Terjemahan disediakan oleh mesin penerjemah. Jika konten terjemahan yang diberikan bertentangan dengan versi bahasa Inggris aslinya, utamakan versi bahasa Inggris.
Arsitektur untuk sistem perayapan web yang dapat diskalakan AWS
Diagram arsitektur berikut menunjukkan sistem perayap web yang dirancang untuk mengekstrak data lingkungan, sosial, dan tata kelola (ESG) secara etis dari situs web. Anda menggunakan Pythoncrawler berbasis yang dioptimalkan untuk AWS infrastruktur. Anda gunakan AWS Batch untuk mengatur pekerjaan crawling skala besar dan menggunakan Amazon Simple Storage Service (Amazon S3) untuk penyimpanan. Aplikasi hilir dapat menelan dan menyimpan data dari bucket Amazon S3.
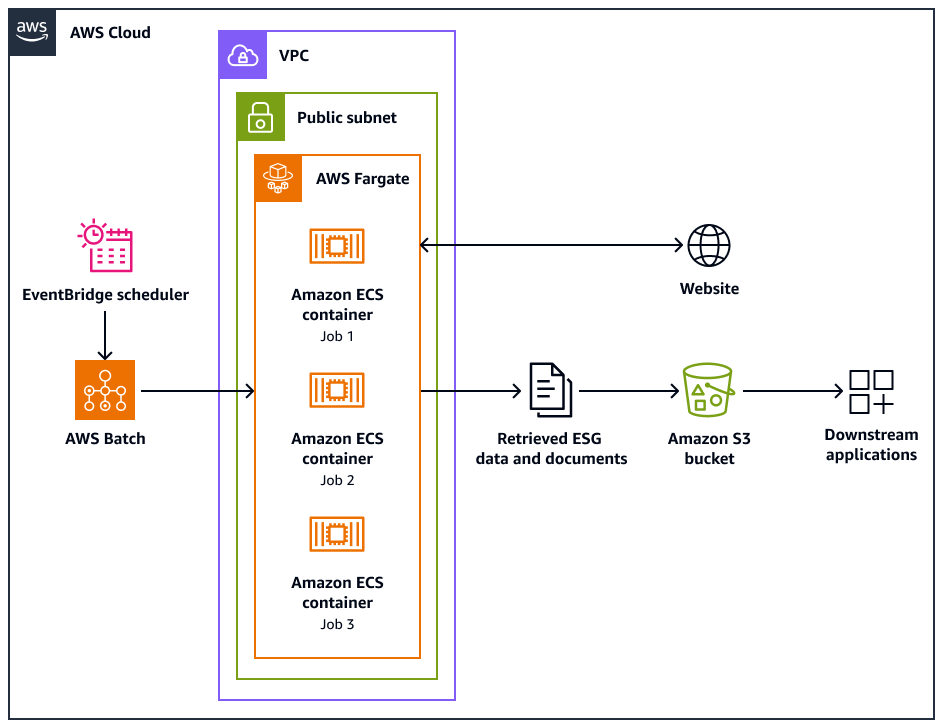
Diagram menunjukkan alur kerja berikut:
-
Amazon EventBridge Scheduler memulai proses crawling pada interval yang Anda jadwalkan.
-
AWS Batch mengelola eksekusi pekerjaan crawler web. Antrian AWS Batch pekerjaan menahan dan mengatur pekerjaan crawling yang tertunda.
-
Pekerjaan perayapan web berjalan di wadah Amazon Elastic Container Service (Amazon ECS) aktif. AWS Fargate Pekerjaan berjalan di subnet publik dari virtual private cloud (VPC).
-
Perayap web merayapi situs web target dan mengambil data dan dokumen ESG, seperti PDF, CSV, atau file dokumen lainnya.
-
Perayap web menyimpan data yang diambil dan file mentah dalam bucket Amazon S3.
-
Sistem atau aplikasi lain menyerap atau memproses data dan file yang disimpan di bucket Amazon S3.
Desain dan operasi perayap web
Beberapa situs web dirancang khusus untuk dijalankan di desktop atau di perangkat seluler. Web crawler dirancang untuk mendukung penggunaan agen pengguna desktop atau agen pengguna seluler. Agen ini membantu Anda berhasil membuat permintaan ke situs web target.
Setelah perayap web diinisialisasi, ia melakukan operasi berikut:
-
Web crawler memanggil
setup()metode. Metode ini mengambil dan mem-parsing file robots.txt.catatan
Anda juga dapat mengonfigurasi crawler web untuk mengambil dan mengurai peta situs.
