Terjemahan disediakan oleh mesin penerjemah. Jika konten terjemahan yang diberikan bertentangan dengan versi bahasa Inggris aslinya, utamakan versi bahasa Inggris.
Pemrosesan kueri SQL di Amazon Redshift
Amazon Redshift merutekan kueri SQL yang dikirimkan melalui parser dan pengoptimal untuk mengembangkan rencana kueri. Mesin eksekusi kemudian menerjemahkan rencana kueri ke dalam kode dan mengirimkan kode itu ke node komputasi untuk dieksekusi. Sebelum Anda merancang rencana kueri, penting untuk memahami cara kerja pemrosesan kueri.
Perencanaan kueri dan alur kerja eksekusi
Diagram berikut memberikan tampilan tingkat tinggi dari perencanaan kueri dan alur kerja eksekusi.
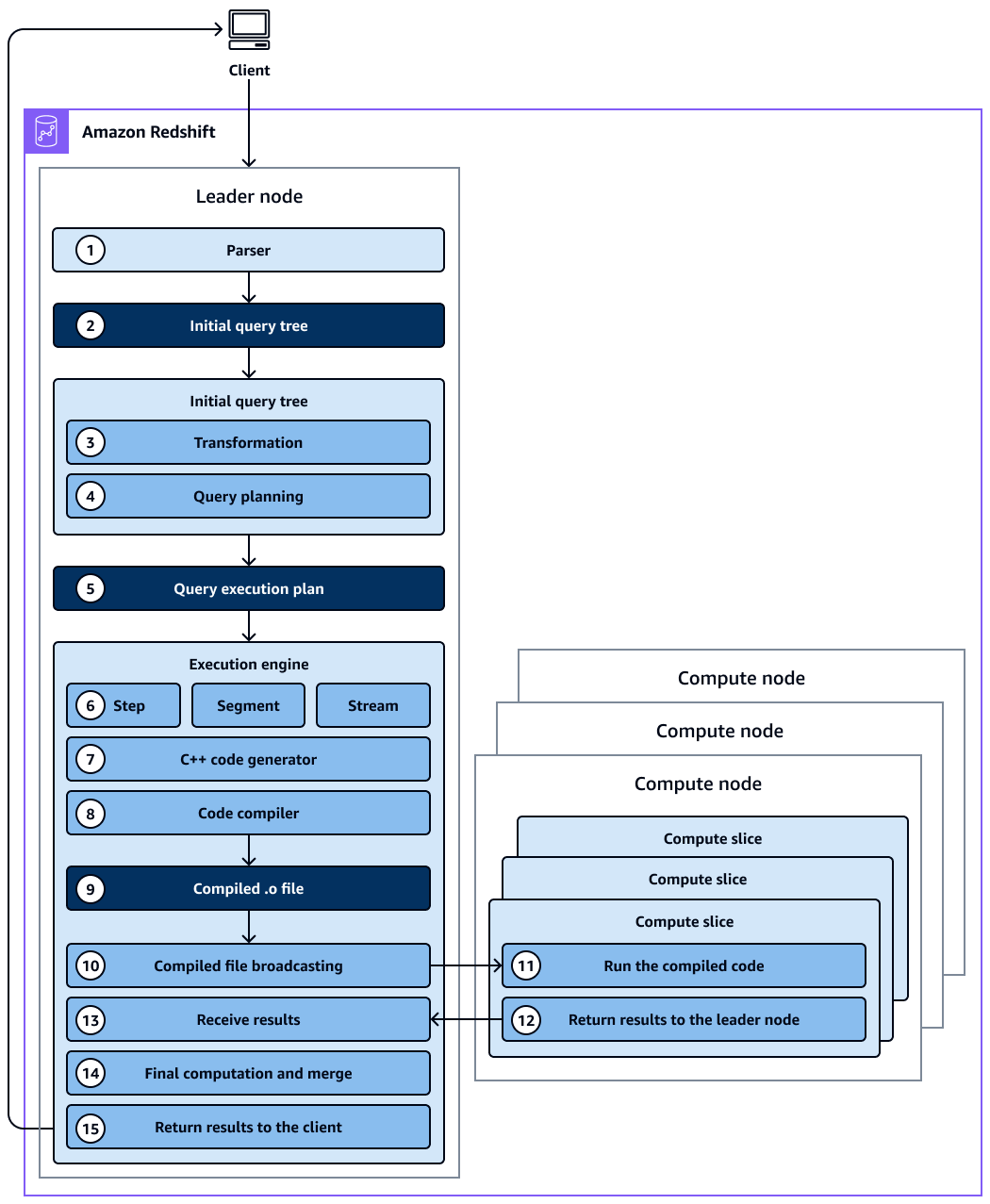
Diagram menunjukkan alur kerja berikut:
-
Node pemimpin di cluster Amazon Redshift menerima kueri dan mem-parsing pernyataan SQL.
