Terjemahan disediakan oleh mesin penerjemah. Jika konten terjemahan yang diberikan bertentangan dengan versi bahasa Inggris aslinya, utamakan versi bahasa Inggris.
Ikhtisar vektor
Vektor adalah representasi numerik yang membantu mesin memahami dan memproses data. Dalam AI generatif, mereka melayani dua tujuan utama:
-
Mewakili ruang laten yang menangkap struktur data dalam bentuk terkompresi
-
Membuat embeddings untuk data seperti kata-kata, kalimat, dan gambar
Model penyematan seperti Word2Vec
-
Belajar dari konteks untuk merepresentasikan kata-kata sebagai vektor.
-
Tempatkan kata-kata serupa lebih dekat bersama-sama dalam ruang vektor.
-
Memungkinkan mesin untuk memproses data dalam ruang kontinu.
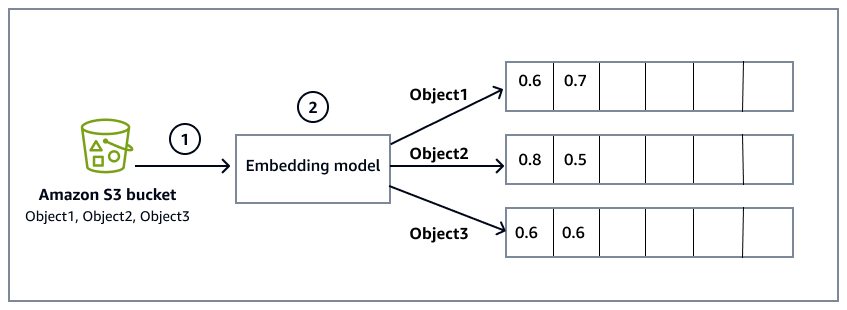
Diagram berikut memberikan gambaran tingkat tinggi dari proses penyematan:
-
Bucket Amazon Simple Storage Service (Amazon S3) berisi file yang merupakan sumber data dari mana sistem akan membaca dan memproses informasi. Bucket S3 ditentukan selama konfigurasi basis pengetahuan Amazon Bedrock, yang juga mencakup sinkronisasi data dengan basis pengetahuan.
-
Model embedding mengubah data mentah dari file objek di bucket S3 menjadi embeddings vektor. Misalnya, Object1 diubah menjadi vektor [0.6, 0.7,...], mewakili isinya dalam ruang multi-dimensi.
Penyematan kata sangat penting untuk pemrosesan bahasa alami (NLP) karena mereka melakukan hal berikut:
-
Tangkap hubungan semantik antar kata.
-
Aktifkan pembuatan teks yang relevan secara kontekstual.
-
Kekuatan model bahasa besar (LLMs) untuk menghasilkan respons seperti manusia.
