Terjemahan disediakan oleh mesin penerjemah. Jika konten terjemahan yang diberikan bertentangan dengan versi bahasa Inggris aslinya, utamakan versi bahasa Inggris.
Kasus penggunaan: Membangun aplikasi intelijen medis dengan data pasien yang ditambah
AI generatif dapat membantu meningkatkan perawatan pasien dan produktivitas staf dengan meningkatkan fungsi klinis dan administrasi. Analisis gambar berbasis AI, seperti menafsirkan sonogram, mempercepat proses diagnostik dan meningkatkan akurasi. Ini dapat memberikan wawasan kritis yang mendukung intervensi medis tepat waktu.
Saat Anda menggabungkan model AI generatif dengan grafik pengetahuan, Anda dapat mengotomatiskan organisasi kronologis catatan pasien elektronik. Ini membantu Anda mengintegrasikan data real-time dari interaksi dokter-pasien, gejala, diagnosis, hasil lab, dan analisis gambar. Ini melengkapi dokter dengan data pasien yang komprehensif. Data ini membantu dokter membuat keputusan medis yang lebih akurat dan tepat waktu, meningkatkan hasil pasien dan produktivitas penyedia layanan kesehatan.
Ikhtisar solusi
AI dapat memberdayakan dokter dan dokter dengan mensintesis data pasien dan pengetahuan medis untuk memberikan wawasan yang berharga. Solusi Retrieval Augmented Generation (RAG) ini adalah mesin intelijen medis yang mengkonsumsi serangkaian data dan pengetahuan pasien yang komprehensif dari jutaan interaksi klinis. Ini memanfaatkan kekuatan AI generatif untuk menciptakan wawasan berbasis bukti untuk perawatan pasien yang lebih baik. Ini dirancang untuk meningkatkan alur kerja klinis, mengurangi kesalahan, dan meningkatkan hasil pasien.
Solusinya mencakup kemampuan pemrosesan gambar otomatis yang didukung oleh. LLMs Kemampuan ini mengurangi jumlah waktu yang harus dihabiskan tenaga medis secara manual untuk mencari gambar diagnostik serupa dan menganalisis hasil diagnostik.
Gambar berikut menunjukkan end-to-end-workflow solusi ini. Ini menggunakan Amazon Neptunus, SageMaker Amazon AI, OpenSearch Amazon Service, dan model fondasi di Amazon Bedrock. Untuk agen pengambilan konteks yang berinteraksi dengan grafik pengetahuan medis di Neptunus, Anda dapat memilih antara agen Amazon Bedrock dan LangChain agen.
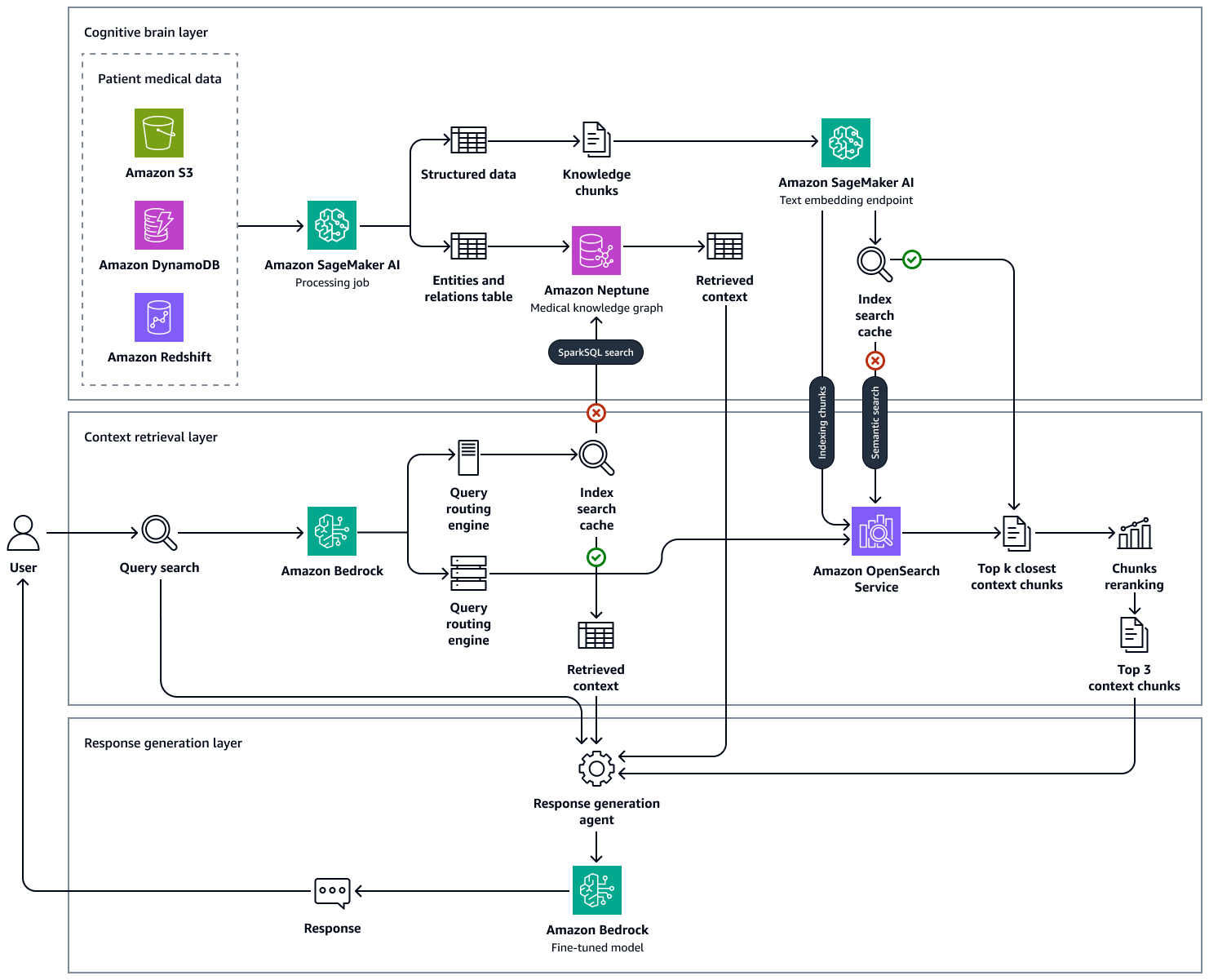