-
Parser menghasilkan pohon kueri awal yang merupakan representasi logis dari kueri asli.
-
Pengoptimal kueri mengambil pohon kueri awal dan mengevaluasinya, menganalisis statistik tabel untuk menentukan urutan gabungan dan selektivitas predikat, dan, jika perlu, menulis ulang kueri untuk memaksimalkan efisiensinya. Terkadang kueri tunggal dapat ditulis sebagai beberapa pernyataan dependen di latar belakang.
-
Pengoptimal menghasilkan rencana kueri (atau beberapa, jika langkah sebelumnya menghasilkan beberapa kueri) untuk eksekusi dengan kinerja terbaik. Rencana kueri menentukan opsi eksekusi seperti perintah eksekusi, operasi jaringan, tipe gabungan, urutan gabungan, opsi agregasi, dan distribusi data.
-
Rencana kueri berisi informasi tentang operasi individual yang diperlukan untuk menjalankan kueri. Anda dapat menggunakan
EXPLAINperintah untuk melihat rencana kueri. Rencana kueri adalah alat mendasar untuk menganalisis dan menyetel kueri yang kompleks. -
Pengoptimal kueri mengirimkan rencana kueri ke mesin eksekusi. Mesin eksekusi memeriksa cache rencana yang dikompilasi untuk kecocokan rencana kueri dan menggunakan cache yang dikompilasi (jika ditemukan). Jika tidak, mesin eksekusi menerjemahkan rencana kueri menjadi langkah, segmen, dan aliran:
-
Langkah-langkah adalah operasi individual yang terjadi selama eksekusi kueri. Langkah-langkah diidentifikasi oleh label (misalnya,,
scandist,hjoin, ataumerge). Langkah adalah unit terkecil. Anda dapat menggabungkan langkah-langkah sehingga node komputasi dapat melakukan kueri, bergabung, atau operasi database lainnya. -
Segmen mengacu pada segmen kueri dan menggabungkan beberapa langkah yang dapat dilakukan dengan satu proses. Segmen adalah unit kompilasi terkecil yang dapat dieksekusi oleh irisan node komputasi. Slice adalah unit pemrosesan paralel di Amazon Redshift.
-
Stream adalah kumpulan segmen yang akan dibagi di atas irisan node komputasi yang tersedia. Segmen dalam aliran berjalan secara paralel di seluruh irisan node. Oleh karena itu, langkah yang sama dari segmen yang sama juga dijalankan secara paralel dalam beberapa irisan.
-
-
Generator kode menerima rencana yang diterjemahkan dan menghasilkan fungsi C++ untuk setiap segmen.
-
Fungsi C++ yang dihasilkan dikompilasi oleh GNU Compiler Collection dan dikonversi ke file O ()
.o. -
Kode yang dikompilasi (file O) berjalan. Kode yang dikompilasi berjalan lebih cepat daripada kode yang ditafsirkan dan menggunakan kapasitas komputasi yang lebih sedikit.
-
File O yang dikompilasi kemudian disiarkan ke node komputasi.
