Terjemahan disediakan oleh mesin penerjemah. Jika konten terjemahan yang diberikan bertentangan dengan versi bahasa Inggris aslinya, utamakan versi bahasa Inggris.
Menggunakan petunjuk bergabung di Spark SQL
Dengan Spark 3.0, Anda dapat menentukan jenis algoritma bergabung yang Anda inginkan Spark untuk digunakan saat runtime. Strategi bergabung mengisyaratkan,,,BROADCAST, dan MERGE SHUFFLE_HASHSHUFFLE_REPLICATE_NL, menginstruksikan Spark untuk menggunakan strategi yang diisyaratkan pada setiap hubungan yang ditentukan ketika bergabung dengan mereka dengan relasi lain. Bagian ini membahas petunjuk strategi bergabung secara rinci.
MENYIARKAN
Dalam Broadcast Hash join, salah satu dataset secara signifikan lebih kecil dari yang lain. Karena kumpulan data yang lebih kecil dapat dimasukkan ke dalam memori, itu disiarkan ke semua pelaksana di cluster. Setelah data disiarkan, gabungan hash standar dilakukan. Gabungan Broadcast Hash terjadi dalam dua langkah:
-
Broadcast — Dataset yang lebih kecil disiarkan ke semua pelaksana dalam cluster.
-
Hash join — Dataset yang lebih kecil di-hash di semua pelaksana dan kemudian bergabung dengan dataset yang lebih besar.
Tidak ada sort atau merge operasi. Saat menggabungkan tabel fakta besar dengan tabel dimensi yang lebih kecil yang digunakan untuk melakukan gabungan skema bintang, Broadcast Hash adalah algoritma gabungan tercepat. Contoh berikut menunjukkan cara kerja Broadcast Hash join. Sisi gabungan dengan petunjuk disiarkan, terlepas dari batas ukuran yang ditentukan dalam properti. spark.sql.autoBroadcastJoinThreshold Jika kedua sisi gabungan memiliki petunjuk siaran, yang dengan ukuran lebih kecil (berdasarkan statistik) disiarkan. Nilai default untuk spark.sql.autoBroadcastJoinThreshold properti adalah 10 MB. Ini mengonfigurasi ukuran maksimum, dalam byte, untuk tabel yang disiarkan ke semua node pekerja saat melakukan gabungan.
Contoh berikut memberikan kueri, EXPLAIN rencana fisik, dan waktu yang dibutuhkan untuk menjalankan kueri. Kueri membutuhkan lebih sedikit waktu pemrosesan jika Anda menggunakan BROADCASTJOIN petunjuk untuk memaksa siaran bergabung, seperti yang ditunjukkan dalam EXPLAIN paket contoh kedua.
SQL Query : select table1.id,table1.col,table2.id,table2.int_col from table1 join table2 on table1.id = table2.id == Physical Plan == AdaptiveSparkPlan isFinalPlan=false +- SortMergeJoin [id#80L], [id#95L], Inner :- Sort [id#80L ASC NULLS FIRST], false, 0 : +- Exchange hashpartitioning(id#80L, 36), ENSURE_REQUIREMENTS, [id=#725] : +- Filter isnotnull(id#80L) : +- Scan ExistingRDD[id#80L,col#81] +- Sort [id#95L ASC NULLS FIRST], false, 0 +- Exchange hashpartitioning(id#95L, 36), ENSURE_REQUIREMENTS, [id=#726] +- Filter isnotnull(id#95L) +- Scan ExistingRDD[id#95L,int_col#96L] Number of records processed: 799541 Querytime : 21.87715196 seconds
SQL Query : select /*+ BROADCASTJOIN(table1)*/ table1.id,table1.col,table2.id,table2.int_col from table1 join table2 on table1.id = table2.id Physical Plan == AdaptiveSparkPlan isFinalPlan=false\n +- BroadcastHashJoin [id#271L], [id#286L], Inner, BuildLeft, false :- BroadcastExchange HashedRelationBroadcastMode(List(input[0, bigint, false]),false), [id=#955] : +- Filter isnotnull(id#271L) : +- Scan ExistingRDD[id#271L,col#272] +- Filter isnotnull(id#286L) +- Scan ExistingRDD[id#286L,int_col#287L] Number of records processed: 799541 Querytime : 15.35717314 seconds
MERGE
Gabungan Shuffle Sort Merge lebih disukai ketika kedua kumpulan data berukuran besar dan tidak dapat masuk ke dalam memori. Seperti namanya, gabungan ini melibatkan tiga fase berikut:
-
Fase acak - Kedua kumpulan data dalam kueri gabungan diacak.
