Terjemahan disediakan oleh mesin penerjemah. Jika konten terjemahan yang diberikan bertentangan dengan versi bahasa Inggris aslinya, utamakan versi bahasa Inggris.
Pilar efisiensi performa
Pilar efisiensi kinerja dari AWS Well-Architected Framework berfokus pada cara mengoptimalkan kinerja sambil menelan atau menanyakan data. Optimalisasi kinerja adalah proses tambahan dan berkelanjutan dari hal-hal berikut:
-
Mengonfirmasi persyaratan bisnis
-
Mengukur kinerja beban kerja
-
Mengidentifikasi komponen yang berkinerja buruk
-
Menyetel komponen untuk memenuhi kebutuhan bisnis Anda
Pilar efisiensi kinerja menyediakan pedoman khusus kasus penggunaan yang dapat membantu Anda mengidentifikasi model data grafik dan bahasa kueri yang tepat untuk digunakan. Ini juga mencakup praktik terbaik untuk diikuti saat memasukkan data ke dalam, dan mengkonsumsi data dari, Neptunus Analytics.
Pilar efisiensi kinerja berfokus pada bidang-bidang utama berikut:
-
Pemodelan grafik
-
Pengoptimalan kueri
-
Grafik ukuran kanan
-
Tulis optimasi
Memahami pemodelan grafik untuk analitik
Panduan Menerapkan Kerangka AWS Well-Architected untuk Amazon Neptunus membahas pemodelan grafik untuk efisiensi kinerja. Keputusan pemodelan yang memengaruhi kinerja termasuk memilih node dan tepi mana yang diperlukan IDs, label dan propertinya, arah tepi, apakah label harus generik atau spesifik, dan umumnya seberapa efisien mesin kueri dapat menavigasi grafik untuk memproses kueri umum.
Pertimbangan ini juga berlaku untuk Neptunus Analytics; namun, penting untuk membedakan antara pola penggunaan transaksional dan analitis. Model grafik yang efisien untuk kueri dalam database transaksional seperti database Neptunus mungkin perlu dibentuk ulang untuk analitik.
Misalnya, pertimbangkan grafik penipuan dalam database Neptunus yang tujuannya adalah untuk memeriksa pola penipuan dalam pembayaran kartu kredit. Grafik ini mungkin memiliki node yang mewakili akun, pembayaran, dan fitur (seperti alamat email, alamat IP, nomor telepon) dari akun dan pembayaran. Grafik terhubung ini mendukung kueri seperti melintasi jalur panjang variabel yang dimulai dari pembayaran tertentu dan membutuhkan beberapa lompatan untuk menemukan fitur dan akun terkait. Gambar berikut menunjukkan grafik seperti itu.
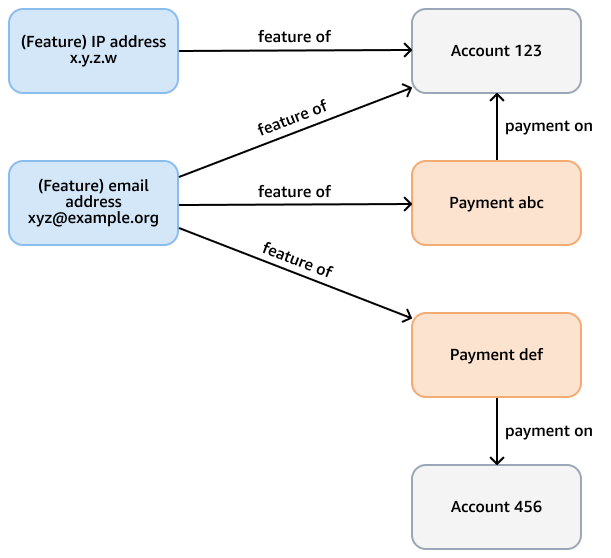
Persyaratan analitis mungkin lebih spesifik, seperti menemukan komunitas akun yang ditautkan oleh fitur. Anda dapat menggunakan algoritma komponen yang terhubung lemah (WCC) untuk tujuan ini. Untuk menjalankannya melawan model pada contoh sebelumnya tidak efisien, karena perlu melintasi beberapa jenis node dan tepi yang berbeda. Model dalam diagram berikutnya lebih efisien. Ini menghubungkan account node dengan shares feature tepi jika akun itu sendiri—atau pembayaran dari akun—berbagi fitur. Misalnya, Account 123 memiliki fitur emailxyz@example.org, dan Account 456 menggunakan email yang sama untuk pembayaran (Payment def).

