Terjemahan disediakan oleh mesin penerjemah. Jika konten terjemahan yang diberikan bertentangan dengan versi bahasa Inggris aslinya, utamakan versi bahasa Inggris.
Tantangan penskalaan umum
Danau data melewati beberapa tahap ketika datanya tumbuh setelah penyebaran awal. Jika Anda tidak menggunakan arsitektur yang dapat diskalakan untuk mendesain data lake Anda, organisasi Anda mungkin menghadapi tantangan dan dapat dirugikan oleh pertumbuhan data lake.
Bagian berikut menjelaskan bagaimana pertumbuhan data lake yang khas dapat menyebabkan tantangan penskalaan.
Penyebaran data danau awal
Diagram berikut menunjukkan arsitektur data lake setelah penyebaran awalnya oleh Line of business A.
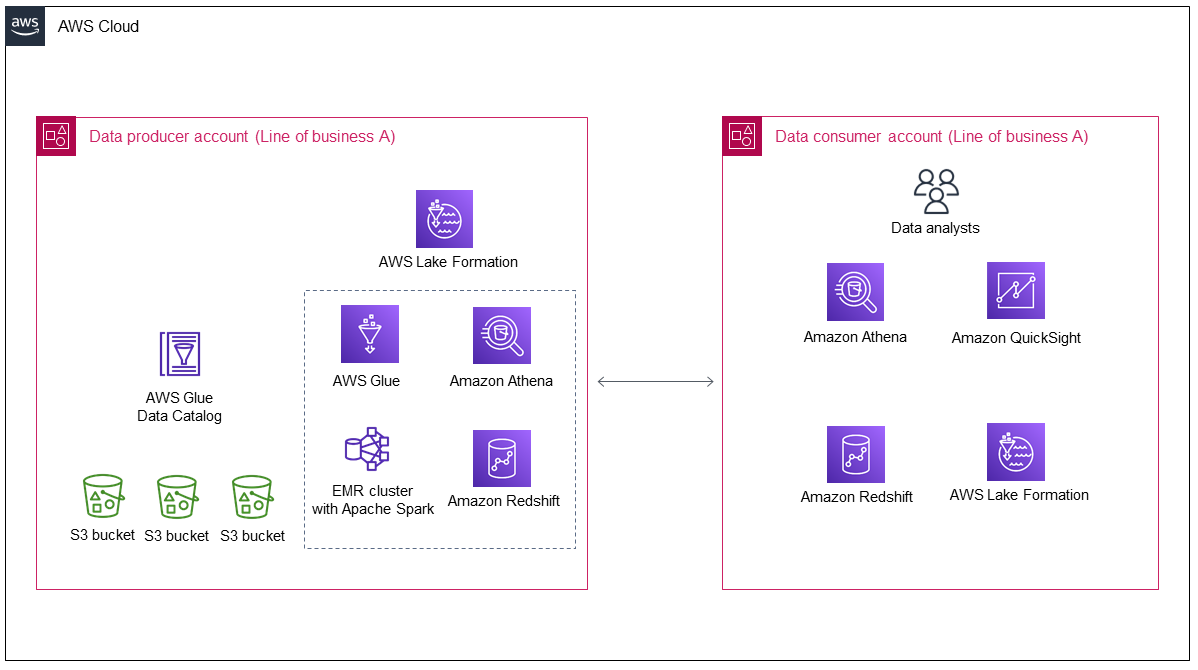
Diagram menunjukkan komponen-komponen berikut:
-
Akun produsen data mengumpulkan dan memproses data, menyimpan data yang diproses, dan menyiapkannya untuk dikonsumsi.
-
Data di akun produsen data disimpan di bucket Amazon Simple Storage Service (Amazon S3), yang dapat memiliki beberapa lapisan data.
-
Anda dapat menggunakan AWS layanan untuk pemrosesan data (misalnya, AWS Gluedan Amazon EMR).
-
Produsen data tidak hanya memproduksi dan menyimpan data di danau data tetapi kemudian juga perlu memutuskan data apa yang akan dibagikan dengan konsumen data dan bagaimana membagikannya. AWS Lake Formation mengelola data lake di akun produsen data, selain mengelola berbagi data lintas akun dari produsen data ke konsumen data.