Dalam percobaan kami dengan contoh pertanyaan medis, kami mengamati bahwa tanggapan akhir yang dihasilkan oleh pendekatan kami menggunakan grafik pengetahuan yang dipertahankan di Neptunus OpenSearch, basis data vektor yang menampung basis pengetahuan klinis, dan Amazon LLMs Bedrock didasarkan pada faktualitas dan jauh lebih akurat dengan mengurangi positif palsu dan meningkatkan positif sejati. Solusi ini dapat menghasilkan wawasan berbasis bukti tentang status kesehatan pasien dan bertujuan untuk meningkatkan alur kerja klinis, mengurangi kesalahan, dan meningkatkan hasil pasien.
Membangun solusi ini terdiri dari langkah-langkah berikut:
Langkah 1: Menemukan data
Ada banyak kumpulan data medis open source yang dapat Anda gunakan untuk mendukung pengembangan solusi berbasis AI perawatan kesehatan. Salah satu dataset tersebut adalah dataset MIMIC-IV, yang merupakan dataset
Anda juga dapat menggunakan kumpulan data yang menyediakan ringkasan pelepasan pasien beranotasi dan tidak teridentifikasi yang secara khusus dikuratori untuk tujuan penelitian. Kumpulan data ringkasan pelepasan dapat membantu Anda bereksperimen dengan ekstraksi entitas, memungkinkan Anda mengidentifikasi entitas medis utama (seperti kondisi, prosedur, dan obat-obatan) dari teks. Langkah 2: Membangun grafik pengetahuan medisdalam panduan ini menjelaskan bagaimana Anda dapat menggunakan data terstruktur yang diekstraksi dari MIMIC-IV dan kumpulan data ringkasan pelepasan untuk membuat grafik pengetahuan medis. Grafik pengetahuan medis ini berfungsi sebagai tulang punggung untuk kueri tingkat lanjut dan sistem pendukung keputusan untuk profesional perawatan kesehatan.
Selain kumpulan data berbasis teks, Anda dapat menggunakan kumpulan data gambar. Misalnya, kumpulan data Musculoskeletal Radiographs (MURA)
Langkah 2: Membangun grafik pengetahuan medis
Untuk setiap organisasi perawatan kesehatan yang ingin membangun sistem pendukung keputusan berdasarkan basis pengetahuan yang besar, tantangan utama adalah menemukan dan mengekstrak entitas medis yang ada dalam catatan klinis, jurnal medis, ringkasan pelepasan, dan sumber data lainnya. Anda juga perlu menangkap hubungan temporal, subjek, dan penilaian kepastian dari catatan medis ini untuk secara efektif menggunakan entitas, atribut, dan hubungan yang diekstraksi.