-
Web crawler memproses file robots.txt. Jika penundaan crawl ditentukan dalam file robots.txt, crawler web mengekstrak penundaan crawl untuk agen pengguna desktop. Jika penundaan crawl tidak ditentukan dalam file robots.txt, maka perayap web menggunakan penundaan acak.
-
Web crawler memanggil
crawl()metode, yang memulai proses crawling. Jika tidak URLs ada dalam antrian, itu menambahkan URL awal.catatan
Crawler berlanjut hingga mencapai jumlah halaman maksimum atau kehabisan URLs crawl.
-
Crawler memproses. URLs Untuk setiap URL dalam antrian, crawler memeriksa apakah URL telah dirayapi.
-
Jika URL belum di-crawl, crawler memanggil
crawl_url()metode sebagai berikut:-
Crawler memeriksa file robots.txt untuk menentukan apakah ia dapat menggunakan agen pengguna desktop untuk merayapi URL.
-
Jika diizinkan, crawler mencoba merayapi URL dengan menggunakan agen pengguna desktop.
-
Jika tidak diizinkan atau jika agen pengguna desktop gagal merayapi, crawler akan memeriksa file robots.txt untuk menentukan apakah ia dapat menggunakan agen pengguna seluler untuk merayapi URL.
-
Jika diizinkan, crawler mencoba merayapi URL dengan menggunakan agen pengguna seluler.
-
-
Crawler memanggil
attempt_crawl()metode, yang mengambil dan memproses konten. Crawler mengirimkan permintaan GET ke URL dengan header yang sesuai. Jika permintaan gagal, crawler menggunakan logika coba lagi. -
Jika file dalam format HTML, crawler memanggil
extract_esg_data()metode tersebut. Ini menggunakan Beautiful Soupuntuk mengurai konten HTML. Ini mengekstrak data lingkungan, sosial, dan tata kelola (ESG) dengan menggunakan pencocokan kata kunci. Jika file tersebut adalah PDF, crawler memanggil
save_pdf()metode tersebut. Crawler mengunduh dan menyimpan file PDF ke bucket Amazon S3. -
Crawler memanggil
extract_news_links()metode. Ini menemukan dan menyimpan tautan ke artikel berita, siaran pers, dan posting blog. -
Crawler memanggil
extract_pdf_links()metode. Ini mengidentifikasi dan menyimpan tautan ke dokumen PDF. -
Crawler memanggil
is_relevant_to_sustainable_finance()metode. Ini memeriksa apakah berita atau artikel terkait dengan keuangan berkelanjutan dengan menggunakan kata kunci yang telah ditentukan. -
Setelah setiap upaya perayapan, crawler mengimplementasikan penundaan dengan menggunakan metode ini.
delay()Jika penundaan ditentukan dalam file robots.txt, ia menggunakan nilai itu. Jika tidak, ia menggunakan penundaan acak antara 1 dan 3 detik. -
Crawler memanggil
save_esg_data()metode untuk menyimpan data ESG ke file CSV. File CSV disimpan di bucket Amazon S3. -
Crawler memanggil
save_news_links()metode untuk menyimpan tautan berita ke file CSV, termasuk informasi relevansi. File CSV disimpan di bucket Amazon S3. -
Crawler memanggil
save_pdf_links()metode untuk menyimpan tautan PDF ke file CSV. File CSV disimpan di bucket Amazon S3.
Batching dan pengolahan data
Proses crawling diatur dan dilakukan secara terstruktur. AWS Batch memberikan pekerjaan untuk setiap perusahaan sehingga mereka berjalan secara paralel, dalam batch. Setiap batch berfokus pada domain dan subdomain perusahaan tunggal, karena Anda telah mengidentifikasinya dalam kumpulan data Anda. Namun, pekerjaan dalam batch yang sama berjalan secara berurutan sehingga tidak membanjiri situs web dengan terlalu banyak permintaan. Ini membantu aplikasi untuk mengelola beban kerja crawling lebih efisien dan memastikan bahwa semua data yang relevan ditangkap untuk setiap perusahaan.
Dengan mengatur perayapan web ke dalam batch khusus perusahaan, ini berisi data yang dikumpulkan. Ini membantu mencegah data dari satu perusahaan dicampur dengan data dari perusahaan lain.
Batching membantu aplikasi secara efisien mengumpulkan data dari web, sambil mempertahankan struktur yang jelas dan pemisahan informasi berdasarkan perusahaan target dan domain web masing-masing. Pendekatan ini membantu memastikan integritas dan kegunaan data yang dikumpulkan, karena terorganisir dengan rapi dan terkait dengan perusahaan dan domain yang sesuai.
