Terjemahan disediakan oleh mesin penerjemah. Jika konten terjemahan yang diberikan bertentangan dengan versi bahasa Inggris aslinya, utamakan versi bahasa Inggris.
Status Aurora dan mesin status Step Functions
Bagian ini mencakup proses dan mesin status khusus untuk gagal dan gagal kembali cluster Amazon Aurora. Cluster dikonfigurasi sebagai database global.
catatan
Untuk tujuan demonstrasi, contoh ini menggunakan Aurora MySQL-Compatible Edition. Anda dapat menggunakan langkah serupa untuk Edisi yang kompatibel dengan Aurora PostgreSQL.
Keadaan mantap
Dalam kondisi mapan, database global yang kompatibel dengan Amazon Aurora MySQL (dr-globaldb-cluster-mysql) telah dibuat dengan dua cluster DB. Cluster DB pertama (db-cluster-01) telah dibuat di primary Wilayah AWS
(us-east-1) untuk melayani beban kerja baca/tulis. Cluster DB kedua (db-cluster-02) telah dibuat di Region sekunder (us-west-2) untuk server beban kerja hanya-baca.
Selain menyediakan solusi DR, Anda dapat mengurangi beban pada cluster DB primer Anda dengan merutekan kueri baca dari aplikasi Anda ke cluster DB sekunder. Masing-masing cluster ini berisi satu instance database yang disebut dbcluster-01-use1-instance-1 dandbcluster-02-usw2-instance-2, masing-masing.
State kejadian
Dengan menggunakan database global Amazon Aurora, Anda dapat merencanakan dan memulihkan diri dari bencana dengan cukup cepat. Pemulihan dari bencana biasanya diukur menggunakan nilai untuk tujuan waktu pemulihan (RTO) dan tujuan titik pemulihan (RPO). Untuk informasi selengkapnya, lihat Menggunakan switchover atau failover dalam database global Amazon Aurora.
Dengan database global Aurora, ada dua pendekatan berbeda untuk failover:
-
Switchover (failover terencana terkelola)
-
Failover (failover manual yang tidak direncanakan, atau lepaskan dan promosikan)
Peralihan
Switchover ditujukan untuk lingkungan yang terkendali, seperti pemeliharaan operasional dan prosedur operasional terencana lainnya. Dengan menggunakan failover terencana terkelola, Anda dapat memindahkan cluster DB utama dari database global Aurora Anda ke salah satu Wilayah sekunder. Karena switchover menunggu sampai cluster DB sekunder disinkronkan dengan database utama, RPO adalah 0 (tidak ada kehilangan data). Untuk mempelajari selengkapnya, lihat Melakukan switchover untuk database global Amazon Aurora.