Kompleksitas komputasi WCC adalahO(|E|logD), di mana |E| jumlah tepi dalam grafik, dan D merupakan diameter (panjang jalur terpanjang) yang menghubungkan node. Karena model transaksional menghilangkan node dan tepi yang tidak penting, ia mengoptimalkan jumlah tepi dan diameter, dan mengurangi kompleksitas algoritma WCC.
Saat Anda menggunakan Neptune Analytics, kerjakan kembali dari algoritme dan kueri analitis yang diperlukan. Jika perlu, bentuk kembali model untuk mengoptimalkan kueri ini. Anda dapat membentuk kembali model sebelum memuat data ke dalam grafik, atau menulis kueri yang mengubah data yang ada dalam grafik.
Optimalkan kueri
Ikuti rekomendasi ini untuk mengoptimalkan kueri Neptune Analytics:
-
Gunakan kueri berparameter dan cache rencana kueri, yang diaktifkan secara default. Saat Anda menggunakan cache paket, mesin menyiapkan kueri untuk digunakan nanti — asalkan kueri selesai dalam 100 milidetik atau kurang — yang menghemat waktu pada pemanggilan berikutnya.
-
Untuk kueri yang lambat, jalankan rencana penjelasan untuk menemukan kemacetan dan lakukan perbaikan yang sesuai.
-
Jika Anda menggunakan pencarian kesamaan vektor, putuskan apakah penyematan yang lebih kecil menghasilkan hasil kesamaan yang akurat. Anda dapat membuat, menyimpan, dan mencari embeddings yang lebih kecil dengan lebih efisien.
-
Ikuti praktik terbaik yang terdokumentasi untuk menggunakan OpenCypher di Neptune Analytics. Misalnya, gunakan peta yang diratakan dalam klausa UNWIND dan tentukan label tepi jika memungkinkan.
-
Saat Anda menggunakan algoritma grafik, pahami input dan output algoritme, kompleksitas komputasinya, dan secara luas cara kerjanya.
-
Sebelum Anda memanggil algoritma grafik, gunakan
MATCHklausa untuk meminimalkan set node input. Misalnya, untuk membatasi node untuk melakukan breadth-first search (BFS) dari, ikuti contoh yang disediakan dalam dokumentasi Neptunus Analytics. -
Filter pada label simpul dan tepi jika memungkinkan. Misalnya, BFS memiliki parameter input untuk memfilter traversal ke label node tertentu (
vertexLabel) atau label tepi tertentu (edgeLabels). -
Gunakan parameter pembatas seperti
maxDepthuntuk membatasi hasil. -
Eksperimen dengan
concurrencyparameter. Cobalah dengan nilai 0, yang menggunakan semua utas algoritma yang tersedia untuk memparalelkan pemrosesan. Bandingkan dengan eksekusi single-threaded dengan menyetel parameter ke 1. Algoritma dapat menyelesaikan lebih cepat dalam satu utas, terutama pada input yang lebih kecil seperti pencarian breadth-first dangkal di mana paralelisme tidak menawarkan pengurangan waktu eksekusi yang terukur dan mungkin menimbulkan overhead. -
Pilih di antara jenis algoritma yang serupa. Misalnya, Bellman-Ford dan delta-stepping keduanya merupakan algoritma jalur terpendek sumber tunggal. Saat menguji dengan kumpulan data Anda sendiri, coba kedua algoritme dan bandingkan hasilnya. Delta-stepping seringkali lebih cepat daripada Bellman-Ford karena kompleksitas komputasi yang lebih rendah. Namun, kinerja tergantung pada dataset dan parameter input, terutama
deltaparameter.
