Terjemahan disediakan oleh mesin penerjemah. Jika konten terjemahan yang diberikan bertentangan dengan versi bahasa Inggris aslinya, utamakan versi bahasa Inggris.
Arsitektur referensi
Diagram berikut menunjukkan alur kerja setelah Anda menerapkan solusi otomatis panduan ini ke laporan operasi harian. Ketika file baru dicerna ke Amazon Simple Storage Service (Amazon S3) Simple Storage Service (Amazon S3), file tersebut dapat langsung divisualisasikan di dasbor setelah diproses. QuickSight
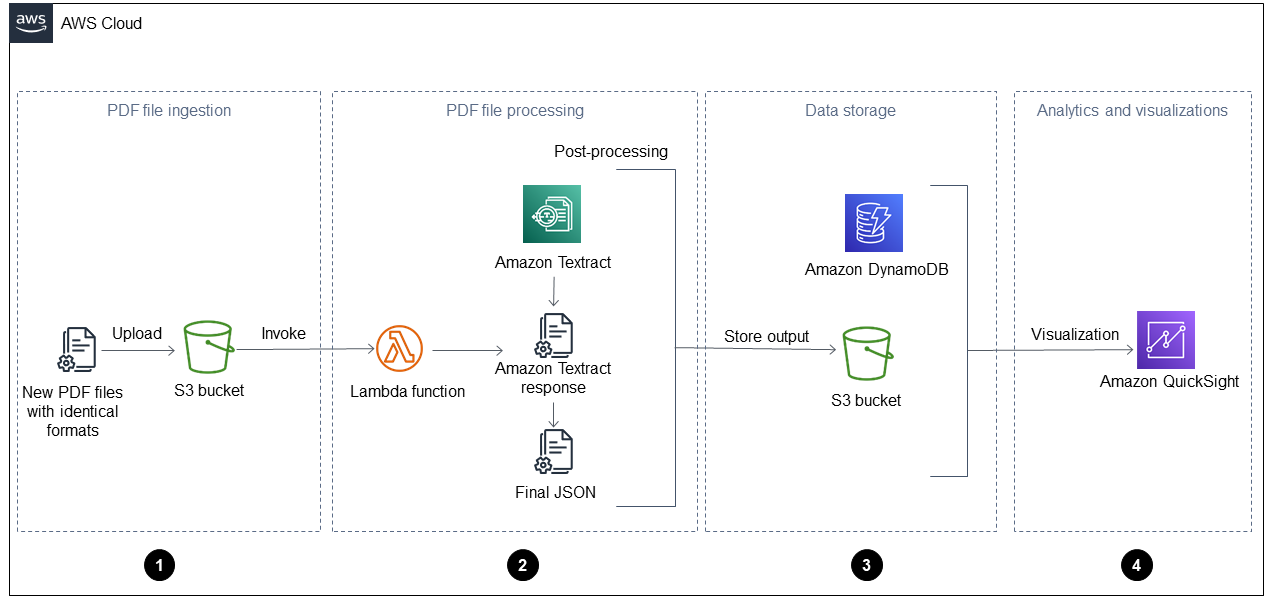
Diagram menunjukkan empat fase berikut:
-
Penyerapan file PDF — Aplikasi Anda secara otomatis menyerap file PDF baru dengan format yang identik (misalnya, laporan operasi harian) ke dalam bucket Amazon Simple Storage Service (Amazon S3). Amazon S3 memulai
ObjectCreatedacara saat file PDF baru ditambahkan ke bucket dan ini memanggil fungsi. AWS Lambda Untuk informasi selengkapnya tentang ini, lihat Menggunakan pemicu Amazon S3 untuk menjalankan fungsi Lambda di dokumentasi Amazon S3. -
Pemrosesan file PDF - Fungsi Lambda mengirimkan satu file PDF ke Amazon Ttract, yang mengekstrak konten. Skrip pasca-pemrosesan menjalankan dan mem-parsing respons Amazon Textract dan menggunakan template yang telah ditentukan untuk jenis file PDF ini. Template ini berisi atribut yang benar dan membantu mengekstrak semua pasangan nilai kunci, tabel, dan teks mentah lainnya dengan benar. Untuk informasi selengkapnya tentang ini, lihat pola Ekstrak konten secara otomatis dari file PDF menggunakan Amazon Ttract di situs web AWS Prescriptive Guidance.
-
Penyimpanan data — Data yang diekstraksi dan dikoreksi disimpan dalam tabel Amazon DynamoDB, selain file JSON untuk setiap file PDF. File JSON disimpan dalam bucket S3 yang dapat digunakan oleh layanan pemrosesan dan analitik hilir, seperti Amazon Athena,, atau Amazon AI. QuickSight SageMaker
-
Analisis dan visualisasi — QuickSight menganalisis data dan membuat visualisasi yang membantu menghasilkan wawasan untuk semua file PDF yang diproses. Setelah dasbor dibuat QuickSight, Anda dapat membagikannya dengan pengguna akhir dan tim bisnis Anda.
Pertimbangan
Solusi panduan ini sesuai untuk memproses file PDF yang memiliki format identik dan tata letak formulir dan tabel yang konsisten. Namun, Anda harus menentukan template dan mengeditnya terlebih dahulu untuk sepenuhnya mengotomatiskan proses dan membuat data yang diekstraksi tersedia untuk analisis. Template ini kemudian digunakan selama pemrosesan dengan fungsi Lambda.
Meskipun solusi ini dapat diterapkan ke berbagai jenis file PDF secara bersamaan, Anda harus membuat dan menentukan templat terpisah untuk setiap jenis file PDF dan menyimpannya di lokasi yang dapat diakses (misalnya, Amazon S3). Kami menyarankan Anda menggunakan pengenal unik untuk setiap jenis file PDF, seperti nama file PDF atau folder berbeda di bucket S3 Anda. Fungsi Lambda kemudian dapat memanggil template yang sesuai saat memproses jenis file PDF.