Mesin dr-orchestrator-stepfunction-FAILOVER status dipanggil selama status peristiwa untuk mengalihkan cluster utama Anda ke Region sekunder yang Anda pilih (us-west-2).
Untuk melakukan peralihan, lakukan hal berikut:
-
Masuk ke AWS Management Console.
-
Ubah Wilayah ke Wilayah DR (
us-west-2). -
Arahkan ke Layanan, dan pilih Step Functions.
-
Arahkan ke mesin
dr-orchestrator-stepfunction-FAILOVERnegara. -
Pilih Mulai eksekusi, dan masukkan kode JSON berikut di
Input - optionalbagian:{ "StatePayload": [ { "layer": 1, "resources": [ { "resourceType": "PlannedFailoverAurora", "resourceName": "Switchover (planned failover) of Amazon Aurora global databases (MySQL)", "parameters": { "GlobalClusterIdentifier": "!Import dr-globaldb-cluster-mysql-global-identifier", "DBClusterIdentifier": "!Import dr-globaldb-cluster-mysql-cluster-identifier" } } ] } ] } -
Mesin
dr-orchestrator-stepfunction-FAILOVERstatus membaca tipe sumber daya sebagaiPlannedFailoverAuroraMySQL, dan memanggil mesindr-orchestrator-stepfunction-planned-Aurora-failoverstatus untuk gagal atas database global Aurora.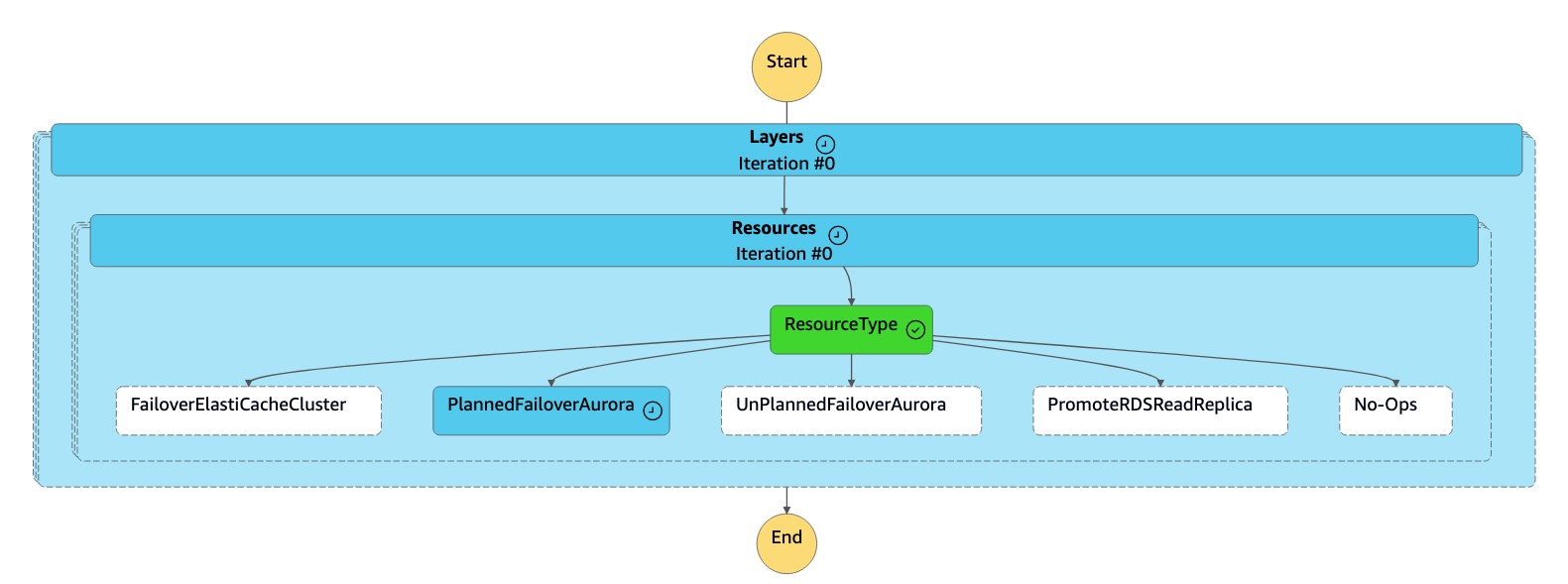
-
Mesin
dr-orchestrator-stepfunction-planned-Aurora-failoverstate melakukan langkah-langkah berikut untuk mengalihkan peran database global yang kompatibel dengan Aurora MySQL.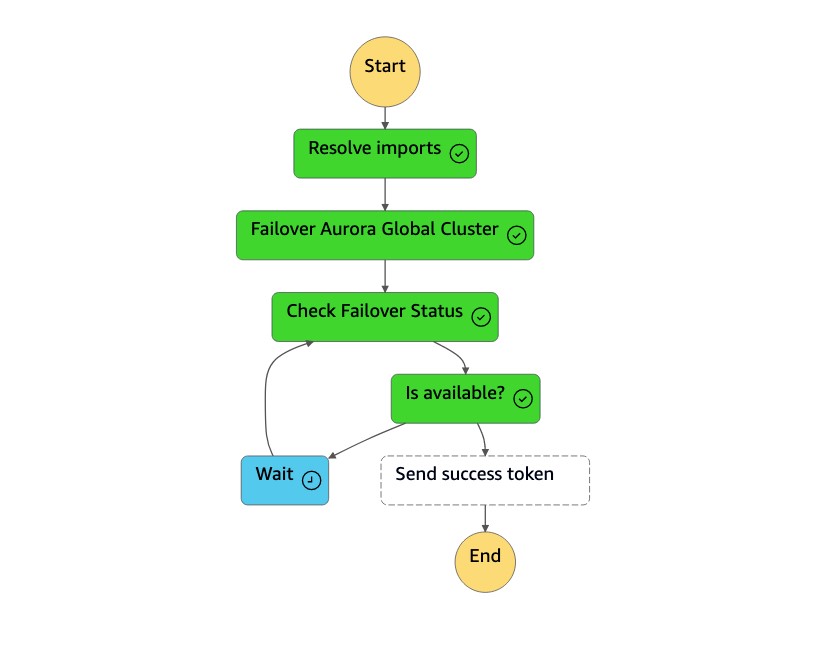
Langkah Deskripsi Nilai yang Diharapkan Selesaikan impor Fungsi Lambda menggantikan !Import <variable name>nilai dengan nama sebenarnya."!Import dr-globaldb-cluster-mysql-global-identifier"digantikan oleh"dr-globaldb-cluster-mysql".Gugus Global Failover Aurora Fungsi Lambda memanggil failover_global_cluster Boto3 API untuk gagal melalui database global Aurora. { 'GlobalCluster': { 'GlobalClusterIdentifier': 'dr-globaldb-cluster-mysql', 'GlobalClusterResourceId': 'cluster-cce7f9bec2846db4', 'GlobalClusterArn': 'arn:aws:rds::xxx', 'Status': 'failing-over', .... .... } }Periksa Status Failover Fungsi Lambda memanggil describe_db_clusters Boto3 API untuk memeriksa status failover. memodifikasi, tersedia Kirim token sukses Fungsi Lambda memanggil send_task_success Boto3 API dan mengirimkan token sukses kembali ke mesin status. DR Orchestrator FailoverH7x /83p1e0 RiCdLtd K9mBvkzsp7d9yrt1w dMccoxlzFhglsdkzp -
Arahkan ke konsol Amazon RDS. Di bawah Status, nilai untuk database global Aurora akan berubah dari Tersedia menjadi Switching over atau Modifying.
