Terjemahan disediakan oleh mesin penerjemah. Jika konten terjemahan yang diberikan bertentangan dengan versi bahasa Inggris aslinya, utamakan versi bahasa Inggris.
Studi kasus
Bagian ini membahas skenario bisnis dunia nyata dan aplikasi untuk mengukur ketidakpastian dalam sistem pembelajaran mendalam. Misalkan Anda ingin model pembelajaran mesin secara otomatis menilai apakah suatu kalimat secara tata bahasa tidak dapat diterima (kasus negatif) atau dapat diterima (kasus positif). Pertimbangkan proses bisnis berikut: Jika model menandai kalimat sebagai dapat diterima secara tata bahasa (positif), Anda memprosesnya secara otomatis, tanpa tinjauan manusia. Jika model menandai kalimat sebagai tidak dapat diterima (negatif), Anda meneruskan kalimat kepada manusia untuk ditinjau dan dikoreksi. Studi kasus menggunakan ansambel dalam bersama dengan penskalaan suhu.
Skenario ini memiliki dua tujuan bisnis:
-
Ingat tinggi untuk kasus negatif. Kami ingin menangkap semua kalimat yang memiliki kesalahan tata bahasa.
-
Pengurangan beban kerja manual. Kami ingin memproses kasus secara otomatis yang tidak memiliki kesalahan tata bahasa sebanyak mungkin.
Hasil dasar
Saat menerapkan satu model ke data tanpa putus sekolah pada waktu pengujian, ini adalah hasilnya:
-
Untuk sampel positif: recall = 94%, presisi = 82%
-
Untuk sampel negatif: recall = 52%, presisi = 79%
Model ini memiliki kinerja yang jauh lebih rendah untuk sampel negatif. Namun, untuk aplikasi bisnis, penarikan kembali untuk sampel negatif harus menjadi metrik yang paling penting.
Penerapan ansambel dalam
Untuk mengukur ketidakpastian model, kami menggunakan standar deviasi prediksi model individu di seluruh ansambel yang dalam. Hipotesis kami adalah bahwa untuk positif palsu (FP) dan negatif palsu (FN) kami berharap melihat ketidakpastian jauh lebih tinggi daripada positif sejati (TP) dan negatif sejati (TN). Secara khusus, model harus memiliki kepercayaan diri yang tinggi ketika benar dan kepercayaan diri rendah ketika salah, sehingga kita dapat menggunakan ketidakpastian untuk mengetahui kapan harus mempercayai output model.
Matriks kebingungan berikut menunjukkan distribusi ketidakpastian di seluruh data FN, FP, TN, dan TP. Probabilitas standar deviasi negatif adalah standar deviasi probabilitas negatif di seluruh model. Median, mean, dan standar deviasi dikumpulkan di seluruh dataset.
| Probabilitas standar deviasi negatif | |||
|---|---|---|---|
| Label | Median | Berarti | Standar deviasi |
FN |
0,061 |
0,060 |
0,027 |
FP |
0,063 |
0,062 |
0,040 |
TN |
0,039 |
0,045 |
0,026 |
TP |
0,009 |
0,020 |
0,025 |
Seperti yang ditunjukkan matriks, model melakukan yang terbaik untuk TP, sehingga memiliki ketidakpastian terendah. Model berkinerja terburuk untuk FP, sehingga memiliki ketidakpastian tertinggi, yang sejalan dengan hipotesis kami.
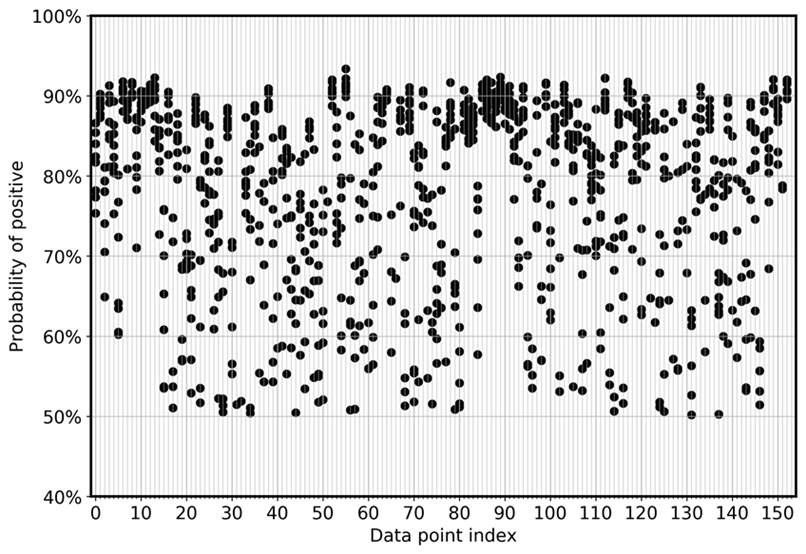
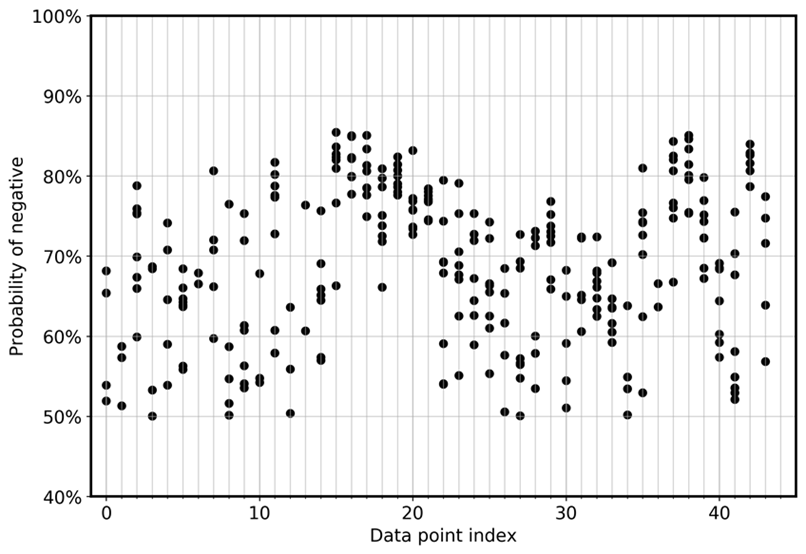
Untuk secara langsung memvisualisasikan penyimpangan model di antara ansambel, grafik berikut memplot probabilitas dalam tampilan sebar untuk FN dan FP untuk data CoLA. Setiap garis vertikal adalah untuk satu sampel input tertentu. Grafik menunjukkan delapan tampilan model ansambel. Artinya, setiap garis vertikal memiliki delapan titik data. Titik-titik ini tumpang tindih sempurna atau didistribusikan dalam kisaran tertentu.