-
Fase pengurutan - Catatan diurutkan berdasarkan tombol gabungan di kedua sisi.
-
Fase gabungan - Kedua sisi kondisi gabungan diulang, berdasarkan kunci gabungan.
Gambar berikut menunjukkan visualisasi Directed Acyclic Graph (DAG) dari gabungan Shuffle Sort Merge. Kedua tabel dibaca dalam dua tahap pertama. Pada tahap berikutnya (tahap 17), mereka dikocokkan, disortir, dan kemudian digabungkan bersama di akhir.
Catatan: Beberapa tahapan dalam gambar ini ditampilkan sebagai dilewati karena langkah-langkah tersebut diselesaikan pada tahap sebelumnya. Data itu di-cache atau dipertahankan untuk digunakan dalam tahap ini. |
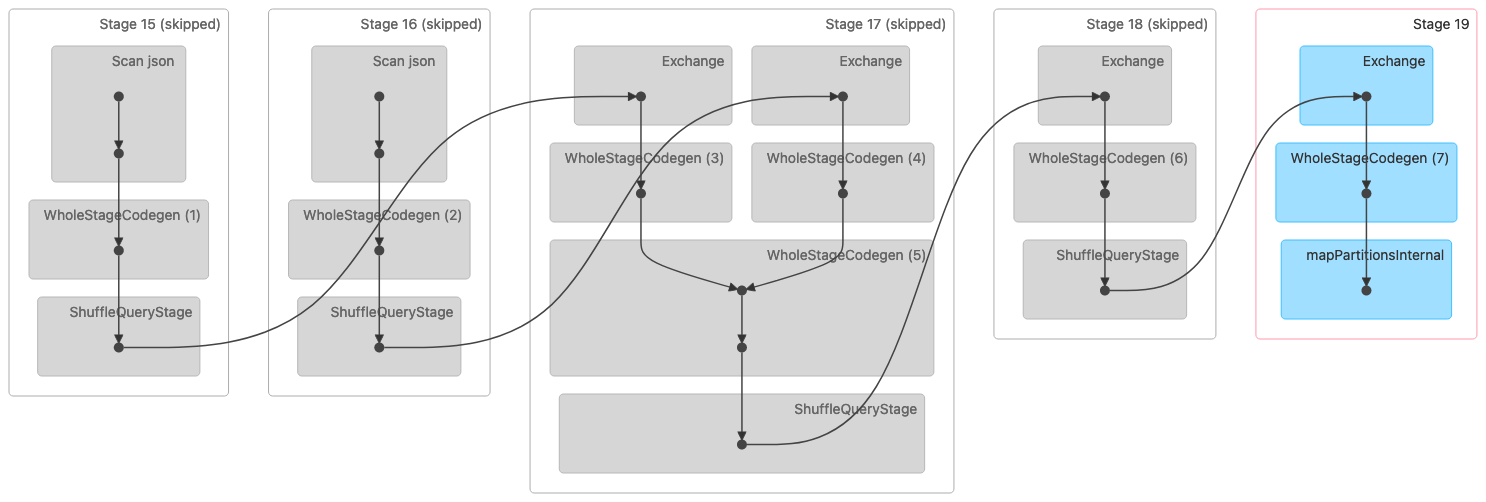
Berikut ini adalah rencana fisik yang menunjukkan gabungan Sort Merge.
== Physical Plan == AdaptiveSparkPlan isFinalPlan=false +- SortMergeJoin [id#320L], [id#335L], Inner :- Sort [id#320L ASC NULLS FIRST], false, 0 : +- Exchange hashpartitioning(id#320L, 36), ENSURE_REQUIREMENTS, [id=#1018] : +- Filter isnotnull(id#320L) : +- Scan ExistingRDD[id#320L,col#321] +- Sort [id#335L ASC NULLS FIRST], false, 0 +- Exchange hashpartitioning(id#335L, 36), ENSURE_REQUIREMENTS, [id=#1019] +- Filter isnotnull(id#335L) +- Scan ExistingRDD[id#335L,int_col#336L]
SHUFFLE_HASH
Shuffle Hash bergabung, seperti namanya, bekerja dengan mengacak kedua kumpulan data. Tombol yang sama dari kedua sisi berakhir di partisi atau tugas yang sama. Setelah data diacak, yang terkecil dari dua kumpulan data di-hash ke dalam ember, dan kemudian bergabung hash dilakukan di dalam partisi. Gabungan Shuffle Hash berbeda dari gabungan Broadcast Hash karena seluruh kumpulan data tidak disiarkan. Gabungan Shuffle Hash dibagi menjadi dua fase:
-
Fase acak - Kedua kumpulan data diacak.