-
Setiap node komputasi terdiri dari beberapa irisan komputasi. Irisan komputasi menjalankan segmen kueri secara paralel. Amazon Redshift memanfaatkan komunikasi jaringan, memori, dan manajemen disk yang dioptimalkan untuk meneruskan hasil perantara dari satu langkah rencana kueri ke langkah berikutnya. Ini juga membantu mempercepat eksekusi kueri. Pertimbangkan hal berikut:
-
Langkah 6, 7, 8, 9, 10, dan 11 terjadi sekali untuk setiap aliran.
-
Mesin membuat segmen yang dapat dieksekusi untuk satu aliran dan mengirimkan segmen ini ke node komputasi.
-
Setelah segmen aliran sebelumnya selesai, mesin menghasilkan segmen untuk aliran berikutnya. Dengan cara ini, mesin dapat menganalisis apa yang terjadi di aliran sebelumnya (misalnya, apakah operasi berbasis disk) untuk mempengaruhi generasi segmen di aliran berikutnya.
-
-
Setelah node komputasi selesai, mereka mengembalikan hasil kueri ke node pemimpin untuk pemrosesan akhir. Node pemimpin menggabungkan data menjadi satu set hasil dan menangani penyortiran atau agregasi yang diperlukan.
-
Node pemimpin mengembalikan hasil ke klien.
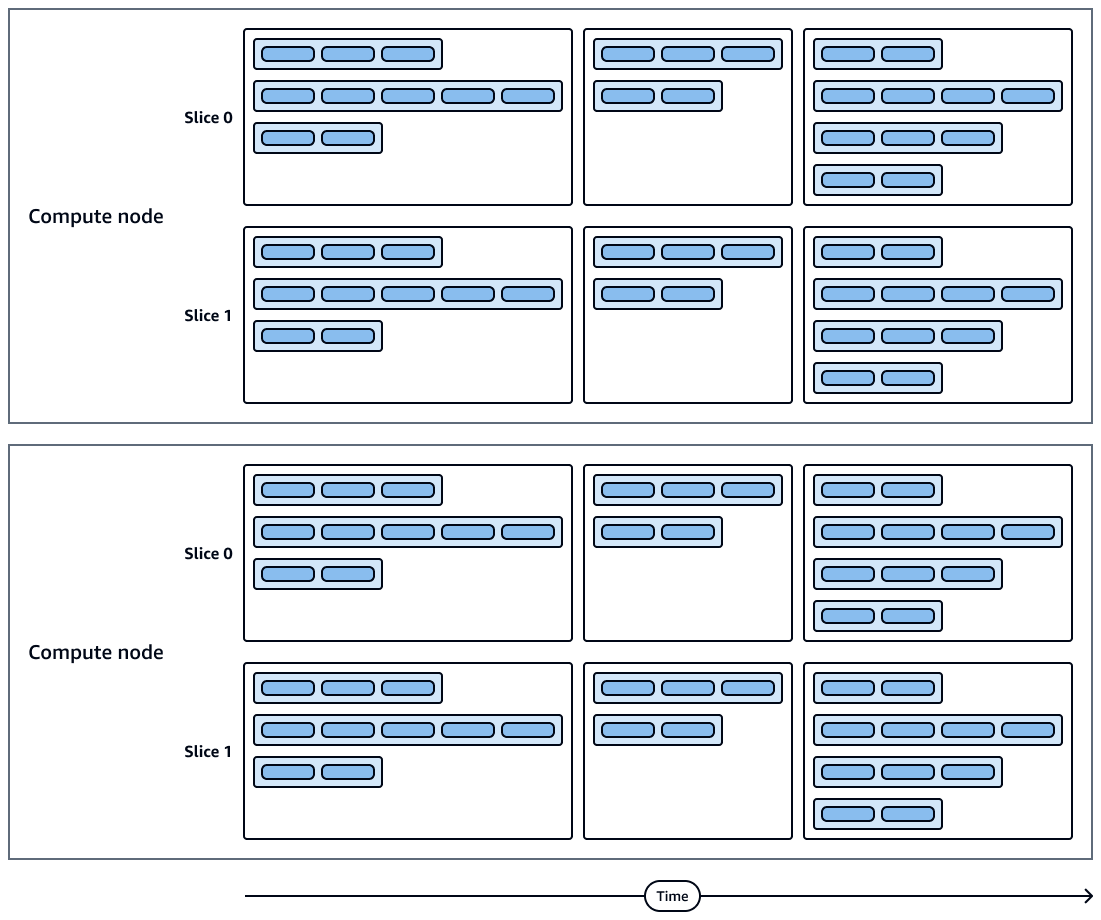
Diagram berikut menunjukkan alur kerja eksekusi aliran, segmen, langkah, dan irisan node komputasi. Ingatlah hal berikut:
-
Langkah-langkah dalam segmen berjalan secara berurutan.
