Terjemahan disediakan oleh mesin penerjemah. Jika konten terjemahan yang diberikan bertentangan dengan versi bahasa Inggris aslinya, utamakan versi bahasa Inggris.
Praktik terbaik
Untuk memungkinkan pembelajaran mesin berikutnya (ML) atau pembelajaran penguatan (RL), sangat penting untuk mengikuti praktik terbaik di berbagai bidang, termasuk konsumsi data, manajemen aset, penyimpanan telemetri, dan visualisasi.
Penyerapan data memainkan peran penting dalam keberhasilan proyek. Ini melibatkan mengunggah data yang dihasilkan oleh aset edge ke AWS atau cloud pilihan Anda, memungkinkan interaksi skala cloud. Untuk merampingkan proses dan memfasilitasi skalabilitas, komponen sisi tepi untuk orientasi otomatis situs baru harus diimplementasikan. Ini memastikan bahwa aset baru dapat berintegrasi dengan mulus dengan infrastruktur yang ada saat online.
Manajemen aset adalah aspek penting lain yang perlu dipertimbangkan dengan cermat. Dengan memetakan metadata aset ke ontologi standar seperti ontologi Brick, Anda dapat memperoleh pandangan holistik tentang aset dan properti, hierarki, dan hubungannya. Diagram berikut menunjukkan contoh pemetaan yang diadaptasi dari dokumentasi ontologi Brick
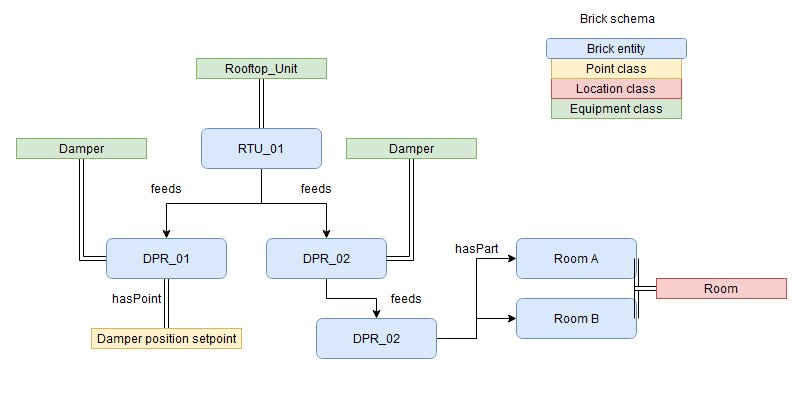
Menyimpan metadata ini dalam database grafik seperti Amazon Neptunus
Toko telemetri bertanggung jawab untuk menyimpan data yang dicerna secara real time dan menggunakan manajemen siklus hidup untuk mengurangi biaya dan meminimalkan risiko. Toko telemetri menggunakan mekanisme penyimpanan panas dan dingin untuk memungkinkan penyimpanan data yang efisien dan andal. Menerapkan katalog data seperti AWS Glue
Untuk memberikan wawasan dan memungkinkan pengambilan keputusan berdasarkan informasi, kami menyarankan Anda mengembangkan komponen visualisasi. Ini adalah dasbor yang memungkinkan pengguna untuk memvisualisasikan data aset yang diunggah, dan memberikan representasi yang jelas dan intuitif dari informasi yang dikumpulkan. Menyajikan data dengan cara yang ramah pengguna dapat membantu para pemangku kepentingan untuk dengan mudah memahami status proyek optimasi energi saat ini dan membuat keputusan berdasarkan data. Setelah Anda membangun fondasi data ini, Anda dapat menggunakan RL untuk mengaktifkan pengoptimalan energi. Untuk contoh implementasi, lihat GitHub repositori Amazon Neptunus AWS IoT SiteWise dan untuk aplikasi pembelajaran mesin industri
Kondisi eksternal memainkan peran penting dalam lingkungan RL. Anda harus mempertimbangkan variabel seperti tekanan atmosfer, aliran udara konstan, suhu pasokan, kelembaban relatif pasokan, suhu zona, kelembaban relatif zona, suhu udara luar, kelembaban relatif udara luar, setpoint pendinginan, dan persentase udara luar minimum. Kondisi ini membentuk representasi negara dan memberikan konteks yang diperlukan bagi agen RL untuk membuat keputusan.
