Amazon Redshift tidak akan lagi mendukung pembuatan Python UDFs baru mulai 1 November 2025. Jika Anda ingin menggunakan Python UDFs, buat UDFs sebelum tanggal tersebut. Python yang ada UDFs akan terus berfungsi seperti biasa. Untuk informasi lebih lanjut, lihat posting blog
Terjemahan disediakan oleh mesin penerjemah. Jika konten terjemahan yang diberikan bertentangan dengan versi bahasa Inggris aslinya, utamakan versi bahasa Inggris.
Penyimpanan kolumnar
Bagian ini menjelaskan penyimpanan kolumnar, yang merupakan metode yang digunakan Amazon Redshift untuk menyimpan data tabular secara efisien.
Penyimpanan kolumnar untuk tabel database merupakan faktor penting dalam mengoptimalkan kinerja kueri analitik, karena secara drastis mengurangi persyaratan I/O disk secara keseluruhan. Ini mengurangi jumlah data yang Anda butuhkan untuk memuat dari disk.
Rangkaian ilustrasi berikut menjelaskan bagaimana penyimpanan data kolumnar mengimplementasikan efisiensi, dan bagaimana hal itu diterjemahkan ke dalam efisiensi saat mengambil data ke dalam memori.
Ilustrasi pertama ini menunjukkan bagaimana catatan dari tabel database biasanya disimpan ke dalam blok disk demi baris.

Dalam tabel database relasional yang khas, setiap baris berisi nilai bidang untuk satu catatan. Dalam penyimpanan basis data baris, blok data menyimpan nilai secara berurutan untuk setiap kolom berturut-turut yang membentuk seluruh baris. Jika ukuran blok lebih kecil dari ukuran rekaman, penyimpanan untuk seluruh catatan mungkin memakan waktu lebih dari satu blok. Jika ukuran blok lebih besar dari ukuran rekaman, penyimpanan untuk seluruh catatan mungkin memakan waktu kurang dari satu blok, sehingga penggunaan ruang disk tidak efisien. Dalam aplikasi pemrosesan transaksi online (OLTP), sebagian besar transaksi melibatkan sering membaca dan menulis semua nilai untuk seluruh catatan, biasanya satu catatan atau sejumlah kecil catatan pada suatu waktu. Akibatnya, penyimpanan baris optimal untuk database OLTP.
Ilustrasi berikutnya menunjukkan bagaimana dengan penyimpanan kolumnar, nilai untuk setiap kolom disimpan secara berurutan ke dalam blok disk.
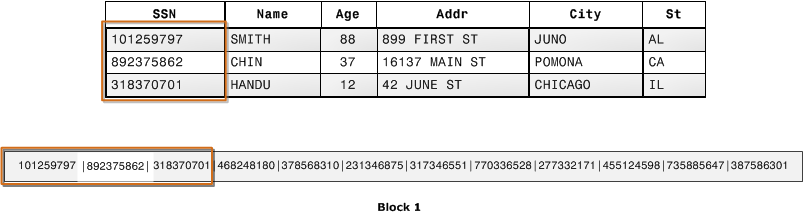
Menggunakan penyimpanan kolumnar, setiap blok data menyimpan nilai kolom tunggal untuk beberapa baris. Saat catatan memasuki sistem, Amazon Redshift secara transparan mengubah data menjadi penyimpanan kolumnar untuk setiap kolom.
Dalam contoh yang disederhanakan ini, menggunakan penyimpanan kolumnar, setiap blok data menyimpan nilai kolom kolom sebanyak tiga kali lebih banyak catatan sebagai penyimpanan berbasis baris. Ini berarti bahwa membaca jumlah nilai bidang kolom yang sama untuk jumlah catatan yang sama memerlukan sepertiga dari operasi I/O dibandingkan dengan penyimpanan baris. Dalam praktiknya, menggunakan tabel dengan jumlah kolom yang sangat besar dan jumlah baris yang sangat besar, efisiensi penyimpanan bahkan lebih besar.
Keuntungan tambahan adalah bahwa, karena setiap blok memiliki jenis data yang sama, data blok dapat menggunakan skema kompresi yang dipilih khusus untuk tipe data kolom, selanjutnya mengurangi ruang disk dan I/O. Untuk informasi lebih lanjut tentang pengkodean kompresi berdasarkan tipe data, lihat. Pengkodean kompresi
Penghematan ruang untuk menyimpan data pada disk juga dibawa ke pengambilan dan kemudian menyimpan data itu dalam memori. Karena banyak operasi database hanya perlu mengakses atau beroperasi pada satu atau sejumlah kecil kolom pada satu waktu, Anda dapat menghemat ruang memori dengan hanya mengambil blok untuk kolom yang sebenarnya Anda butuhkan untuk kueri. Di mana transaksi OLTP biasanya melibatkan sebagian besar atau semua kolom berturut-turut untuk sejumlah kecil catatan, kueri gudang data biasanya hanya membaca beberapa kolom untuk jumlah baris yang sangat besar. Ini berarti bahwa membaca jumlah nilai bidang kolom yang sama untuk jumlah baris yang sama memerlukan sebagian kecil dari operasi I/O. Ini menggunakan sebagian kecil dari memori yang akan diperlukan untuk memproses blok baris demi baris. Dalam praktiknya, menggunakan tabel dengan jumlah kolom yang sangat besar dan jumlah baris yang sangat besar, keuntungan efisiensi secara proporsional lebih besar. Misalnya, sebuah tabel berisi 100 kolom. Kueri yang menggunakan lima kolom hanya perlu membaca sekitar lima persen dari data yang terkandung dalam tabel. Penghematan ini diulang untuk mungkin miliaran atau bahkan triliunan catatan untuk database besar. Sebaliknya, database baris akan membaca blok yang berisi 95 kolom yang tidak dibutuhkan juga.
Ukuran blok database tipikal berkisar dari 2 KB hingga 32 KB. Amazon Redshift menggunakan ukuran blok 1 MB, yang lebih efisien dan selanjutnya mengurangi jumlah permintaan I/O yang diperlukan untuk melakukan pemuatan basis data atau operasi lain yang merupakan bagian dari proses kueri.