-
Optimalkan menulis
Ikuti praktik berikut untuk mengoptimalkan operasi penulisan di Neptunus Analytics:
-
Carilah cara paling efisien untuk memuat data ke dalam grafik. Saat Anda memuat dari data di Amazon S3, gunakan impor massal jika data berukuran lebih besar dari 50 GB. Untuk data yang lebih kecil, gunakan pemuatan batch. Jika Anda mendapatkan out-of-memory kesalahan saat menjalankan pemuatan batch, pertimbangkan untuk meningkatkan nilai m-NCU atau membagi beban menjadi beberapa permintaan. Salah satu cara untuk mencapai ini adalah dengan membagi file di beberapa awalan di bucket S3. Dalam hal ini, panggil pemuatan batch secara terpisah untuk setiap awalan.
-
Gunakan impor massal atau pemuat batch untuk mengisi kumpulan data grafik awal. Gunakan operasi transaksional OpenCypher buat, perbarui, dan hapus hanya untuk perubahan kecil.
-
Gunakan impor massal atau pemuat batch dengan konkurensi 1 (ulir tunggal) untuk menyerap penyematan ke dalam grafik. Cobalah untuk memuat embeddings di depan dengan menggunakan salah satu metode ini.
-
Nilai dimensi penyematan vektor yang diperlukan untuk pencarian kesamaan yang akurat dalam algoritma pencarian kesamaan vektor. Gunakan dimensi yang lebih kecil jika memungkinkan. Ini menghasilkan kecepatan beban yang lebih cepat untuk penyematan.
-
Gunakan algoritma mutasi untuk mengingat hasil algoritmik jika diperlukan. Misalnya, algoritma sentralitas mutasi derajat menemukan derajat setiap node input dan menulis nilai itu sebagai properti node. Jika koneksi di sekitar node tersebut tidak kemudian berubah, properti memegang hasil yang benar. Tidak perlu menjalankan algoritma lagi.
-
Gunakan tindakan administratif reset grafik untuk menghapus semua node, tepi, dan embeddings jika Anda perlu memulai dari awal. Menjatuhkan semua node, tepi, dan penyematan dengan menggunakan kueri OpenCypher tidak layak jika grafik Anda besar. Kueri drop tunggal pada kumpulan data besar dapat habis waktu. Seiring bertambahnya ukuran, kumpulan data membutuhkan waktu lebih lama untuk dihapus dan ukuran transaksi meningkat. Sebaliknya, waktu untuk menyelesaikan reset grafik kira-kira konstan, dan tindakan menyediakan opsi untuk membuat snapshot sebelum Anda menjalankannya.
Grafik ukuran kanan
Kinerja keseluruhan tergantung pada kapasitas yang disediakan dari grafik Neptunus Analytics. Kapasitas diukur dalam satuan yang disebut Unit Kapasitas Neptunus yang dioptimalkan untuk memori (m -). NCUs Pastikan grafik Anda berukuran cukup untuk mendukung ukuran grafik dan kueri Anda. Perhatikan bahwa peningkatan kapasitas tidak selalu meningkatkan kinerja kueri individu.
Jika memungkinkan, buat grafik dengan mengimpor data dari sumber yang ada seperti Amazon S3 atau cluster atau snapshot Neptunus yang ada. Anda dapat menempatkan batas pada mininum dan kapasitas maksimum. Anda juga dapat mengubah kapasitas yang disediakan pada grafik yang ada.
Pantau CloudWatch metrik sepertiNumQueuedRequestsPerSec,NumOpenCypherRequestsPerSec,GraphStorageUsagePercent,GraphSizeBytes, dan CPUUtilization untuk menilai apakah grafik berukuran tepat. Tentukan apakah lebih banyak kapasitas diperlukan untuk mendukung ukuran dan beban grafik Anda. Untuk informasi selengkapnya tentang cara menafsirkan beberapa metrik ini, lihat bagian Pilar keunggulan operasional.
