. Iceberg mendukung penambahan, penurunan, pembaruan, atau penggantian nama kolom tanpa efek samping.
-
Evolusi partisi. Anda dapat memperbarui tata letak partisi tabel saat volume data atau pola kueri berubah. Iceberg mendukung perubahan kolom tempat tabel dipartisi, atau menambahkan kolom ke, atau menghapus kolom dari, partisi komposit.
-
Partisi tersembunyi.Fitur ini mencegah membaca partisi yang tidak perlu secara otomatis. Ini menghilangkan kebutuhan pengguna untuk memahami detail partisi tabel atau menambahkan filter tambahan ke kueri mereka.
-
Versi rollback. Pengguna dapat dengan cepat memperbaiki masalah dengan kembali ke keadaan pra-transaksi.
-
Perjalanan waktu. Pengguna dapat menanyakan versi tabel tertentu sebelumnya.
-
Isolasi yang dapat diserialisasi. Perubahan tabel bersifat atomik, sehingga pembaca tidak pernah melihat perubahan sebagian atau tidak berkomitmen.
-
Penulis bersamaan. Iceberg menggunakan konkurensi optimis untuk memungkinkan beberapa transaksi berhasil. Jika terjadi konflik, salah satu penulis harus mencoba kembali transaksi.
-
Buka format file. Iceberg mendukung beberapa format file open source, termasuk Apache Parquet, Apache
Avro, dan Apache ORC .
Singkatnya, data lake yang menggunakan format Iceberg mendapat manfaat dari konsistensi transaksional, kecepatan, skala, dan evolusi skema. Untuk informasi lebih lanjut tentang ini dan fitur Iceberg lainnya, lihat dokumentasi Apache
AWS dukungan untuk Apache Iceberg
Apache Iceberg didukung oleh kerangka kerja pemrosesan data open source yang populer dan oleh seperti Layanan AWS Amazon EMR, Amazon Athena,
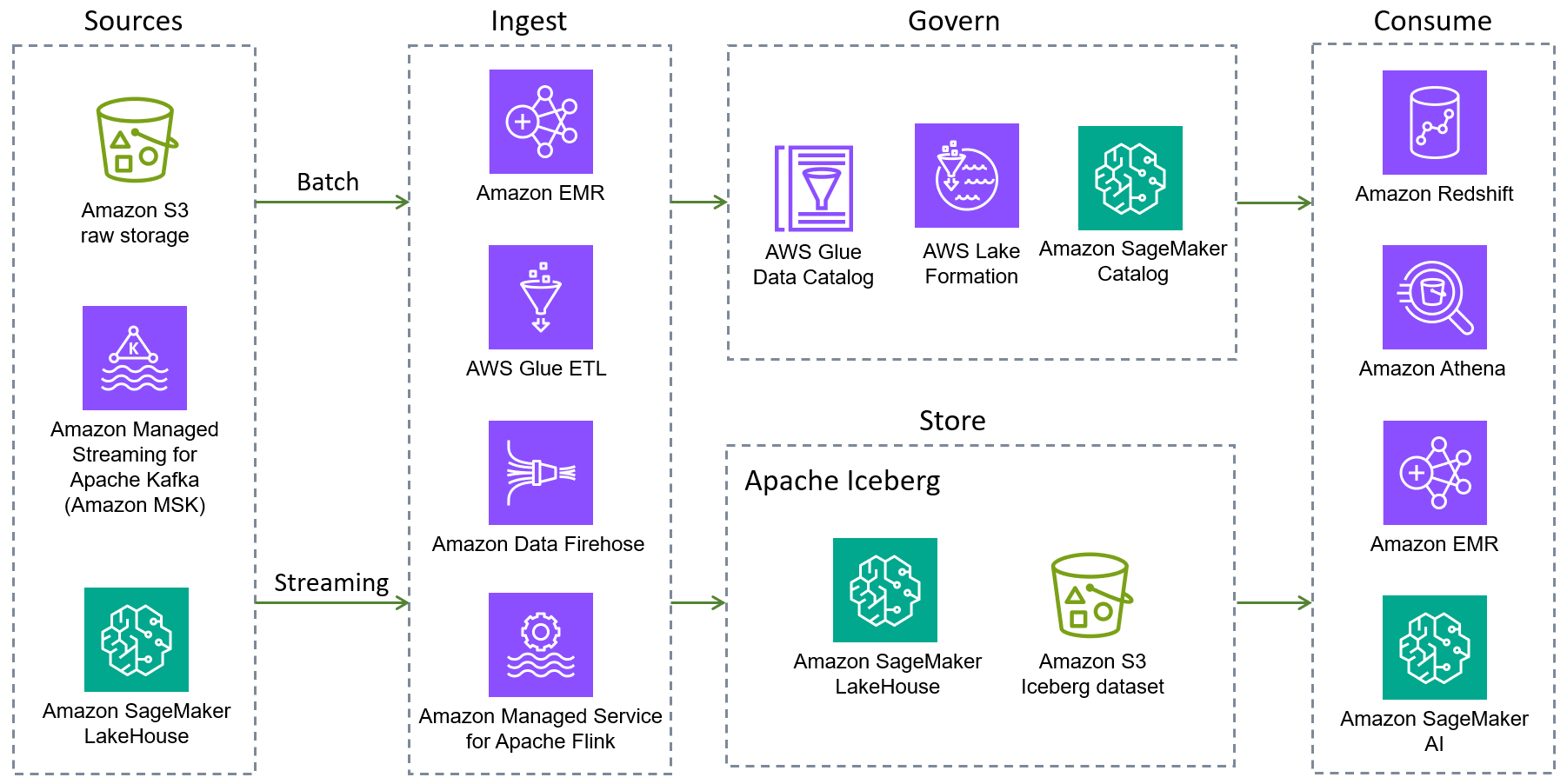
Berikut ini Layanan AWS menyediakan integrasi Iceberg asli. Ada tambahan Layanan AWS yang dapat berinteraksi dengan Iceberg, baik secara tidak langsung atau dengan mengemas perpustakaan Iceberg.
