Terjemahan disediakan oleh mesin penerjemah. Jika konten terjemahan yang diberikan bertentangan dengan versi bahasa Inggris aslinya, utamakan versi bahasa Inggris.
Model pembelajaran mesin untuk memperkirakan permintaan pengiriman
Gambar berikut menunjukkan contoh data pelatihan. Targetnya adalah apa yang ingin Anda prediksi, dan deret waktu terkait 1 dan 2 adalah fitur input yang relevan untuk memprediksi target. Data historis digunakan untuk pelatihan dan validasi, dan Anda menahan periode data historis untuk validasi model.
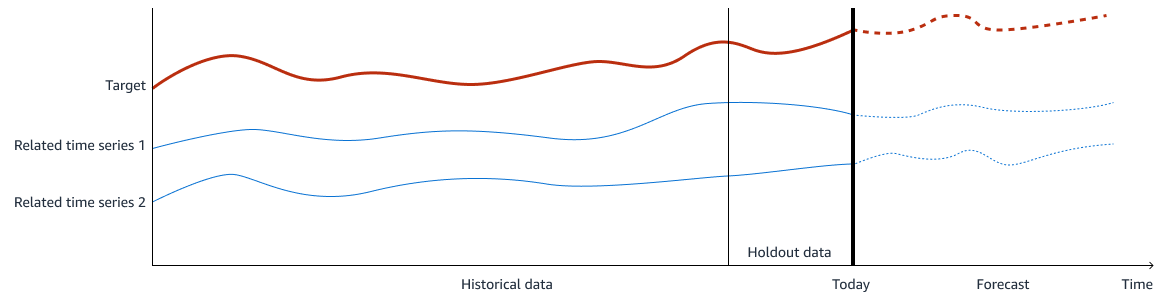
Dalam peramalan permintaan, output (atau target) adalah volume permintaan yang ingin Anda prediksi. Fitur input adalah data deret waktu yang terkait dengan output. Untuk melatih model ML untuk membuat perkiraan volume permintaan yang akurat, dua model pembelajaran mesin diperlukan dalam solusinya. Model pertama membuat perkiraan deret waktu untuk fitur input, termasuk data internal dan eksternal. Model kedua membuat perkiraan permintaan akhir dengan menggunakan semua fitur. Dengan menggunakan kedua model ini bersama-sama, Anda dapat secara efektif menangkap tren deret waktu dan hubungan antara target dan input.
Model ML untuk perkiraan fitur masukan
Fitur input mencakup data deret waktu historis internal dan eksternal. Untuk membuat prakiraan untuk setiap fitur, Anda dapat menggunakan model deret waktu satu dimensi (1D). Ada berbagai algoritma yang tersedia. Misalnya, Prophet
Model ML untuk perkiraan variabel target
Model ML untuk output, atau volume permintaan, dibangun untuk menangkap hubungan antara semua fitur dan output. Anda dapat menggunakan berbagai model regresi yang diawasi, seperti,, lassoridge regression, random forest dan. XGBoost Saat membangun model dan menemukan parameter dan hiperparameter terbaik, Anda dapat menggunakan data penahanan. Data Holdout adalah bagian dari data historis berlabel yang ditahan dari dataset yang digunakan untuk melatih model pembelajaran mesin. Anda dapat menggunakan data penahanan untuk mengevaluasi kinerja model dengan membandingkan prediksi terhadap data penahanan.