Langkah pertama adalah mengekstrak konsep medis dari teks medis yang tidak terstruktur dengan menggunakan prompt beberapa tembakan untuk model pondasi, seperti Llama 3 di Amazon Bedrock. Permintaan beberapa tembakan adalah ketika Anda memberikan LLM dengan sejumlah kecil contoh yang menunjukkan tugas dan output yang diinginkan sebelum memintanya untuk melakukan tugas serupa. Menggunakan ekstraktor entitas medis berbasis LLM, Anda dapat mengurai teks medis yang tidak terstruktur dan kemudian menghasilkan representasi data terstruktur dari entitas pengetahuan medis. Anda juga dapat menyimpan atribut pasien untuk analisis hilir dan otomatisasi. Proses ekstraksi entitas mencakup tindakan berikut:
-
Ekstrak informasi tentang konsep medis, seperti penyakit, obat-obatan, peralatan medis, dosis, frekuensi obat, durasi pengobatan, gejala, prosedur medis, dan atribut yang relevan secara klinis.
-
Tangkap fitur fungsional, seperti hubungan temporal antara entitas yang diekstraksi, subjek, dan penilaian kepastian.
-
Perluas kosakata medis standar, seperti berikut ini:
-
Kode dari Klasifikasi Penyakit Internasional, Revisi ke-10, Modifikasi Klinis (ICD-10-CM
) -
Ketentuan dari Judul Subjek Medis (MeSH)
-
Konsep dari Nomenklatur Kedokteran Sistematisasi, Istilah Klinis (
SNOMED CT) -
Kode dari Unified Medical Language System (UMLS)
-
Ringkas catatan pelepasan dan dapatkan wawasan medis dari transkrip.
Gambar berikut menunjukkan ekstraksi entitas dan langkah-langkah validasi skema untuk membuat kombinasi berpasangan yang valid dari entitas, atribut, dan hubungan. Anda dapat menyimpan data yang tidak terstruktur, seperti ringkasan debit atau catatan pasien, di Amazon Simple Storage Service (Amazon S3). Anda dapat menyimpan data terstruktur, seperti data perencanaan sumber daya perusahaan (ERP), catatan pasien elektronik, dan sistem informasi lab, di Amazon Redshift dan Amazon DynamoDB. Anda dapat membangun agen pembuatan entitas Amazon Bedrock. Agen ini dapat mengintegrasikan layanan, seperti jalur ekstraksi data Amazon SageMaker AI, Amazon Textract, dan Amazon Comprehend Medical, untuk mengekstrak entitas, hubungan, dan atribut dari sumber data terstruktur dan tidak terstruktur. Terakhir, Anda menggunakan agen validasi skema Amazon Bedrock untuk memastikan bahwa entitas dan relasi yang diekstraksi sesuai dengan skema grafik yang telah ditentukan sebelumnya dan menjaga integritas koneksi tepi simpul dan properti terkait.