-
Setelah mesin
dr-orchestrator-stepfunction-planned-Aurora-failovernegara selesai, ia mengirimkan token sukses kembali ke mesindr-orchestrator-stepfunction-FAILOVERnegara.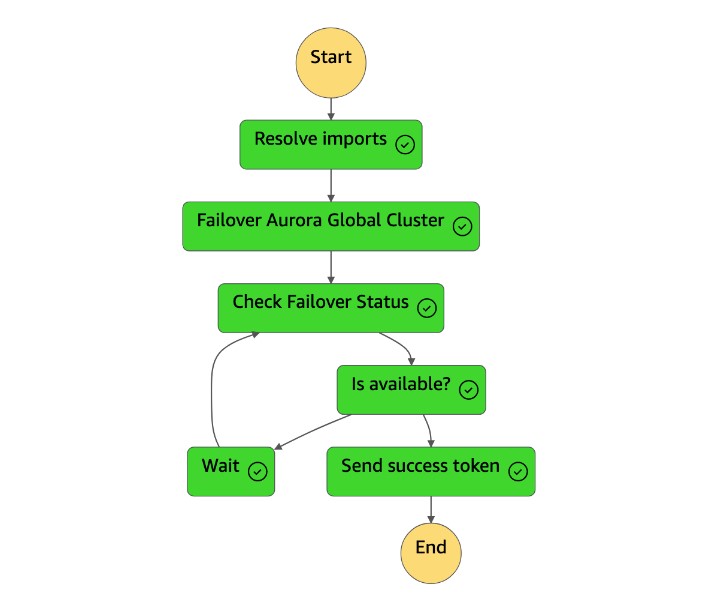
-
Mesin
dr-orchestrator-stepfunction-FAILOVERnegara selesai.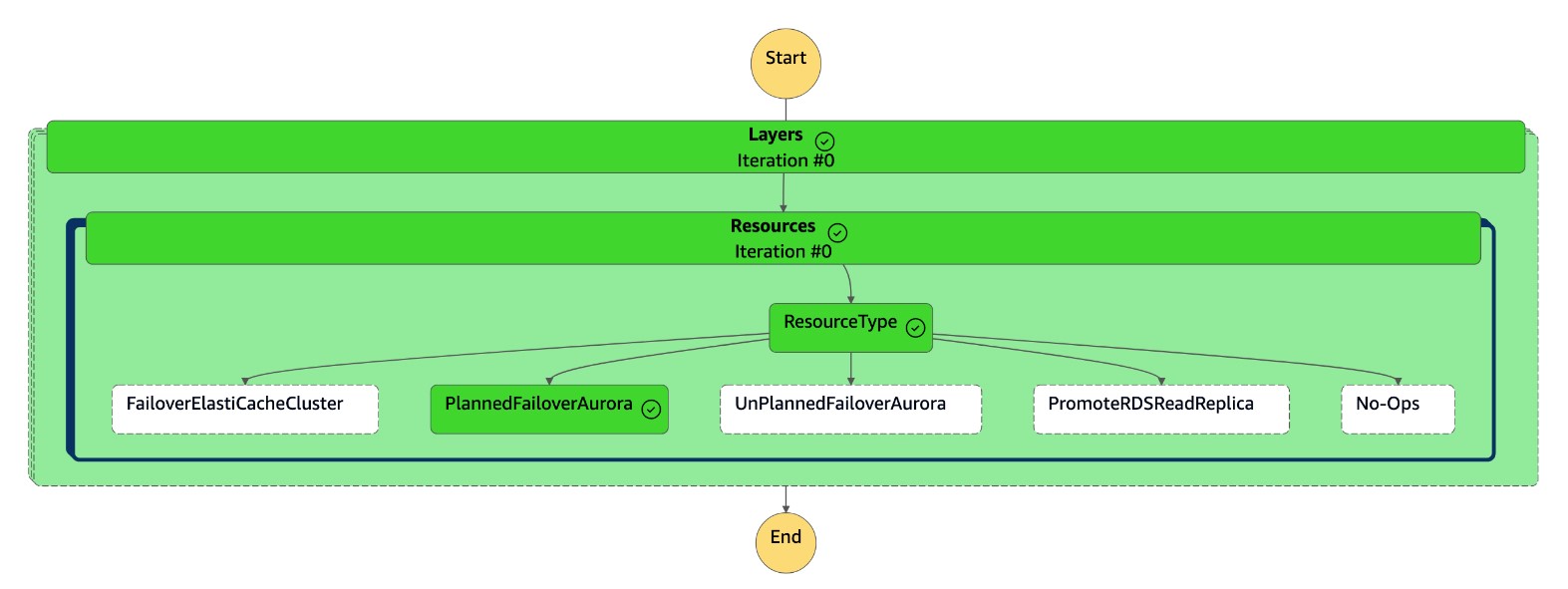
Di konsol, peran cluster Sekunder (dbcluster-02) sekarang adalah klaster Primer, dan cluster siap melayani beban kerja baca/tulis. Peran cluster primer asli (dbcluster-01) sekarang terdaftar sebagai cluster Sekunder.