-
Segmen dalam aliran berjalan secara paralel.
-
Streaming berjalan secara berurutan.
-
Hitung irisan node berjalan secara paralel.
Diagram berikut menunjukkan representasi visual dari aliran, segmen, dan langkah-langkah. Setiap segmen berisi beberapa langkah, dan setiap aliran berisi beberapa segmen.
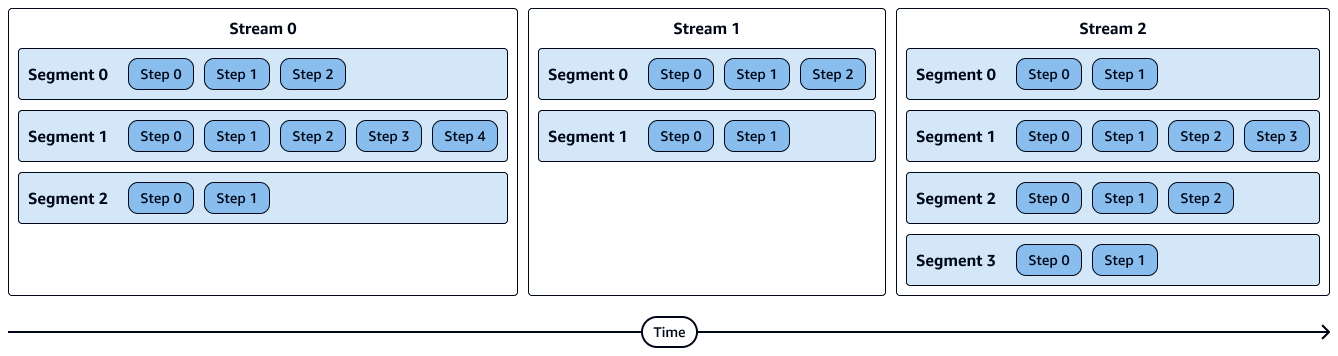
Diagram berikut menunjukkan representasi visual dari eksekusi query dan irisan node komputasi. Setiap node komputasi berisi beberapa irisan, aliran, segmen, dan langkah.
Pertimbangan tambahan
Kami menyarankan Anda mempertimbangkan hal-hal berikut sehubungan dengan pemrosesan kueri:
-
Kode yang dikompilasi dalam cache dibagikan di seluruh sesi pada cluster yang sama, sehingga eksekusi berikutnya dari kueri yang sama akan lebih cepat, seringkali bahkan dengan parameter yang berbeda.
-
Saat Anda membandingkan kueri Anda, kami sarankan Anda selalu membandingkan waktu untuk eksekusi kedua kueri, karena waktu eksekusi pertama mencakup overhead kompilasi kode. Untuk informasi selengkapnya, lihat Faktor performa kueri dalam panduan Praktik terbaik Kueri untuk Amazon Redshift.
-
Node komputasi dapat mengembalikan beberapa data ke node pemimpin selama eksekusi kueri jika perlu. Misalnya, jika Anda memiliki subquery dengan
LIMITklausa, batas diterapkan pada node pemimpin sebelum data didistribusikan kembali di seluruh cluster untuk diproses lebih lanjut.
