Terjemahan disediakan oleh mesin penerjemah. Jika konten terjemahan yang diberikan bertentangan dengan versi bahasa Inggris aslinya, utamakan versi bahasa Inggris.
Cakupan dan akurasi dokumen — dalam domain
Kami membandingkan kinerja prediktif ansambel dalam dengan putus sekolah yang diterapkan pada waktu pengujian, putus sekolah MC, dan fungsi softmax naif, seperti yang ditunjukkan pada grafik berikut. Setelah inferensi, prediksi dengan ketidakpastian tertinggi dijatuhkan pada tingkat yang berbeda, menghasilkan cakupan data yang tersisa yang berkisar antara 10% hingga 100%. Kami mengharapkan ansambel yang dalam untuk lebih efisien mengidentifikasi prediksi yang tidak pasti karena kemampuannya yang lebih besar untuk mengukur ketidakpastian epistemik; yaitu, untuk mengidentifikasi wilayah dalam data di mana model memiliki pengalaman yang lebih sedikit. Ini harus tercermin dalam akurasi yang lebih tinggi untuk tingkat cakupan data yang berbeda. Untuk setiap ansambel dalam, kami menggunakan 5 model dan menerapkan inferensi 20 kali. Untuk putus sekolah MC, kami menerapkan inferensi 100 kali untuk setiap model. Kami menggunakan set hyperparameters dan arsitektur model yang sama untuk setiap metode.
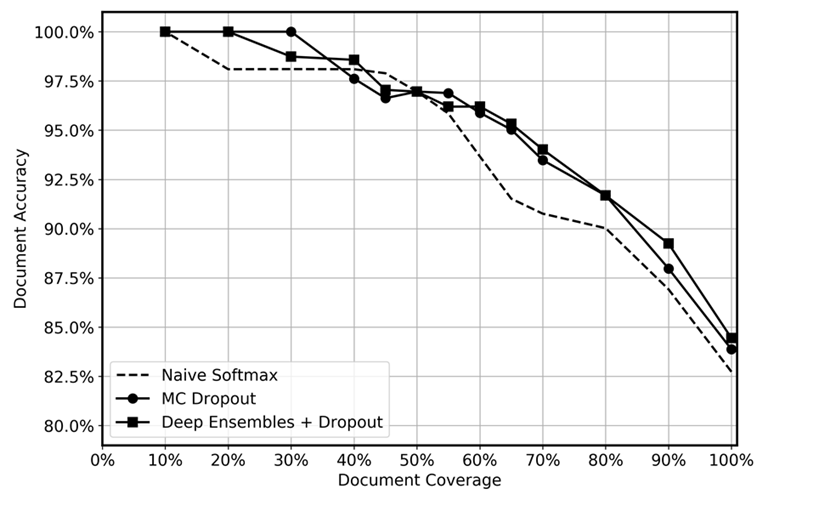
Grafik tampaknya menunjukkan sedikit manfaat menggunakan ansambel dalam dan putus sekolah MC dibandingkan dengan softmax naif. Ini paling menonjol dalam rentang cakupan data 50-80%. Mengapa ini tidak lebih besar? Seperti disebutkan di bagian ansambel yang dalam, kekuatan ansambel dalam berasal dari lintasan kerugian yang berbeda yang diambil. Dalam situasi ini, kami menggunakan model yang telah dilatih sebelumnya. Meskipun kami menyempurnakan seluruh model, sebagian besar bobot diinisialisasi dari model yang telah dilatih sebelumnya, dan hanya beberapa lapisan tersembunyi yang diinisialisasi secara acak. Akibatnya, kami menduga bahwa pra-pelatihan model besar dapat menyebabkan terlalu percaya diri karena sedikit diversifikasi. Sepengetahuan kami, kemanjuran ansambel dalam belum pernah diuji sebelumnya dalam skenario pembelajaran transfer, dan kami melihat ini sebagai area yang menarik untuk penelitian masa depan.