Failover manual yang tidak direncanakan
Pada kesempatan langka, database global Aurora Anda mungkin mengalami pemadaman tak terduga pada awalnya. Wilayah AWS Jika hal ini terjadi, klaster DB Aurora primer dan simpul penulisnya tidak tersedia, dan replikasi antara klaster primer dan kedua berhenti. Untuk meminimalkan downtime (RTO) dan kehilangan data (RPO), bekerja dengan cepat untuk melakukan failover lintas wilayah dan merekonstruksi basis data global Aurora Anda. Untuk informasi selengkapnya, lihat Memulihkan database global Amazon Aurora dari pemadaman yang tidak direncanakan.
Melakukan failover yang tidak direncanakan mengharuskan Anda melepaskan cluster sekunder Anda dari database global Aurora. Sebelum Anda melakukan failover yang tidak direncanakan, hentikan penulisan aplikasi di cluster Aurora DB utama Anda. Setelah failover selesai dengan sukses, konfigurasi ulang aplikasi untuk menulis ke cluster DB primer yang baru. Pendekatan ini membantu mencegah kehilangan data. Ini juga membantu menghindari inkonsistensi data jika node penulis utama kembali online selama proses failover.
Untuk melakukan failover yang tidak direncanakan, hubungi mesin dr-orchestrator-stepfunction-FAILOVER negara. Untuk contoh ini, cluster Sekunder (db-cluster-02) berada di DR Region (us-west-2) dalam keadaan mapan.
Untuk melakukan failover, lakukan hal berikut:
-
Masuk ke konsol tersebut.
-
Ubah Wilayah ke Wilayah DR (
us-west-2). -
Arahkan ke Layanan, dan pilih Step Functions.
-
Arahkan ke mesin
dr-orchestrator-stepfunction-FAILOVERnegara. -