Grafik pertama menunjukkan bahwa untuk FPs, probabilitas menjadi positif mendistribusikan antara 0,5 dan 0,925 di semua delapan model dalam ansambel.
Demikian pula, grafik berikutnya menunjukkan bahwa untuk FNs, probabilitas menjadi negatif mendistribusikan antara 0,5 dan 0,85 di antara delapan model dalam ansambel.
Mendefinisikan aturan keputusan
Untuk memaksimalkan manfaat hasil, kami menggunakan aturan ansambel berikut: Untuk setiap input, kami mengambil model yang memiliki probabilitas terendah untuk menjadi positif (dapat diterima) untuk membuat keputusan yang menandai. Jika probabilitas yang dipilih lebih besar dari, atau sama dengan, nilai ambang batas, kami menandai kasus sebagai dapat diterima dan memprosesnya secara otomatis. Jika tidak, kami mengirimkan kasus untuk tinjauan manusia. Ini adalah aturan keputusan konservatif yang sesuai di lingkungan yang sangat diatur.
Mengevaluasi hasil
Grafik berikut menunjukkan tingkat presisi, penarikan, dan otomatis (otomatisasi) untuk kasus negatif (kasus dengan kesalahan tata bahasa). Tingkat otomatisasi mengacu pada persentase kasus yang akan diproses secara otomatis karena model menandai kalimat sebagai dapat diterima. Model sempurna dengan penarikan dan presisi 100% akan mencapai tingkat otomatisasi 69% (kasus positif/total kasus), karena hanya kasus positif yang akan diproses secara otomatis.
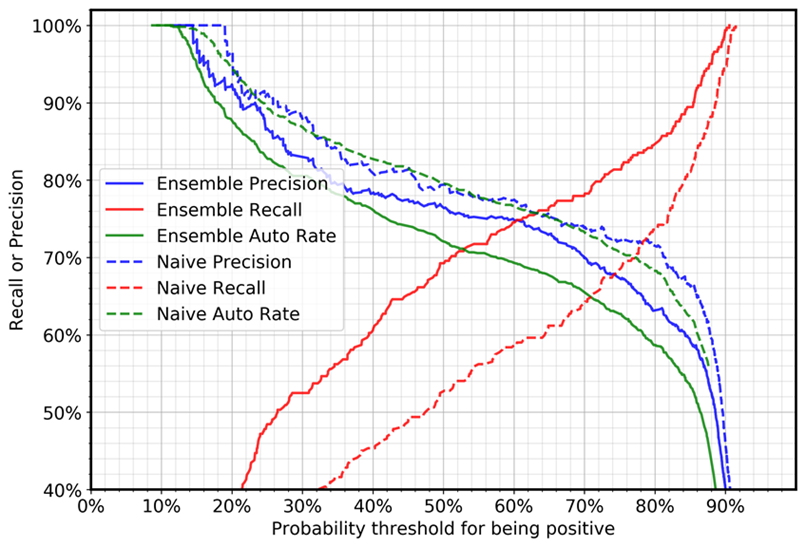
Perbandingan antara ansambel dalam dan kasus naif menunjukkan bahwa, untuk pengaturan ambang batas yang sama, ingatan meningkat cukup drastis dan presisi sedikit menurun. (Tingkat otomatisasi tergantung pada rasio sampel positif dan negatif dalam kumpulan data pengujian.) Sebagai contoh:
-
Menggunakan nilai ambang 0,5:
-
Dengan model tunggal, penarikan untuk kasus negatif akan menjadi 52%.
-
Dengan pendekatan ensemble mendalam, nilai recall akan menjadi 69%.
-
-
Menggunakan nilai ambang 0,88:
-
Dengan model tunggal, penarikan untuk kasus negatif akan menjadi 87%.
-
Dengan pendekatan ensemble mendalam, nilai recall akan menjadi 94%.
-
Anda dapat melihat bahwa ansambel yang dalam dapat meningkatkan metrik tertentu (dalam kasus kami, penarikan kembali kasus negatif) untuk aplikasi bisnis, tanpa persyaratan untuk meningkatkan ukuran data pelatihan, kualitasnya, atau perubahan metode model.