-
Hash join phase - Sisi data yang lebih kecil di-hash, diselimuti, dan kemudian hash bergabung dengan sisi yang lebih besar di semua partisi.
Penyortiran tidak diperlukan dengan Shuffle Hash bergabung di dalam partisi. Gambar berikut menunjukkan fase gabungan Shuffle Hash. Data dibaca pada awalnya, kemudian diacak, dan kemudian hash dibuat dan digunakan untuk bergabung.
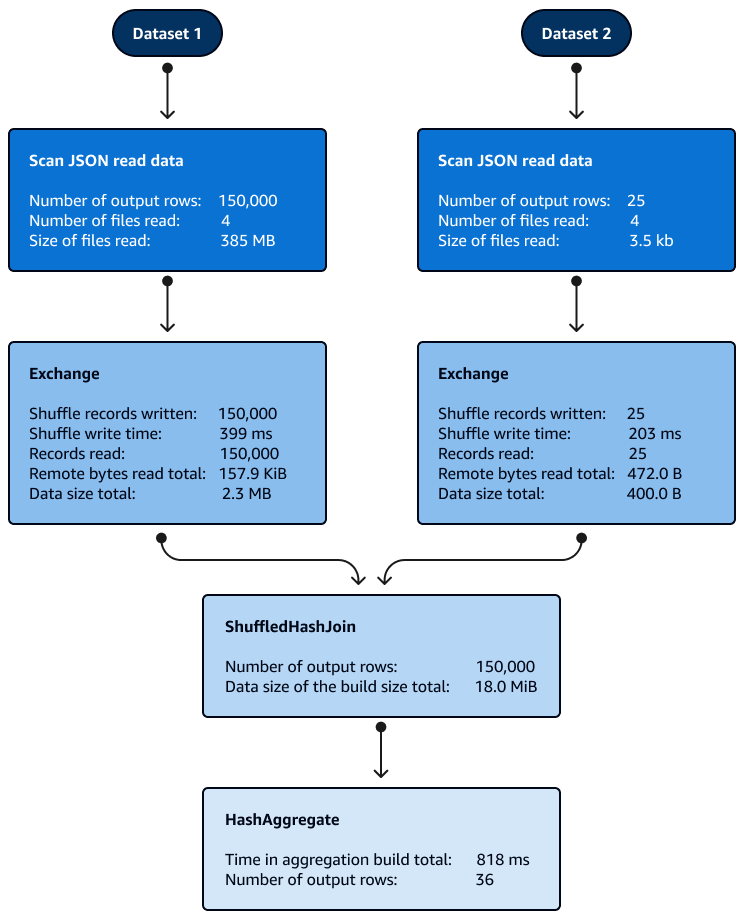
Secara default, pengoptimal memilih Shuffle Hash join ketika Broadcast Hash join tidak dapat digunakan. Berdasarkan Broadcast Hash join threshold size (spark.sql.autoBroadcastJoinThreshold) dan jumlah partisi shuffle (spark.sql.shuffle.partitions) yang dipilih, ia menggunakan Shuffle Hash join ketika partisi tunggal SQL logis cukup kecil untuk membangun tabel hash lokal.
SHUFFLE_REPLICATE_NL
Shuffle-and-Replicate Nested Loop join, juga dikenal sebagai Cartesian Product join, bekerja sangat mirip dengan Broadcast Hash join, kecuali dataset tidak disiarkan.
Dalam algoritma join ini, shuffle tidak mengacu pada shuffle sejati karena catatan dengan kunci yang sama tidak dikirim ke partisi yang sama. Sebaliknya, seluruh partisi dari kedua kumpulan data disalin melalui jaringan. Ketika partisi dari kumpulan data tersedia, gabungan Nested Loop dilakukan. Jika ada X jumlah catatan dalam kumpulan data pertama dan Y jumlah catatan di kumpulan data kedua di setiap partisi, setiap catatan dalam kumpulan data kedua digabungkan dengan setiap catatan di kumpulan data pertama. Ini berlanjut dalam satu X × Y kali loop di setiap partisi.