Setelah ekstraksi dan validasi entitas, relasi, dan atribut, Anda dapat menautkannya untuk membuat subject-object-predicate triplet. Anda menyerap data ini ke dalam database grafik Amazon Neptunus, seperti yang ditunjukkan pada gambar berikut. Database grafik dioptimalkan untuk menyimpan dan menanyakan hubungan antara item data.
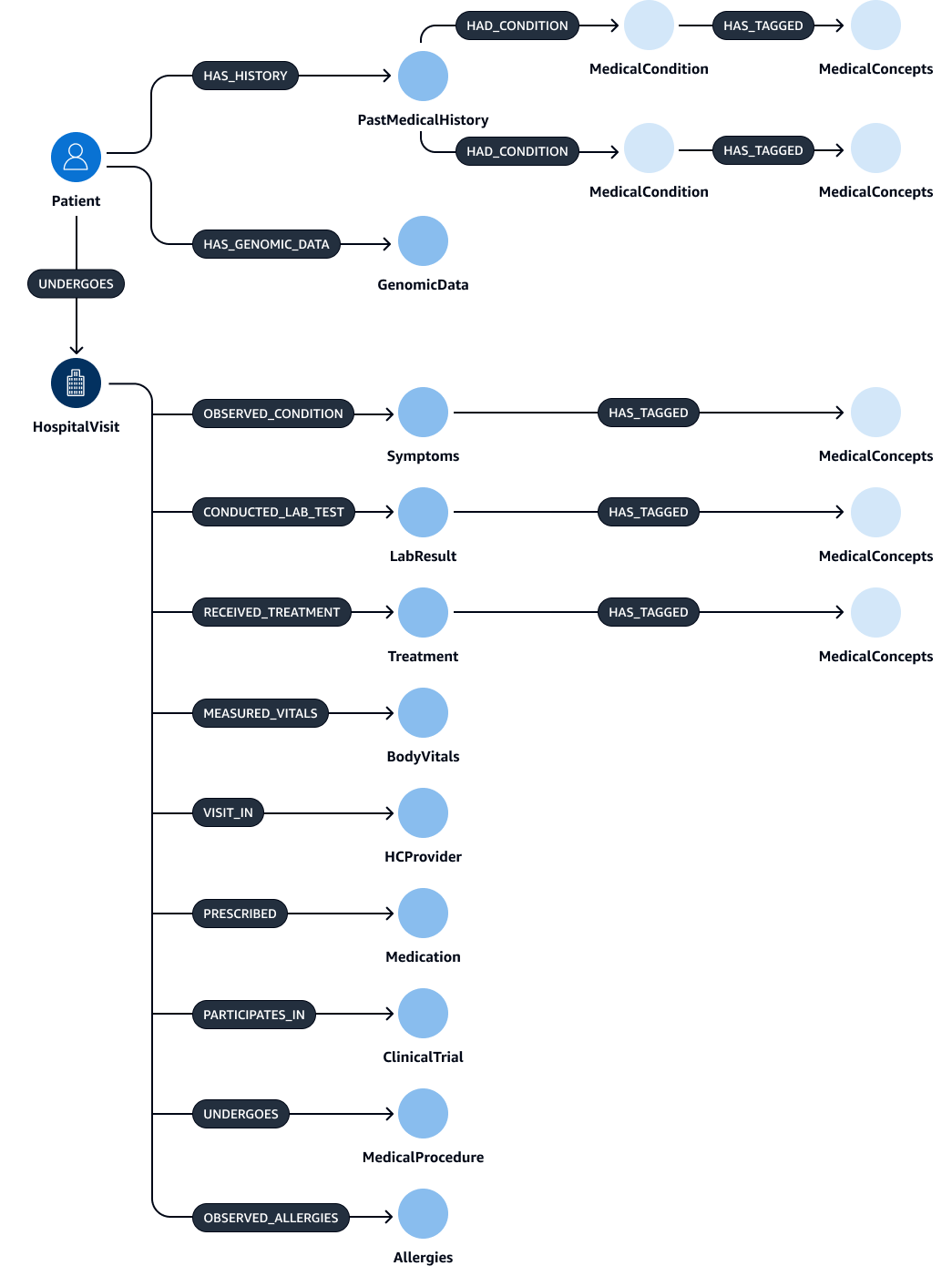
Anda dapat membuat grafik pengetahuan yang komprehensif dengan data ini. Grafik pengetahuanHospitalVisit,PastMedicalHistory,Symptoms, MedicationMedicalProcedures, danTreatment.
Tabel berikut mencantumkan entitas dan atributnya yang mungkin Anda ekstrak dari catatan pelepasan.
| Entitas | Atribut |
|---|---|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
Tabel berikut mencantumkan hubungan yang mungkin dimiliki entitas dan atribut yang sesuai. Misalnya, Patient entitas mungkin terhubung ke HospitalVisit entitas dengan [UNDERGOES] hubungan. Atribut untuk hubungan ini adalahVisitDate.
| Entitas subjek | Hubungan | Entitas objek | Atribut |
|---|---|---|---|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
Tidak ada |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
Tidak ada |
|
|
|
Tidak ada |
|
|
|
Tidak ada |
|
|
|
Tidak ada |
Langkah 3: Membangun agen pengambilan konteks untuk menanyakan grafik pengetahuan medis
Setelah Anda membangun database grafik medis, langkah selanjutnya adalah membangun agen untuk interaksi grafik. Agen mengambil konteks yang benar dan diperlukan untuk kueri yang dimasukkan oleh dokter atau dokter. Ada beberapa opsi untuk mengonfigurasi agen ini yang mengambil konteks dari grafik pengetahuan:
Agen Amazon Bedrock untuk interaksi grafik
Agen Amazon Bedrock bekerja dengan mulus dengan database grafik Amazon Neptunus. Anda dapat melakukan interaksi lanjutan melalui grup tindakan Amazon Bedrock. Grup tindakan memulai proses dengan memanggil AWS Lambda fungsi, yang menjalankan kueri Neptunus OpenCypher.