Pilih Mulai eksekusi, dan masukkan kode JSON berikut di
Input - optionalbagian, gunakanUnPlannedFailoverAurorasebagai:resourceType{ "StatePayload": [ { "layer": 1, "resources": [ { "resourceType": "UnPlannedFailoverAurora", "resourceName": "Performing unplanned failover for Amazon Aurora global databases (MySQL)", "parameters": { "GlobalClusterIdentifier": "!Import dr-globaldb-cluster-mysql-global-identifier", "DBClusterIdentifier": "!Import dr-globaldb-cluster-mysql-cluster-identifier", "ClusterRegion": "!Import dr-globaldb-cluster-mysql-cluster-region" } } ] } ] } -
Mesin
dr-orchestrator-stepfunction-FAILOVERstatus membaca tipe sumber daya sebagaiUnPlannedFailoverAuroraMySQLdan memanggil tugasDetach Cluster from Global Databasedari mesindr-orchestrator-stepfunction-unplanned-Aurora-failoverstatus.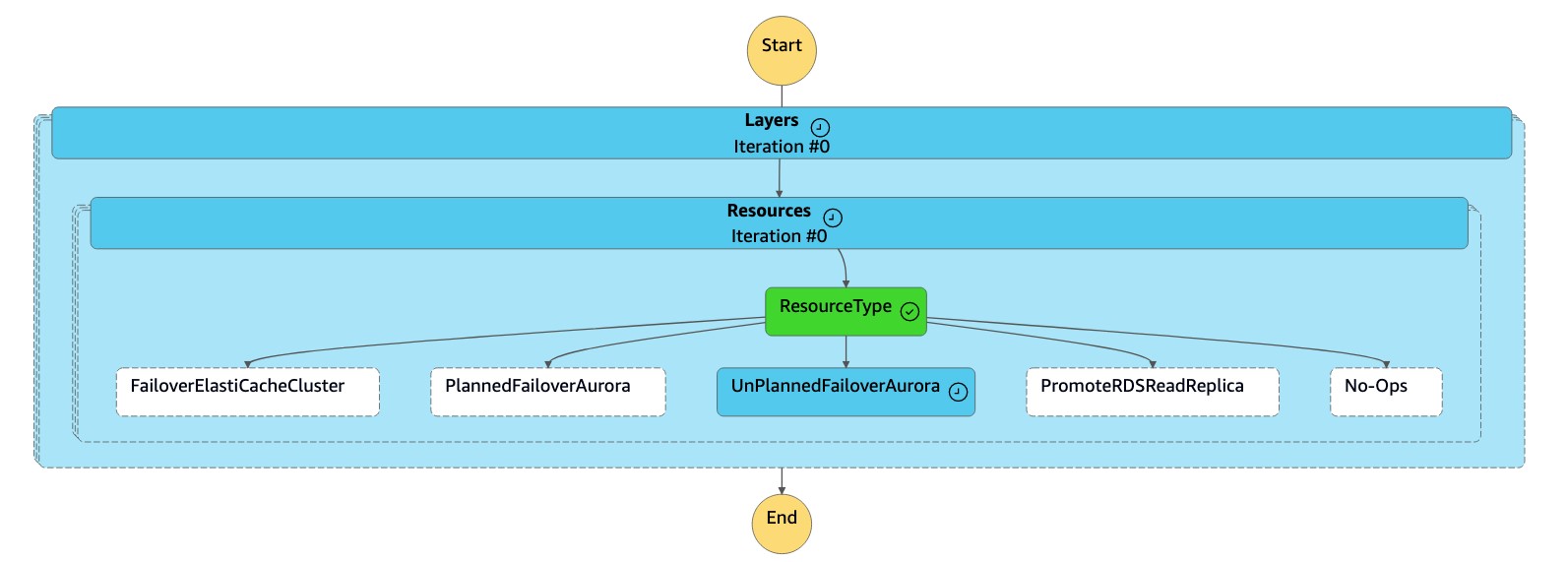
-
Detach Cluster from Global DatabaseTugas melepaskan (menghapus) cluster sekunder dari database global.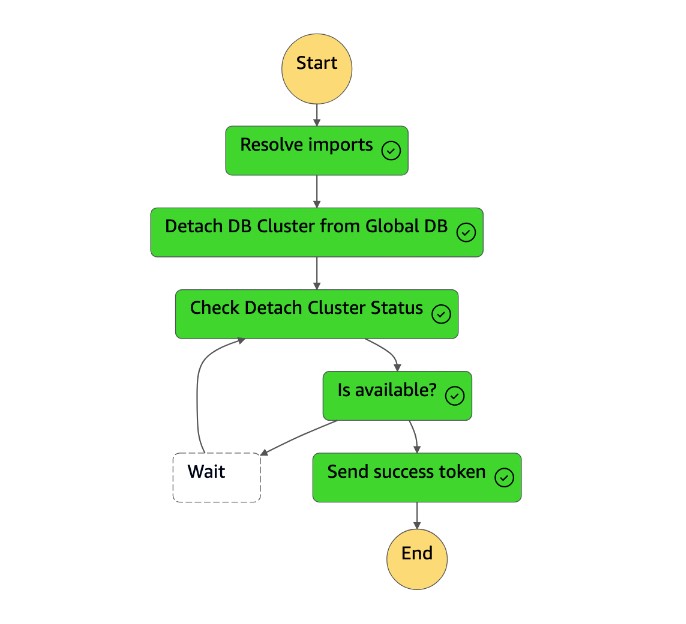
-
Cluster sekunder (
dbcluster-02) dipromosikan menjadi cluster mandiri, dan dapat melayani beban kerja baca/tulis. -
Mesin
dr-orchestrator-stepfunction-FAILOVERnegara selesai.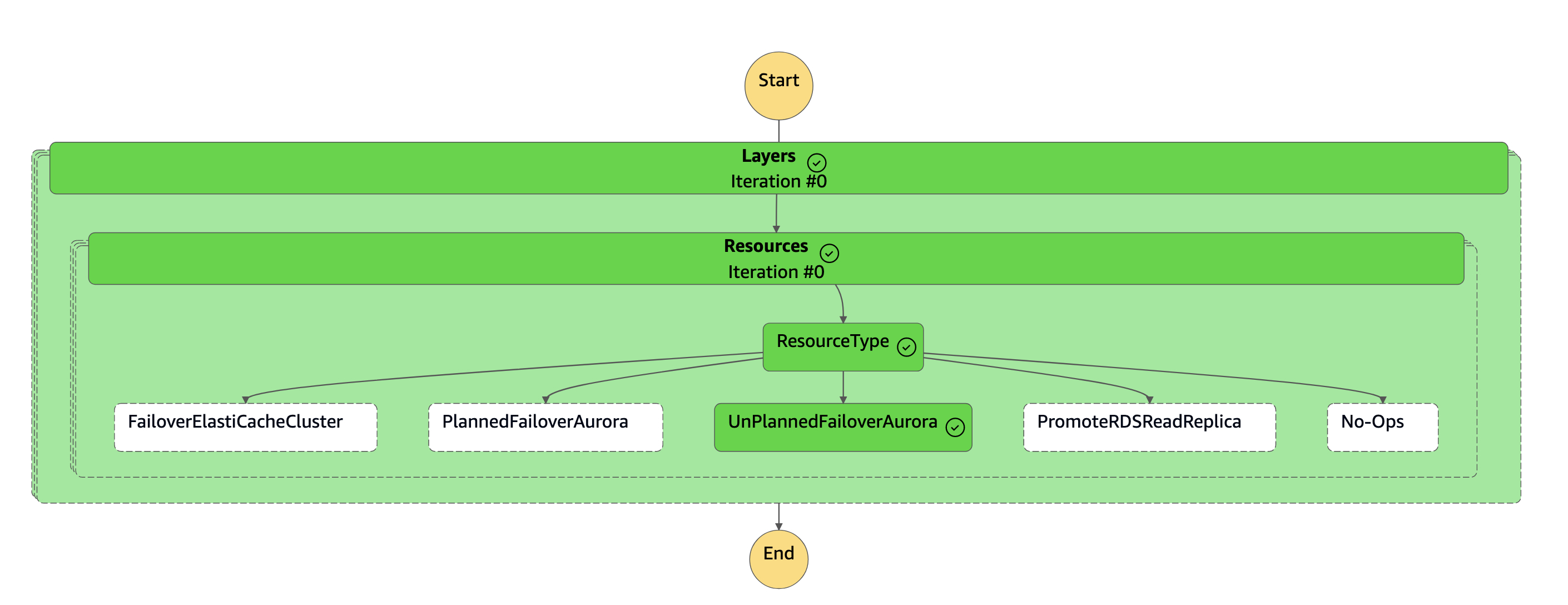
-
Cluster sekunder (
dbcluster-02) terlepas dari database global Aurora, dan menjadi cluster mandiri untuk melayani beban kerja baca/penulis. -
Konfigurasikan ulang aplikasi Anda untuk mengirim semua operasi penulisan ke cluster Aurora DB mandiri baru ini dengan menggunakan titik akhir cluster barunya.