-
Akun konsumen data menggunakan data bersama dari akun produsen data untuk kasus penggunaan bisnis tertentu.
Konsumen data meningkat
Diagram berikut menunjukkan bahwa lebih banyak data dibawa ke danau data ketika data Line of business A tumbuh. Danau data kemudian menarik lebih banyak konsumen data untuk memanfaatkan dan mendapatkan nilai dari data.
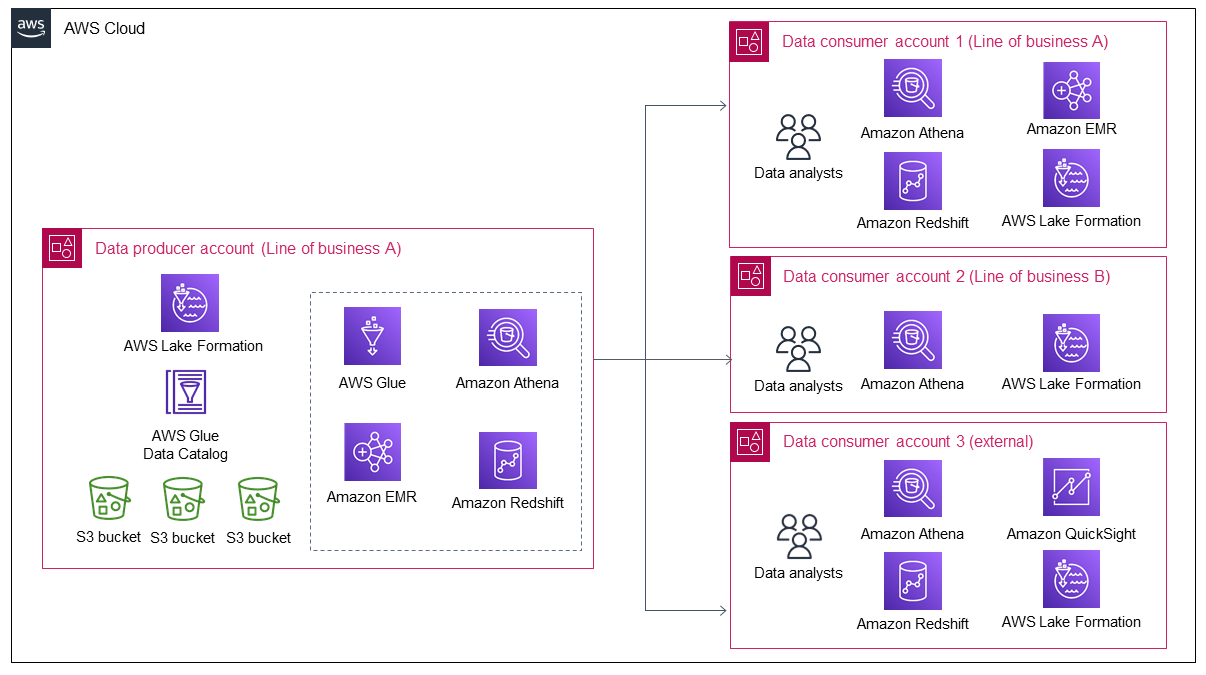
Diagram menunjukkan bagaimana organisasi menghasilkan nilai yang hampir berkelanjutan dari aset data yang ada dan ini menarik lebih banyak konsumen data. Namun, ketika konsumen data meningkat, produsen data hanya memiliki dua opsi berikut untuk mengakomodasi pertumbuhan ini:
-
Kelola berbagi dan akses data secara manual oleh konsumen data individu, yang bukan merupakan pendekatan yang dapat diskalakan.
-
Mengembangkan proses otomatis atau semi-otomatis untuk berbagi data dan mengelola akses data. Meskipun ini bisa menjadi opsi yang dapat diskalakan, ini membutuhkan waktu dan upaya yang signifikan untuk merancang dan membangun karena konsumen data internal dan eksternal memiliki persyaratan kontrol keamanan yang berbeda. Di masa depan, waktu dan upaya tambahan juga akan diperlukan untuk perbaikan solusi apa pun.
Produsen data meningkat
Diagram berikut menunjukkan arsitektur data lake ketika beberapa lini bisnis bergabung sebagai produsen data.
