Terjemahan disediakan oleh mesin penerjemah. Jika konten terjemahan yang diberikan bertentangan dengan versi bahasa Inggris aslinya, utamakan versi bahasa Inggris.
Memahami Generasi Augmented Retrieval
Retrieval Augmented Generation (RAG) adalah teknik yang digunakan untuk menambah model bahasa besar (LLM) dengan data eksternal, seperti dokumen internal perusahaan. Ini memberikan model dengan konteks yang dibutuhkan untuk menghasilkan output yang akurat dan berguna untuk kasus penggunaan spesifik Anda. RAG adalah pendekatan pragmatis dan efektif untuk digunakan LLMs dalam suatu perusahaan. Diagram berikut menunjukkan gambaran tingkat tinggi tentang cara kerja pendekatan RAG.
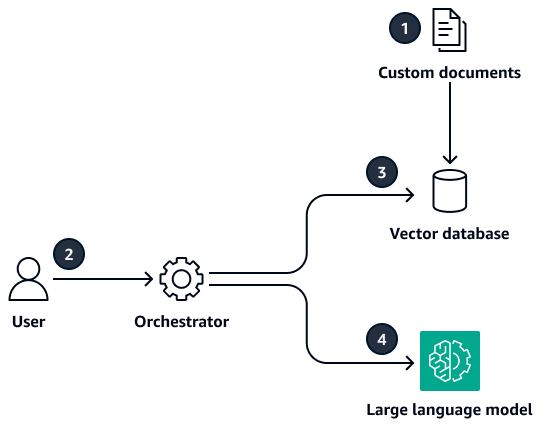
Secara garis besar, proses RAG adalah empat langkah. Langkah pertama dilakukan sekali, dan tiga langkah lainnya dilakukan sebanyak yang diperlukan:
-
Anda membuat embeddings untuk menelan dokumen internal ke dalam database vektor. Embeddings adalah representasi numerik teks dalam dokumen yang menangkap makna semantik atau kontekstual dari data. Database vektor pada dasarnya adalah database dari embeddings ini, dan kadang-kadang disebut penyimpanan vektor atau indeks vektor. Langkah ini membutuhkan pembersihan data, pemformatan, dan chunking, tetapi ini adalah aktivitas satu kali di muka.
-
Seorang manusia mengirimkan kueri dalam bahasa alami.
-
Orkestrator melakukan pencarian kesamaan dalam database vektor dan mengambil data yang relevan. Orkestrator menambahkan data yang diambil (juga dikenal sebagai konteks) ke prompt yang berisi kueri.
-
Orkestrator mengirimkan kueri dan konteks ke LLM. LLM menghasilkan respons terhadap kueri dengan menggunakan konteks tambahan.
Dari perspektif pengguna, RAG terlihat seperti berinteraksi dengan LLM apa pun. Namun, sistem tahu lebih banyak tentang konten yang dimaksud dan memberikan jawaban yang disesuaikan dengan basis pengetahuan organisasi.
Untuk informasi selengkapnya tentang cara kerja pendekatan RAG, lihat Apa itu RAG di situs
Komponen sistem RAG tingkat produksi
Membangun sistem RAG tingkat produksi membutuhkan pemikiran melalui beberapa aspek yang berbeda dari alur kerja RAG. Secara konseptual, alur kerja RAG tingkat produksi memerlukan kemampuan dan komponen berikut, terlepas dari implementasi spesifiknya:
-
Konektor — Ini menghubungkan sumber data perusahaan yang berbeda dengan database vektor. Contoh sumber data terstruktur termasuk database transaksional dan analitis. Contoh sumber data yang tidak terstruktur termasuk penyimpanan objek, basis kode, dan platform perangkat lunak sebagai layanan (SaaS). Setiap sumber data mungkin memerlukan pola konektivitas, lisensi, dan konfigurasi yang berbeda.
-
Pemrosesan data — Data datang dalam berbagai bentuk dan bentuk, seperti PDFs, gambar yang dipindai, dokumen, presentasi, dan Microsoft SharePoint berkas. Anda harus menggunakan teknik pemrosesan data untuk mengekstrak, memproses, dan menyiapkan data untuk pengindeksan.
-
Embeddings — Untuk melakukan pencarian relevansi, Anda harus mengonversi dokumen dan kueri pengguna Anda ke dalam format yang kompatibel. Dengan menggunakan menyematkan model bahasa, Anda mengonversi dokumen menjadi representasi numerik. Ini pada dasarnya adalah input untuk model pondasi yang mendasarinya.
-
Database vektor — Database vektor adalah indeks dari embeddings, teks terkait, dan metadata. Indeks dioptimalkan untuk pencarian dan pengambilan.
-
Retriever — Untuk kueri pengguna, retriever mengambil konteks yang relevan dari database vektor dan memberi peringkat tanggapan berdasarkan persyaratan bisnis.
-
Model pondasi — Model dasar untuk sistem RAG biasanya LLM. Dengan memproses konteks dan prompt, model pondasi menghasilkan dan memformat respons bagi pengguna.
-
Pagar pembatas dirancang untuk memastikan bahwa kueri, konteks yang cepat, diambil, dan respons LLM akurat, bertanggung jawab, etis, dan bebas dari halusinasi dan bias.
-
Orkestrator - Orkestrator bertanggung jawab untuk menjadwalkan dan mengelola alur kerja. end-to-end
-
Pengalaman pengguna — Biasanya, pengguna berinteraksi dengan antarmuka obrolan percakapan yang memiliki fitur yang kaya, termasuk menampilkan riwayat obrolan dan mengumpulkan umpan balik pengguna tentang tanggapan.
-
Identitas dan manajemen pengguna - Sangat penting untuk mengontrol akses pengguna ke aplikasi dengan perincian yang baik. Dalam AWS Cloud, kebijakan, peran, dan izin biasanya dikelola melalui AWS Identity and Access Management (IAM).
Jelas, ada sejumlah besar pekerjaan untuk merencanakan, mengembangkan, merilis, dan mengelola sistem RAG. Layanan yang dikelola sepenuhnya, seperti Amazon Bedrock atau Amazon Q Business, dapat membantu Anda mengelola beberapa angkat berat yang tidak berdiferensiasi. Namun, arsitektur RAG kustom dapat memberikan kontrol lebih besar atas komponen, seperti retriever atau database vektor.