Kegagalan
Failback mengembalikan database Anda ke lokasi utama asli (atau baru) setelah bencana (atau peristiwa terjadwal) diselesaikan. Ketika pemadaman yang tidak direncanakan telah diselesaikan, Anda mungkin ingin menambahkan Wilayah utama Anda sebelumnya kembali ke database global Aurora. Pertama-tama Anda harus menghapus klaster DB yang ada dari Region primer sebelumnya, membuat klaster DB baru dari Region primer yang baru, dan kemudian menggunakan proses failover terencana terkelola untuk mengalihkan peran klaster baru.
Ini dapat dianggap sebagai kegiatan terencana yang dapat Anda lakukan selama jam-jam sibuk atau pada akhir pekan.
Anda harus secara manual memodifikasi Amazon Aurora DB Cluster dan menonaktifkan DeletionProtection sebelum Anda menjalankan DR Orchestrator FAILBACK state machine dari Region (us-east-1) primer sebelumnya karena dibuat dengan. DeletionProtection
DR Orchestrator Framework menggunakan mesin dr-orchestrator-stepfunction-FAILBACK status untuk mengotomatiskan langkah-langkah untuk menghapus cluster yang ada dan membuat cluster baru di Region primer sebelumnya.
Untuk menonaktifkanDeletionProtection, lakukan hal berikut:
-
Masuk ke konsol tersebut.
-
Ubah Region ke Region primer sebelumnya (
us-east-1). -
Arahkan ke konsol Amazon RDS, pilih nama cluster (
dbcluster-01), dan pilih Ubah. -
Di bawah Perlindungan penghapusan, kosongkan kotak centang Aktifkan perlindungan penghapusan, dan pilih Lanjutkan.
-
Pilih Terapkan segera, lalu pilih Modify cluster.