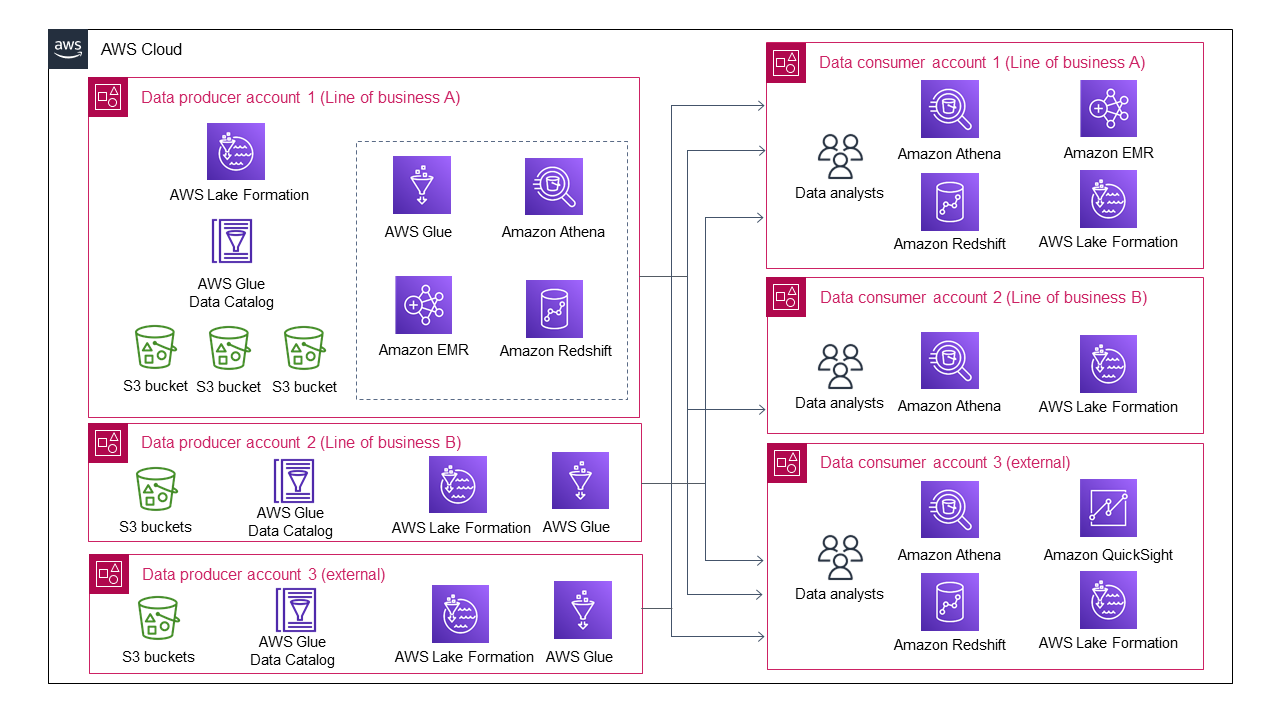
Arsitektur data lake menjadi semakin rumit, bahkan dengan hanya tiga produsen data dan tiga konsumen data.
Setiap produsen data perlu menangani berbagi data dan manajemen akses data untuk beberapa konsumen data. Tidak realistis untuk mengharapkan semua produsen data mengembangkan proses otomatis atau semi-otomatis untuk berbagi data dan manajemen akses data. Beberapa produsen data mungkin memilih untuk tidak membagikan data mereka dan karenanya menghindari overhead manajemen yang tidak terjangkau. Demikian pula, setiap konsumen data perlu berinteraksi dengan beberapa produsen data untuk memahami proses konsumsi data mereka yang berbeda. Ini berarti bahwa konsumen data individu menghadapi peningkatan overhead manajemen untuk menangani pola berbagi data yang berbeda.
Di banyak organisasi, danau data ini menyebabkan kemacetan dan tidak dapat tumbuh atau berkembang. Ini mungkin berarti bahwa organisasi Anda harus mendesain ulang dan membangun kembali data lake untuk menghilangkan hambatan, yang dapat menghabiskan banyak waktu, sumber daya, dan uang.