Solusi RL harus membuat asumsi tertentu, seperti aliran udara konstan dan suhu udara pasokan konstan atau kelembaban relatif, untuk menyederhanakan masalah. Asumsi ini membantu membatasi lingkungan untuk agen RL, dan memungkinkan agen untuk mempelajari dan mengoptimalkan tindakannya lebih cepat.
Tindakan agen RL ditentukan oleh economizer yang memungkinkan setpoint. Setpoint ini, seperti suhu pengaktifan maksimum economizer dan entalpi pengaktifan maksimum economizer, menentukan perilaku sistem dan potensi penghematan dayanya. Agen RL belajar memilih setpoint yang sesuai berdasarkan status yang diamati untuk memaksimalkan hadiah hemat daya.
Fungsi hadiah adalah aspek penting dari RL. Dalam hal ini, hadiah dihitung berdasarkan logika hemat daya sambil menjaga kenyamanan manusia. Agen RL bertujuan untuk meminimalkan konsumsi daya, dan hadiah ditentukan dengan membandingkan konsumsi daya dengan dan tanpa economizer yang dipilih memungkinkan setpoint. Dengan memberi insentif pengurangan daya, agen RL belajar untuk mengoptimalkan tindakannya dari waktu ke waktu.
Diagram berikut menunjukkan contoh loop RL optimasi energi. Untuk informasi selengkapnya tentang alur kerja dan kode contoh ini, lihat Panduan GitHub repositori untuk Memantau dan Mengoptimalkan
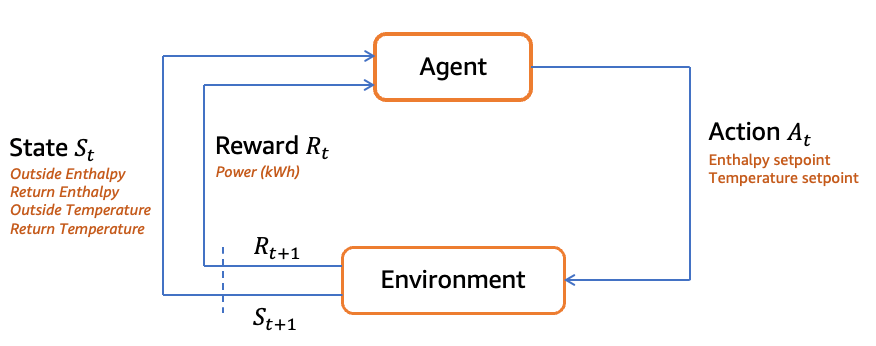
Mengembangkan solusi RL dengan mengikuti praktik terbaik melibatkan keseimbangan antara eksplorasi dan eksploitasi. Teknik seperti eksplorasi Epsilon-Greedy atau pengambilan sampel Thompson membantu agen menggunakan jumlah iterasi yang sesuai saat pelatihan.
Pemilihan algoritma RL yang cermat, seperti Q-learning atau Deep Q Network (DQN), bersama dengan tuning hyperparameter, memastikan pembelajaran dan konvergensi yang optimal. Menggunakan teknik seperti replay pengalaman dapat meningkatkan efisiensi sampel yang tersedia dan berguna ketika ada pengalaman dunia nyata yang terbatas untuk agen. Jaringan target meningkatkan stabilitas pelatihan dengan meminta agen mencoba beberapa contoh sebelum mempertimbangkan kembali pendekatannya. Secara keseluruhan, praktik ini memfasilitasi pengembangan solusi RL yang efektif untuk memaksimalkan penghargaan dan mengoptimalkan kinerja.
Singkatnya, mengembangkan solusi RL untuk simulator hemat daya memerlukan mempertimbangkan kondisi eksternal, mendefinisikan asumsi, memilih tindakan yang bermakna, dan merancang fungsi hadiah yang sesuai. Praktik terbaik mencakup pertukaran eksplorasi-eksploitasi yang tepat, pemilihan algoritme, penyetelan hiperparameter, dan menggunakan teknik peningkatan stabilitas seperti replay pengalaman dan jaringan target. Teknologi cloud memberikan efisiensi biaya, daya tahan, dan skalabilitas untuk analitik dan pembelajaran mesin. Mengikuti praktik terbaik dalam penyerapan data, manajemen aset, penyimpanan telemetri, visualisasi, dan pengembangan pembelajaran mesin memungkinkan integrasi yang mulus, penanganan data yang efisien, dan wawasan berharga, yang mengarah pada pengiriman proyek yang sukses.
