Terjemahan disediakan oleh mesin penerjemah. Jika konten terjemahan yang diberikan bertentangan dengan versi bahasa Inggris aslinya, utamakan versi bahasa Inggris.
Persiapan dan pembersihan data
Persiapan dan pembersihan data adalah salah satu tahapan siklus hidup data yang paling penting namun paling memakan waktu. Diagram berikut menunjukkan bagaimana tahap persiapan dan pembersihan data sesuai dengan otomatisasi rekayasa data dan siklus hidup kontrol akses.
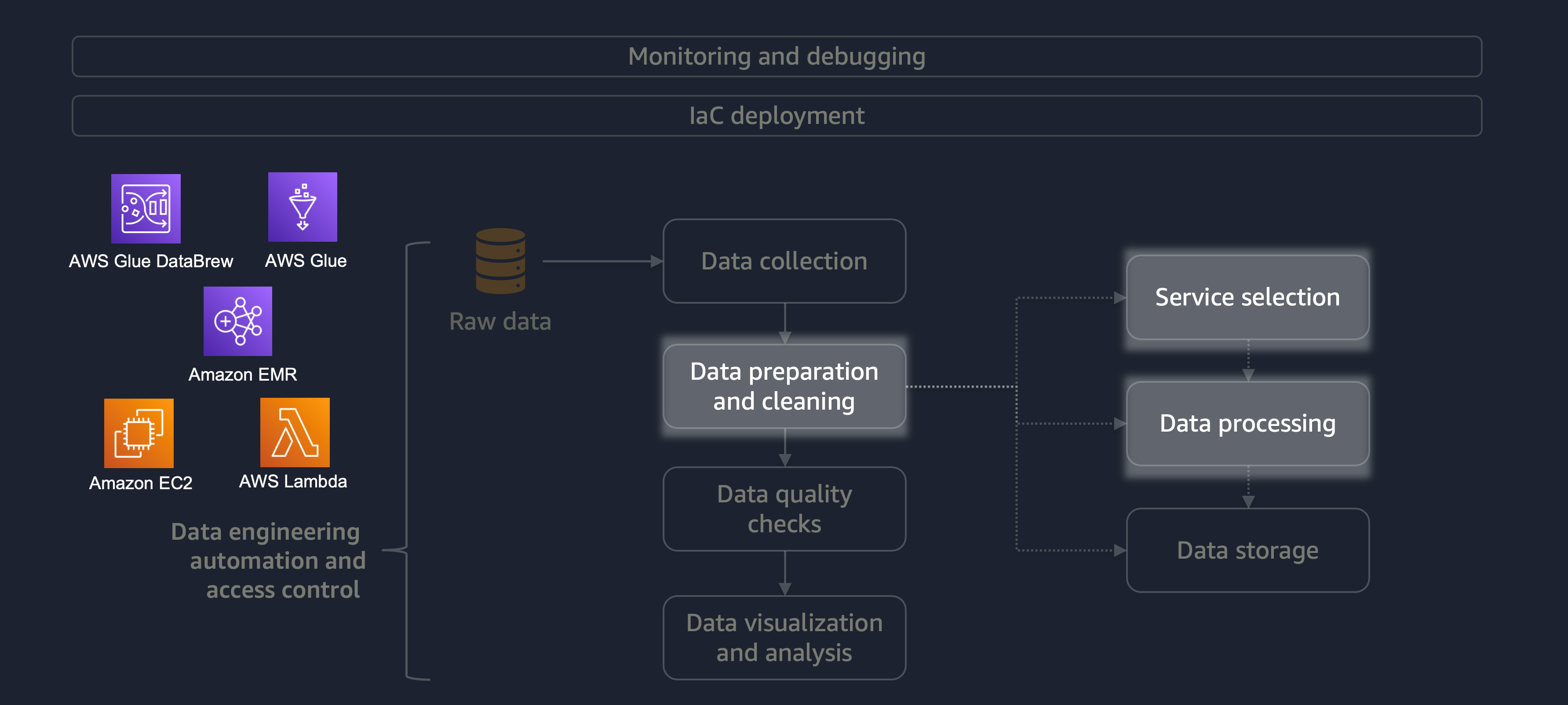
Berikut adalah beberapa contoh persiapan atau pembersihan data:
-
Memetakan kolom teks ke kode
-
Mengabaikan kolom kosong
-
Mengisi kolom data kosong dengan
0,None, atau'' -
Menganonimkan atau menutupi informasi identitas pribadi (PII)
Jika Anda memiliki beban kerja besar yang memiliki beragam data, sebaiknya gunakan Amazon EMRDataFrame pemrosesan horizontal. DynamicFrame Selain itu, Anda dapat menggunakan AWS Glue DataBrew
Untuk beban kerja yang lebih kecil yang tidak memerlukan pemrosesan terdistribusi dan dapat diselesaikan dalam waktu kurang dari 15 menit, kami menyarankan Anda menggunakan AWS
Sangat penting untuk memilih layanan AWS yang tepat untuk persiapan dan pembersihan data dan untuk memahami pengorbanan yang terkait dengan pilihan Anda. Misalnya, pertimbangkan skenario di mana Anda memilih dari AWS Glue, DataBrew, dan Amazon EMR. AWS Glue sangat ideal jika pekerjaan ETL jarang terjadi. Pekerjaan yang jarang terjadi sekali sehari, seminggu sekali, atau sebulan sekali. Anda selanjutnya dapat berasumsi bahwa insinyur data Anda mahir dalam menulis kode Spark (untuk kasus penggunaan data besar) atau skrip secara umum. Jika pekerjaan lebih sering, menjalankan AWS Glue terus-menerus bisa menjadi mahal. Dalam hal ini, Amazon EMR menyediakan kemampuan pemrosesan terdistribusi dan menawarkan versi tanpa server dan berbasis server. Jika teknisi data Anda tidak memiliki keahlian yang tepat atau jika Anda harus memberikan hasil dengan cepat, maka DataBrew itu adalah pilihan yang baik. DataBrew dapat mengurangi upaya untuk mengembangkan kode dan mempercepat persiapan data dan proses pembersihan.