Untuk menanyakan grafik pengetahuan, Anda dapat menggunakan dua pendekatan berbeda: eksekusi kueri langsung atau kueri dengan penyematan konteks. Pendekatan ini dapat diterapkan secara independen atau digabungkan, tergantung pada kasus penggunaan spesifik dan kriteria peringkat Anda. Dengan menggabungkan kedua pendekatan, Anda dapat memberikan konteks yang lebih komprehensif untuk LLM, yang dapat meningkatkan hasil. Berikut ini adalah dua pendekatan eksekusi query:
-
Eksekusi kueri Direct Cypher tanpa embeddings — Fungsi Lambda mengeksekusi kueri langsung terhadap Neptunus tanpa pencarian berbasis penyematan. Berikut ini adalah contoh dari pendekatan ini:
MATCH (p:Patient)-[u:UNDERGOES]->(h:HospitalVisit) WHERE h.Reason = 'Acute Diabetes' AND date(u.VisitDate) > date('2024-01-01') RETURN p.PatientID, p.Name, p.Age, p.Gender, p.Address, p.ContactInformation -
Eksekusi kueri Cypher langsung menggunakan pencarian penyematan - Fungsi Lambda menggunakan pencarian penyematan untuk meningkatkan hasil kueri. Pendekatan ini meningkatkan eksekusi query dengan menggabungkan embeddings, yang merupakan representasi vektor padat data. Embeddings sangat berguna ketika kueri membutuhkan kesamaan semantik atau pemahaman yang lebih luas di luar kecocokan yang tepat. Anda dapat menggunakan model pra-terlatih atau terlatih khusus untuk menghasilkan embeddings untuk setiap kondisi medis. Berikut ini adalah contoh dari pendekatan ini:
CALL { WITH "Acute Diabetes" AS query_term RETURN search_embedding(query_term) AS similar_reasons } MATCH (p:Patient)-[u:UNDERGOES]->(h:HospitalVisit) WHERE h.Reason IN similar reasons AND date(u.VisitDate) > date('2024-01-01') RETURN p.PatientID, p.Name, p.Age, p.Gender, p.Address, p.ContactInformationDalam contoh ini,
search_embedding("Acute Diabetes")fungsi mengambil kondisi yang secara semantik dekat dengan “Diabetes Akut.” Ini membantu pertanyaan untuk juga menemukan pasien yang memiliki kondisi seperti pra-diabetes atau sindrom metabolik.
Gambar berikut menunjukkan bagaimana agen Amazon Bedrock berinteraksi dengan Amazon Neptunus untuk melakukan kueri Cypher dari grafik pengetahuan medis.
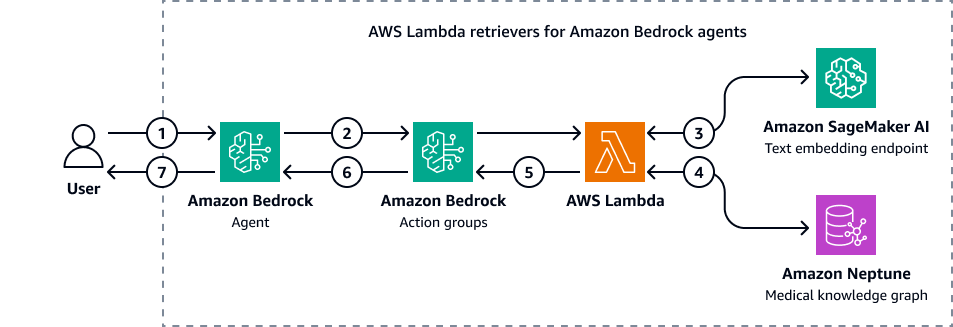
Diagram menunjukkan alur kerja berikut:
-
Pengguna mengirimkan pertanyaan ke agen Amazon Bedrock.
-
Agen Amazon Bedrock meneruskan variabel filter pertanyaan dan input ke grup tindakan Amazon Bedrock. Grup tindakan ini berisi AWS Lambda fungsi yang berinteraksi dengan titik akhir penyematan teks Amazon SageMaker AI dan grafik pengetahuan medis Amazon Neptunus.
-
Fungsi Lambda terintegrasi dengan titik akhir penyematan teks SageMaker AI untuk melakukan pencarian semantik dalam kueri OpenCypher. Ini mengubah kueri bahasa alami menjadi kueri OpenCypher dengan menggunakan dasar LangChain agen.
-
Fungsi Lambda menanyakan grafik pengetahuan medis Neptunus untuk dataset yang benar dan menerima output dari grafik pengetahuan medis Neptunus.
-
Fungsi Lambda mengembalikan hasil dari Neptunus ke grup aksi Amazon Bedrock.
-
Grup aksi Amazon Bedrock mengirim konteks yang diambil ke agen Amazon Bedrock.
-
Agen Amazon Bedrock menghasilkan respons dengan menggunakan kueri pengguna asli dan konteks yang diambil dari grafik pengetahuan.
LangChain agen untuk interaksi grafik
Anda dapat mengintegrasikan LangChain dengan Neptunus untuk mengaktifkan kueri dan pengambilan berbasis grafik. Pendekatan ini dapat meningkatkan alur kerja berbasis AI dengan menggunakan kemampuan database grafik di Neptunus. Kebiasaan LangChain retriever bertindak sebagai perantara. Model dasar di Amazon Bedrock dapat berinteraksi dengan Neptunus dengan menggunakan kueri Cypher langsung dan algoritma grafik yang lebih kompleks.