Mesin DR Orchestrator FAILBACK status dipanggil selama proses failback dari Region () us-east-1 primer sebelumnya.
Untuk melakukan failback, lakukan hal berikut:
-
Masuk ke konsol tersebut.
-
Ubah Region ke Region primer sebelumnya (
us-east-1). -
Arahkan ke Layanan, lalu pilih Step Functions.
-
Arahkan ke mesin
DR Orchestrator FAILBACKnegara. -
Pilih Mulai eksekusi, dan masukkan kode JSON berikut di
Input - optionalbagian:{ "StatePayload": [ { "layer": 1, "resources": [ { "resourceType": "CreateAuroraSecondaryDBCluster", "resourceName": "To create secondary Aurora MySQL Global Database Cluster", "parameters": { "GlobalClusterIdentifier": "!Import dr-globaldb-cluster-mysql-global-identifier", "DBClusterIdentifier": "!Import dr-globaldb-cluster-mysql-cluster-identifier", "DBClusterName": "!Import dr-globaldb-cluster-mysql-cluster-name", "SourceDBClusterIdentifier": "!Import dr-globaldb-cluster-mysql-source-cluster-identifier", "DBInstanceIdentifier": "!Import dr-globaldb-cluster-mysql-instance-identifier", "Port": "!Import dr-globaldb-cluster-mysql-port", "DBInstanceClass": "!Import dr-globaldb-cluster-mysql-instance-class", "DBSubnetGroupName": "!Import dr-globaldb-cluster-mysql-subnet-group-name", "VpcSecurityGroupIds": "!Import dr-globaldb-cluster-mysql-vpc-security-group-ids", "Engine": "!Import dr-globaldb-cluster-mysql-engine", "EngineVersion": "!Import dr-globaldb-cluster-mysql-engine-version", "KmsKeyId": "!Import dr-globaldb-cluster-mysql-KmsKeyId", "SourceRegion": "!Import