Terjemahan disediakan oleh mesin penerjemah. Jika konten terjemahan yang diberikan bertentangan dengan versi bahasa Inggris aslinya, utamakan versi bahasa Inggris.
Katalog terpusat
Diagram berikut menunjukkan bagaimana katalog terpusat menghubungkan produsen data dan konsumen data di danau data.
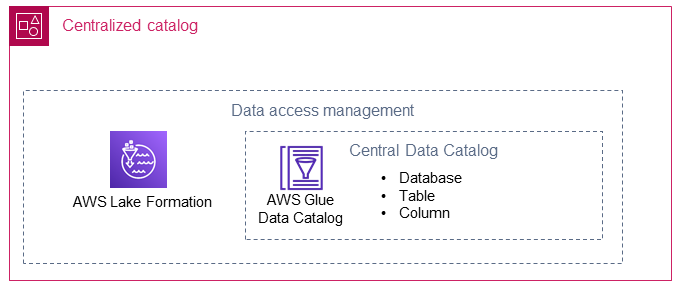
Katalog terpusat menyimpan dan mengelola katalog data bersama untuk akun produsen data. Katalog terpusat juga menampung metadata teknis data bersama (misalnya, nama tabel dan skema) dan merupakan lokasi di mana konsumen data datang untuk mengakses data.
Konsumen data dapat mengakses data dari beberapa produsen data dalam katalog terpusat dan kemudian dapat mencampur data ini dengan data mereka sendiri untuk diproses lebih lanjut. Menggunakan katalog terpusat menghilangkan kebutuhan konsumen data untuk terhubung langsung dengan produsen data yang berbeda dan mengurangi biaya operasional.
Karena katalog terpusat memiliki visibilitas ke dalam berbagi data dan konsumsi data oleh produsen data dan konsumen, ini bisa menjadi lokasi yang ideal untuk menerapkan fungsi tata kelola data terpusat Anda (misalnya, audit akses).
Bagian berikut menjelaskan bagaimana katalog terpusat menggunakan AWS Lake Formation dan AWS Glue.
AWS Lake Formation
AWS Lake Formationmembantu membuat database dalam Katalog AWS Glue Data yang mengarah ke lokasi beberapa produsen data di danau data Anda. Peran AWS Identity and Access Management (IAM) dibuat untuk Lake Formation di katalog terpusat. Dengan menggunakan Lake Formation, katalog terpusat dapat secara selektif berbagi sumber daya data (misalnya, database, tabel, atau kolom) dengan konsumen data. Sumber daya yang dikelola Lake Formation dibagi dengan konsumen data dengan menggunakan salah satu dari dua metode berikut:
-
Metode sumber daya bernama — Metode ini berbagi sumber daya terkelola di seluruh akun. Database, tabel, atau nama kolom harus ditentukan dan sumber daya dapat dibagikan ke organisasi, unit organisasi (OU), atau Akun AWS. Untuk mengurangi overhead berbagi dan manajemen, kami sarankan Anda berbagi sumber daya di tingkat yang lebih tinggi jika memungkinkan (misalnya, dalam organisasi atau OU, bukan Akun AWS). Namun, Anda harus memastikan bahwa pendekatan ini memenuhi persyaratan kontrol keamanan data organisasi Anda.
-
Catatan: Metode ini bekerja dengan baik untuk konsumen data dengan tipe aplikasi, di mana AWS layanan mengkonsumsi data dari produsen data. Persyaratan akses data dari jenis konsumen data ini didorong oleh aplikasi, preskriptif, dan relatif statis.
-
-
Metode kontrol akses berbasis tag Lake Formation (LF-TBAC) — LF-TBAC sangat berguna bagi konsumen data dengan tipe penyajian data. Namun, sumber daya yang ditandai Lake Formation saat ini hanya dapat dibagikan di Akun AWS level tersebut dan bukan di tingkat organisasi atau OU.
AWS Glue
Anda harus membuat database AWS Glue untuk setiap produsen data di katalog terpusat Anda. Karena katalog terpusat digunakan AWS Glue untuk meng-host database dari semua produsen data, Anda harus memastikan bahwa nama database unik di semua produsen data dan mencerminkan produsen data dan jenis datanya. Misalnya, Anda dapat menggunakan struktur penamaan database berikut: <Data_Producer>–<Environment>–<Data_Group>
-
<Data_Producer>Nama produsen data -
<Environment>Lingkungan data lake, sepertidevuntuk lingkungan pengembangan,situntuk lingkungan pengujian integrasi sistem, atauproduntuk lingkungan produksi. -
<Data_Group>Nama grup data yang digunakan untuk memisahkan data dari produsen data ke dalam kelompok logis. Anda dapat menggunakan nama sistem sumber, ID, atau singkatan sebagai nama. Deskripsi database juga membantu mendeskripsikan konten dan tujuan database.
Anda dapat menggunakan AWS Glue crawler pada data produsen data untuk mempertahankan skema dalam database katalog terpusat. Jika data secara teratur dibuat pada frekuensi yang sama oleh produsen data, Anda dapat menggunakan AWS Glue crawler tunggal. Dalam semua kasus lain, Anda harus menggunakan beberapa AWS Glue crawler untuk mengakomodasi frekuensi crawling yang berbeda. Bergantung pada kasus penggunaan bisnis Anda, crawler dapat dijadwalkan untuk frekuensi yang telah ditentukan sebelumnya atau diprakarsai oleh peristiwa.
Anda juga dapat mempertahankan skema tabel AWS Glue dengan memanggil AWS Glue API untuk membuat atau memperbarui skema. Meskipun ini dapat memberikan fleksibilitas, upaya tambahan diperlukan untuk pengembangan dan pemeliharaan kode. Pastikan Anda mengevaluasi kasus penggunaan dan nilai bisnis dan kemudian pilih opsi yang memenuhi persyaratan Anda dan memiliki overhead paling sedikit.