Anda dapat menggunakan retriever kustom untuk menyempurnakan bagaimana LangChain agen berinteraksi dengan algoritma grafik Neptunus. Misalnya, Anda dapat menggunakan beberapa bidikan bidikan, yang membantu Anda menyesuaikan respons model fondasi berdasarkan pola atau contoh tertentu. Anda juga dapat menerapkan filter yang diidentifikasi LLM untuk menyempurnakan konteks dan meningkatkan ketepatan respons. Ini dapat meningkatkan efisiensi dan akurasi proses pengambilan keseluruhan saat berinteraksi dengan data grafik yang kompleks.
Gambar berikut menunjukkan bagaimana kustom LangChain agen mengatur interaksi antara model yayasan Amazon Bedrock dan grafik pengetahuan medis Amazon Neptunus.
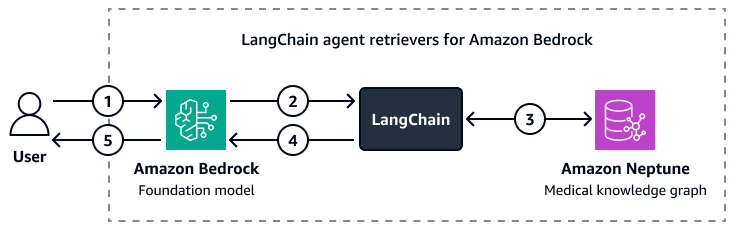
Diagram menunjukkan alur kerja berikut:
-
Seorang pengguna mengirimkan pertanyaan ke Amazon Bedrock dan LangChain agen.
-
Model fondasi Amazon Bedrock menggunakan skema Neptunus, yang disediakan oleh LangChain agen, untuk menghasilkan kueri untuk pertanyaan pengguna.
-
Bagian LangChain agen menjalankan kueri terhadap grafik pengetahuan medis Amazon Neptunus.
-
Bagian LangChain agen mengirimkan konteks yang diambil ke model yayasan Amazon Bedrock.
-
Model dasar Amazon Bedrock menggunakan konteks yang diambil untuk menghasilkan jawaban atas pertanyaan pengguna.
Langkah 4: Membuat basis pengetahuan data deskriptif real-time
Selanjutnya, Anda membuat basis pengetahuan catatan interaksi dokter-pasien deskriptif waktu nyata, penilaian gambar diagnostik, dan laporan analisis lab. Basis pengetahuan ini adalah database vektor
Menggunakan basis pengetahuan medis OpenSearch Layanan
Amazon OpenSearch Service dapat mengelola volume besar data medis berdimensi tinggi. Ini adalah layanan terkelola yang memfasilitasi pencarian berkinerja tinggi dan analitik real-time. Ini sangat cocok sebagai database vektor untuk aplikasi RAG. OpenSearch Layanan bertindak sebagai alat backend untuk mengelola sejumlah besar data tidak terstruktur atau semi-terstruktur, seperti catatan medis, artikel penelitian, dan catatan klinis. Kemampuan pencarian semantik canggihnya membantu Anda mengambil informasi yang relevan secara kontekstual. Ini membuatnya sangat berguna dalam aplikasi seperti sistem pendukung keputusan klinis, alat resolusi kueri pasien, dan sistem manajemen pengetahuan perawatan kesehatan. Misalnya, seorang dokter dapat dengan cepat menemukan data pasien yang relevan atau studi penelitian yang sesuai dengan gejala atau protokol pengobatan tertentu. Ini membantu dokter membuat keputusan yang diinformasikan oleh informasi yang paling up-to-date dan relevan.
OpenSearch Layanan dapat menskalakan dan menangani pengindeksan dan kueri data secara real-time. Ini membuatnya ideal untuk lingkungan perawatan kesehatan yang dinamis di mana akses tepat waktu ke informasi yang akurat sangat penting. Selain itu, ia memiliki kemampuan pencarian multi-modal yang optimal untuk pencarian yang memerlukan banyak input, seperti gambar medis dan catatan dokter. Saat menerapkan OpenSearch Layanan untuk aplikasi perawatan kesehatan, penting bagi Anda untuk menentukan bidang dan pemetaan yang tepat untuk mengoptimalkan pengindeksan dan pengambilan data. Bidang mewakili potongan data individu, seperti catatan pasien, riwayat medis, dan kode diagnostik. Pemetaan menentukan bagaimana bidang ini disimpan (dalam bentuk penyematan atau bentuk asli) dan ditanyakan. Untuk aplikasi perawatan kesehatan, penting untuk membuat pemetaan yang mengakomodasi berbagai tipe data, termasuk data terstruktur (seperti hasil tes numerik), data semi-terstruktur (seperti catatan pasien), dan data tidak terstruktur (seperti gambar medis)
Di OpenSearch Layanan, Anda dapat melakukan kueri penelusuran saraf
Membuat arsitektur RAG
Anda dapat menerapkan solusi RAG khusus yang menggunakan agen Amazon Bedrock untuk menanyakan basis pengetahuan medis di Layanan. OpenSearch Untuk mencapai hal ini, Anda membuat AWS Lambda fungsi yang dapat berinteraksi dengan dan query OpenSearch Service. Fungsi Lambda menyematkan pertanyaan masukan pengguna dengan mengakses titik akhir penyematan teks SageMaker AI. Agen Amazon Bedrock meneruskan parameter kueri tambahan sebagai input ke fungsi Lambda. Fungsi ini menanyakan basis pengetahuan medis di OpenSearch Layanan, yang mengembalikan konten medis yang relevan. Setelah Anda mengatur fungsi Lambda, tambahkan sebagai grup tindakan dalam agen Amazon Bedrock. Agen Amazon Bedrock mengambil input pengguna, mengidentifikasi variabel yang diperlukan, meneruskan variabel dan pertanyaan ke fungsi Lambda, dan kemudian memulai fungsi. Fungsi mengembalikan konteks yang membantu model dasar memberikan jawaban yang lebih akurat untuk pertanyaan pengguna.