dr-globaldb-cluster-mysql-source-region", "ClusterRegion": "!Import dr-globaldb-cluster-mysql-cluster-region", "BackupRetentionPeriod": "7", "MonitoringInterval": "60", "StorageEncrypted": "True", "EnableIAMDatabaseAuthentication": "True", "DeletionProtection": "True", "CopyTagsToSnapshot": "True", "AutoMinorVersionUpgrade": "True", "MonitoringRoleArn": "!Import rds-mysql-instance-RDSMonitoringRole" } } ] } ] } -
Mesin
DR Orchestrator FAILBACKstatus membaca jenis sumber daya sebagaiCreateAuroraSecondaryDBCluster, dan itu memanggil mesindr-orchestrator-stepfunction-create-Aurora-Secondary-clusterstatus.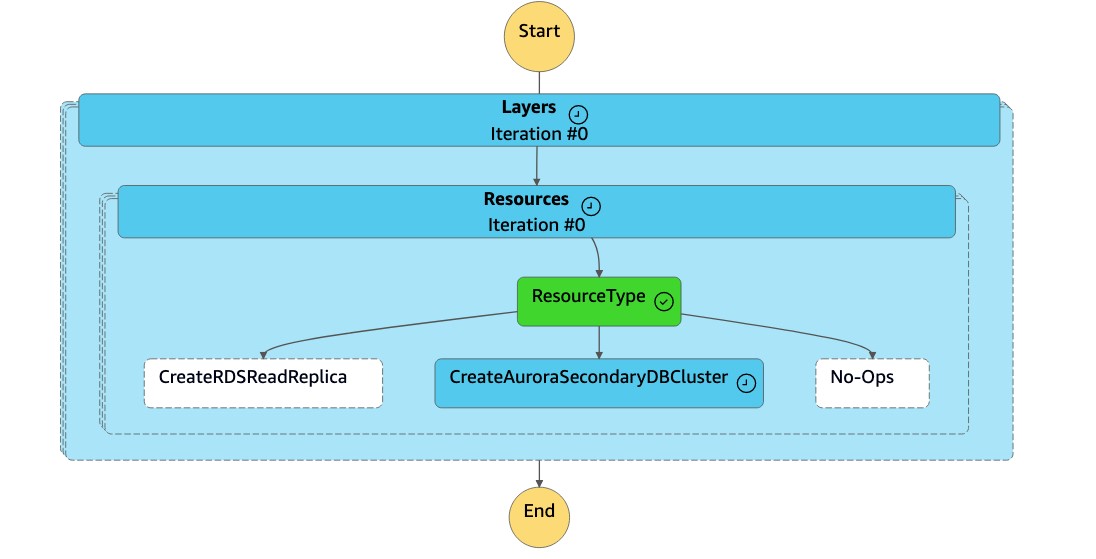
-
Mesin
dr-orchestrator-stepfunction-create-Aurora-Secondary-clusterstate menghapus cluster (dbcluster-01) yang ada dari Region (us-east-1) primer sebelumnya.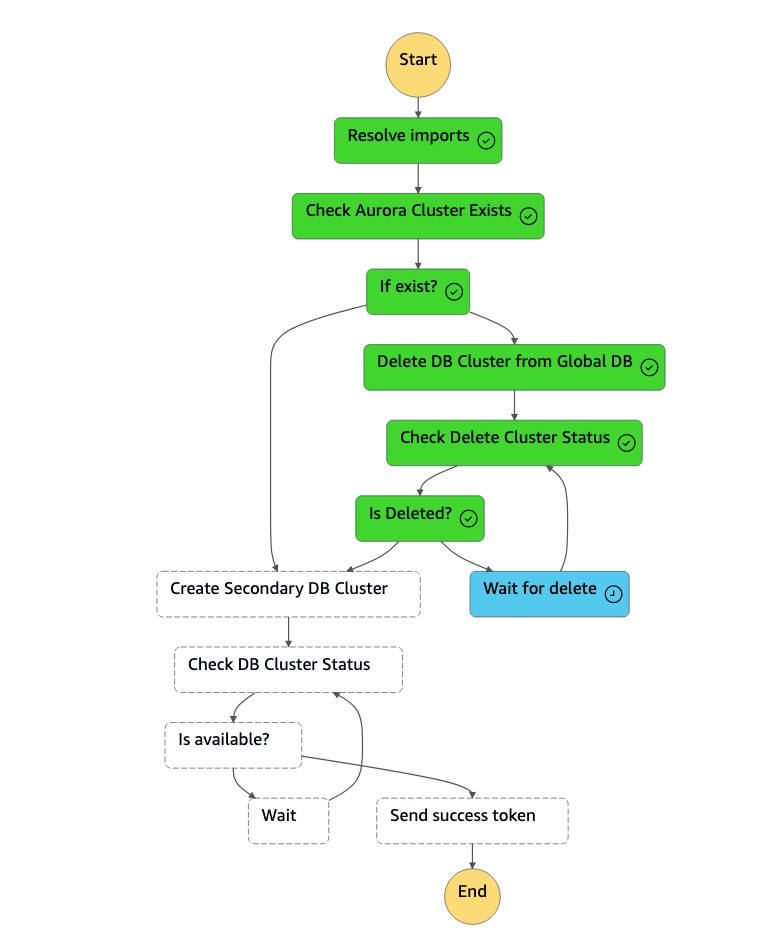
-
Setelah cluster (
dbcluster-01) dihapus, mesin state membuat cluster (dbcluster-01) baru bersama dengan instans DB, dan bergabung dengan database global Aurora sebagai cluster sekunder untuk melayani beban kerja hanya-baca.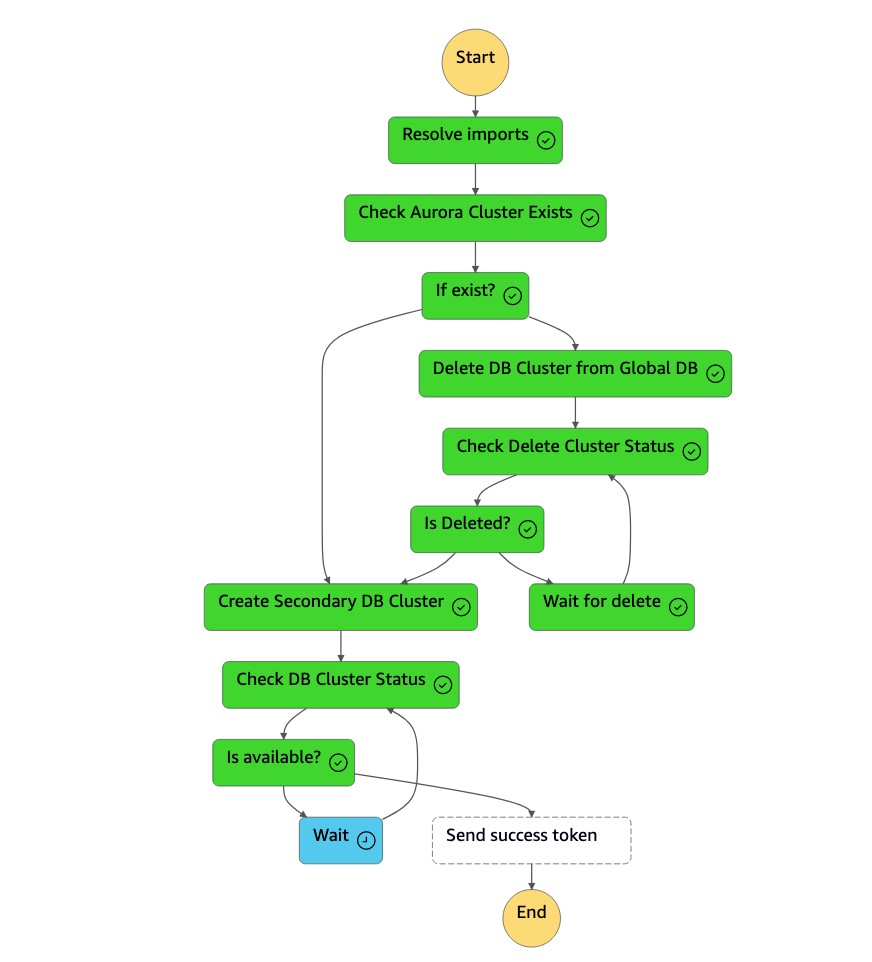
-
Setelah cluster sekunder tersedia, mesin
dr-orchestrator-stepfunction-create-Aurora-Secondary-clusterstatus selesai, dan mengirimkan token sukses kembali ke mesinDR Orchestrator Failbacknegara.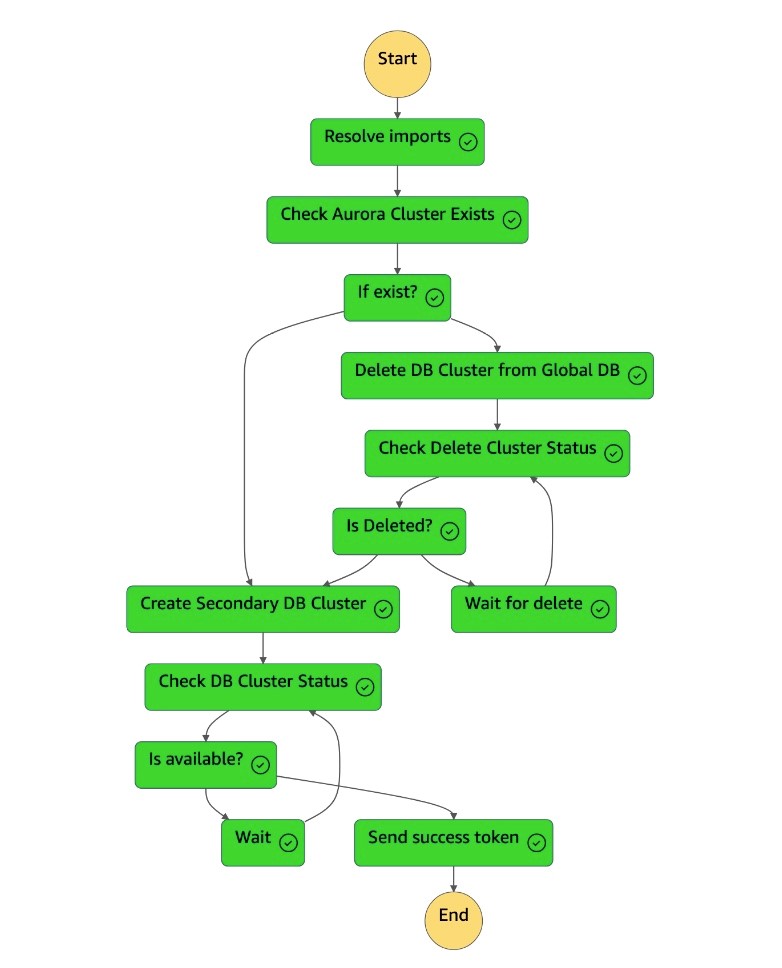
-
Mesin
dr-orchestrator-stepfunction-FAILBACKnegara selesai.
-
Anda dapat memverifikasi database global Aurora di konsol Amazon RDS.