Setelah pemrosesan selesai, data dari proses ETL disimpan di AWS. Pilihan penyimpanan tergantung pada jenis data yang Anda hadapi. Misalnya, Anda dapat bekerja dengan data non-relasional seperti data grafik, data pasangan nilai kunci, gambar, file teks, atau data terstruktur relasional.
Seperti yang ditunjukkan pada diagram berikut, Anda dapat menggunakan layanan AWS berikut untuk penyimpanan data:
-
Amazon S3
menyimpan data tidak terstruktur atau data semi-terstruktur (misalnya, file Apache Parquet, gambar, dan video). -
Amazon Neptunus
menyimpan kumpulan data grafik yang dapat Anda kueri dengan menggunakan SPARQL atau GREMLIN. -
Amazon Keyspaces (untuk Apache Cassandra)
menyimpan dataset yang kompatibel dengan Apache Cassandra. -
Amazon Aurora menyimpan kumpulan data
relasional. -
Amazon DynamoDB
menyimpan nilai kunci atau data dokumen dalam database NoSQL. -
Amazon Redshift
menyimpan beban kerja untuk data terstruktur di gudang data.
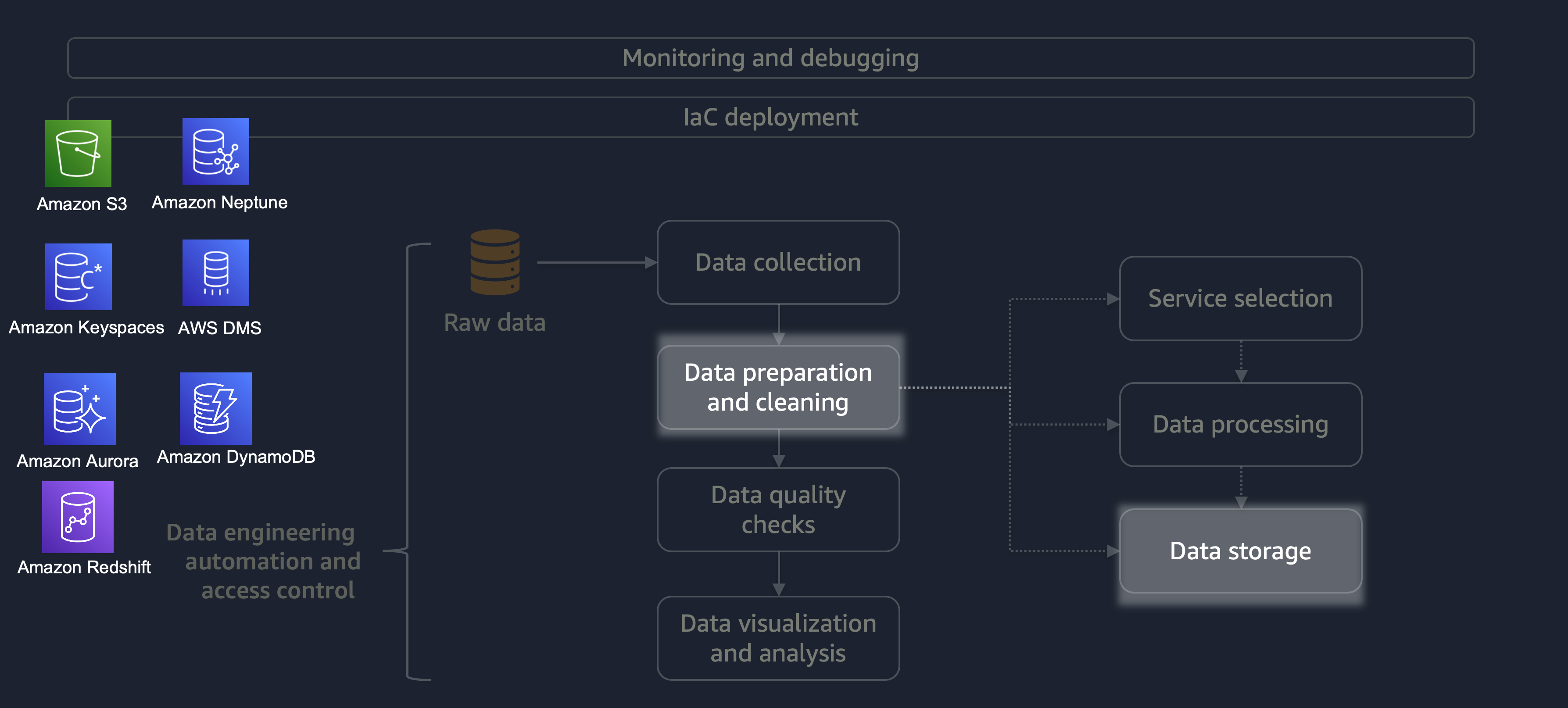
Dengan menggunakan layanan yang tepat dengan konfigurasi yang benar, Anda dapat menyimpan data Anda dengan cara yang paling efisien dan efektif. Ini meminimalkan upaya yang terlibat dalam pengambilan data.