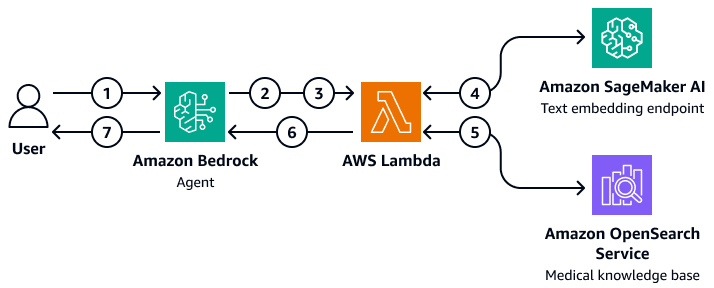
Diagram menunjukkan alur kerja berikut:
-
Seorang pengguna mengirimkan pertanyaan ke agen Amazon Bedrock.
-
Agen Amazon Bedrock memilih grup tindakan mana yang akan dimulai.
-
Agen Amazon Bedrock memulai AWS Lambda fungsi dan meneruskan parameter ke sana.
-
Fungsi Lambda memulai model penyematan teks Amazon SageMaker AI untuk menyematkan pertanyaan pengguna.
-
Fungsi Lambda meneruskan teks yang disematkan dan parameter serta filter tambahan ke Layanan Amazon OpenSearch . Amazon OpenSearch Service menanyakan basis pengetahuan medis dan mengembalikan hasilnya ke fungsi Lambda.
-
Fungsi Lambda meneruskan hasilnya kembali ke agen Amazon Bedrock.
-
Model dasar di agen Amazon Bedrock menghasilkan respons berdasarkan hasil dan mengembalikan respons kepada pengguna.
Untuk situasi di mana penyaringan yang lebih kompleks terlibat, Anda dapat menggunakan kustom LangChain retriever. Buat retriever ini dengan menyiapkan klien pencarian vektor OpenSearch Layanan yang dimuat langsung ke LangChain. Arsitektur ini memungkinkan Anda untuk melewati lebih banyak variabel untuk membuat parameter filter. Setelah retriever diatur, gunakan model Amazon Bedrock dan retriever untuk menyiapkan rantai penjawab pertanyaan pengambilan. Rantai ini mengatur interaksi antara model dan retriever dengan meneruskan input pengguna dan filter potensial ke retriever. Retriever mengembalikan konteks yang relevan yang membantu model dasar menjawab pertanyaan pengguna.
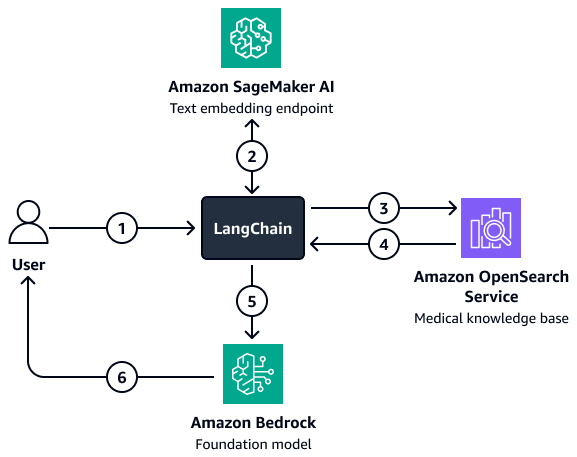
Diagram menunjukkan alur kerja berikut:
-
Seorang pengguna mengajukan pertanyaan ke LangChain agen retriever.