-
Amazon S3 adalah tempat terbaik untuk membangun data lake karena daya tahan, ketersediaan, skalabilitas, keamanan, kepatuhan, dan kemampuan auditnya. Iceberg dirancang dan dibangun untuk berinteraksi dengan Amazon S3 dengan mulus, dan memberikan dukungan untuk banyak fitur Amazon S3 seperti yang tercantum dalam dokumentasi Iceberg.
-
Amazon EMR adalah solusi data besar untuk pemrosesan data skala petabyte, analitik interaktif, dan pembelajaran mesin dengan menggunakan kerangka kerja open source seperti Apache Spark, Flink, Trino, dan Hive. Amazon EMR dapat berjalan pada cluster Amazon Elastic Compute Cloud (Amazon EC2) yang disesuaikan, Amazon Elastic Kubernetes Service (Amazon EKS), atau Amazon EMR Tanpa Server. AWS Outposts
-
Amazon Athena adalah layanan analitik interaktif tanpa server yang dibangun di atas kerangka kerja open source. Ini mendukung format tabel terbuka dan file dan menyediakan cara yang disederhanakan dan fleksibel untuk menganalisis petabyte data di mana ia tinggal. Athena menyediakan dukungan asli untuk membaca, perjalanan waktu, menulis, dan kueri DDL untuk Iceberg dan menggunakan metastore for the Iceberg. AWS Glue Data Catalog
-
Amazon Redshift adalah gudang data cloud skala petabyte yang mendukung opsi penerapan berbasis cluster dan tanpa server. Amazon Redshift Spectrum dapat menanyakan tabel eksternal yang terdaftar dengan AWS Glue Data Catalog dan disimpan di Amazon S3. Redshift Spectrum juga menyediakan dukungan untuk format penyimpanan Iceberg.
-
AWS Glueadalah layanan integrasi data tanpa server yang memudahkan untuk menemukan, menyiapkan, memindahkan, dan mengintegrasikan data dari berbagai sumber untuk analitik, pembelajaran mesin (ML), dan pengembangan aplikasi. AWS Glue 3.0 dan versi yang lebih baru mendukung kerangka Iceberg untuk data lake. Anda dapat menggunakan AWS Glue untuk melakukan operasi baca dan tulis pada tabel Iceberg di Amazon S3, atau bekerja dengan tabel Iceberg dengan menggunakan. AWS Glue Data Catalog Operasi tambahan seperti insert, update, Spark query, dan Spark write juga didukung.
-
AWS Glue Data Catalogmenyediakan layanan katalog data yang kompatibel dengan metastore Hive yang mendukung tabel Iceberg.
-
Perayap AWS Gluemenyediakan otomatisasi untuk mendaftarkan tabel Iceberg di. AWS Glue Data Catalog
-
Amazon Data Firehose adalah layanan yang dikelola sepenuhnya untuk mengirimkan data streaming waktu nyata ke tujuan seperti Amazon S3, Amazon Redshift, Layanan Amazon, Amazon Tanpa Server, Splunk, tabel Apache Iceberg, dan titik akhir HTTP atau HTTP kustom apa pun yang dimiliki oleh penyedia OpenSearch layanan pihak ketiga yang didukung, termasuk Datadog, Dynatrace,, MongoDB, New Relic, Coralogigie X, dan Elastis. OpenSearch LogicMonitor Dengan Firehose, Anda tidak perlu menulis aplikasi atau mengelola sumber daya. Anda mengonfigurasi produsen data Anda untuk mengirim data ke Firehose, dan secara otomatis mengirimkan data ke tujuan yang Anda tentukan. Anda juga dapat mengonfigurasi Firehose untuk mengubah data Anda sebelum mengirimkannya.
-
Amazon SageMaker AI mendukung penyimpanan set fitur di Amazon SageMaker AI Feature Store dengan menggunakan format Iceberg.
-
AWS Lake Formationmemberikan izin kontrol akses kasar dan halus untuk mengakses data, termasuk tabel Iceberg yang dikonsumsi oleh Athena atau Amazon Redshift. Untuk mempelajari lebih lanjut tentang dukungan izin untuk tabel Gunung Es, lihat dokumentasi Lake Formation.
AWS memiliki berbagai layanan yang mendukung Iceberg, tetapi mencakup semua layanan ini berada di luar cakupan panduan ini. Bagian berikut mencakup Spark (batch dan streaming terstruktur) di Amazon EMR AWS Glue dan, serta Amazon Athena SQL. Bagian berikut memberikan pandangan singkat pada dukungan Iceberg di Athena SQL.