-
Bagian LangChain agen retriever mengirimkan pertanyaan ke titik akhir penyematan teks Amazon SageMaker AI untuk menyematkan pertanyaan.
-
Bagian LangChain agen retriever meneruskan teks yang disematkan ke Amazon OpenSearch Service.
-
Amazon OpenSearch Service mengembalikan dokumen yang diambil ke LangChain agen retriever.
-
Bagian LangChain agen retriever meneruskan pertanyaan pengguna dan mengambil konteks ke model dasar Amazon Bedrock.
-
Model foundation menghasilkan respons dan mengirimkannya ke pengguna.
Langkah 5: Gunakan LLMs untuk menjawab pertanyaan medis
Langkah-langkah sebelumnya membantu Anda membangun aplikasi intelijen medis yang dapat mengambil catatan medis pasien dan merangkum obat-obatan yang relevan dan diagnosis potensial. Sekarang, Anda membangun layer generasi. Lapisan ini menggunakan kemampuan generatif LLM di Amazon Bedrock, seperti Llama 3, untuk menambah output aplikasi.
Ketika seorang dokter memasukkan kueri, lapisan pengambilan konteks aplikasi melakukan proses pengambilan dari grafik pengetahuan dan mengembalikan catatan teratas yang berkaitan dengan riwayat, demografi, gejala, diagnosis, dan hasil pasien. Dari database vektor, ia juga mengambil catatan interaksi dokter-pasien deskriptif waktu nyata, wawasan penilaian gambar diagnostik, ringkasan laporan analisis laboratorium, dan wawasan dari kumpulan besar penelitian medis dan buku akademik. Hasil teratas yang diambil ini, kueri dokter, dan petunjuknya (yang disesuaikan untuk menyusun jawaban berdasarkan sifat kueri), kemudian diteruskan ke model dasar di Amazon Bedrock. Ini adalah lapisan generasi respons. LLM menggunakan konteks yang diambil untuk menghasilkan respons terhadap permintaan dokter. Gambar berikut menunjukkan end-to-end alur kerja langkah-langkah dalam solusi ini.
Anda dapat menggunakan model dasar pra-terlatih di Amazon Bedrock, seperti Llama 3, untuk berbagai kasus penggunaan yang harus ditangani oleh aplikasi intelijen medis. LLM yang paling efektif untuk tugas tertentu bervariasi tergantung pada kasus penggunaan. Misalnya, model pra-pelatihan mungkin cukup untuk meringkas percakapan pasien-dokter, mencari melalui obat-obatan dan riwayat pasien, dan mengambil wawasan dari kumpulan data medis internal dan badan pengetahuan ilmiah. Namun, LLM yang disetel dengan baik mungkin diperlukan untuk kasus penggunaan kompleks lainnya, seperti evaluasi laboratorium waktu nyata, rekomendasi prosedur medis, dan prediksi hasil pasien. Anda dapat menyempurnakan LLM dengan melatihnya pada kumpulan data domain medis. Persyaratan perawatan kesehatan dan ilmu hayati yang spesifik atau kompleks mendorong pengembangan model yang disetel dengan baik ini.
Untuk informasi lebih lanjut tentang menyempurnakan LLM atau memilih LLM yang ada yang telah dilatih pada data domain medis, lihat Menggunakan model bahasa besar untuk perawatan kesehatan dan kasus penggunaan ilmu hayati.
Penyelarasan dengan Kerangka AWS Well-Architected
Solusinya sejalan dengan keenam pilar Kerangka AWS Well-Architected
-
Keunggulan operasional — Arsitektur dipisahkan untuk pemantauan dan pembaruan yang efisien. Agen Amazon Bedrock dan AWS Lambda membantu Anda menyebarkan dan memutar kembali alat dengan cepat.
-
Keamanan — Solusi ini dirancang untuk mematuhi peraturan perawatan kesehatan, seperti HIPAA. Anda juga dapat menerapkan enkripsi, kontrol akses berbutir halus, dan pagar pembatas Amazon Bedrock untuk membantu melindungi data pasien.
-
Keandalan - layanan AWS terkelola, seperti Amazon OpenSearch Service dan Amazon Bedrock, menyediakan infrastruktur untuk interaksi model berkelanjutan.
-
Efisiensi kinerja — Solusi RAG mengambil data yang relevan dengan cepat menggunakan pencarian semantik yang dioptimalkan dan kueri Cypher, sementara router agen mengidentifikasi rute optimal untuk kueri pengguna.
-
Optimalisasi biaya — pay-per-token Model dalam arsitektur Amazon Bedrock dan RAG mengurangi biaya inferensi dan pra-pelatihan.
-
Keberlanjutan — Menggunakan infrastruktur tanpa server dan pay-per-token komputasi meminimalkan penggunaan sumber daya dan meningkatkan keberlanjutan.
