Amazon Redshift tidak akan lagi mendukung pembuatan Python UDFs baru mulai 1 November 2025. Jika Anda ingin menggunakan Python UDFs, buat UDFs sebelum tanggal tersebut. Python yang ada UDFs akan terus berfungsi seperti biasa. Untuk informasi lebih lanjut, lihat posting blog
Terjemahan disediakan oleh mesin penerjemah. Jika konten terjemahan yang diberikan bertentangan dengan versi bahasa Inggris aslinya, utamakan versi bahasa Inggris.
Melihat data kinerja cluster
Dengan menggunakan metrik klaster di Amazon Redshift, Anda dapat melakukan tugas kinerja umum berikut:
-
Tentukan apakah metrik klaster tidak normal pada rentang waktu tertentu dan, jika demikian, identifikasi kueri yang bertanggung jawab atas hit kinerja.
-
Periksa apakah kueri historis atau saat ini memengaruhi kinerja klaster. Jika Anda mengidentifikasi kueri bermasalah, Anda dapat melihat detailnya termasuk kinerja klaster selama eksekusi kueri. Anda dapat menggunakan informasi ini dalam mendiagnosis mengapa kueri lambat dan apa yang dapat dilakukan untuk meningkatkan kinerjanya.
Untuk melihat data kinerja
-
Masuk ke AWS Management Console dan buka konsol Amazon Redshift di. https://console.aws.amazon.com/redshiftv2/
-
Pada menu navigasi, pilih Cluster, lalu pilih nama cluster dari daftar untuk membuka detailnya. Rincian cluster ditampilkan, yang dapat mencakup kinerja Cluster, pemantauan Kueri, Database, Datashares, Jadwal, Pemeliharaan, dan tab Properti.
-
Pilih tab Kinerja klaster untuk informasi kinerja termasuk yang berikut ini:
-
Pemanfaatan CPU
-
Persentase ruang disk yang digunakan
-
Koneksi database
-
Status kondisi
-
Durasi kueri
-
Throughput kueri
-
Aktivitas penskalaan konkurensi
Banyak lagi metrik yang tersedia. Untuk melihat metrik yang tersedia dan memilih yang ditampilkan, pilih ikon Preferensi.
-
Grafik kinerja cluster
Contoh berikut menunjukkan beberapa grafik yang ditampilkan di konsol Amazon Redshift baru.
-
Pemanfaatan CPU — Menunjukkan persentase pemanfaatan CPU untuk semua node (pemimpin dan komputasi). Untuk menemukan waktu ketika penggunaan klaster terendah sebelum menjadwalkan migrasi cluster atau operasi yang memakan sumber daya lainnya, pantau bagan ini untuk melihat pemanfaatan CPU per individu atau semua node.

-
Mode pemeliharaan - Menunjukkan apakah cluster berada dalam mode pemeliharaan pada waktu yang dipilih dengan menggunakan
OndanOffindikator. Anda dapat melihat waktu ketika cluster sedang menjalani pemeliharaan. Anda kemudian dapat mengkorelasikan waktu ini dengan operasi yang dilakukan ke cluster untuk memperkirakan waktu henti di masa depan untuk peristiwa berulang.
-
Persentase ruang disk yang digunakan - Menunjukkan persentase penggunaan ruang disk per setiap node komputasi, dan bukan untuk cluster secara keseluruhan. Anda dapat menjelajahi bagan ini untuk memantau pemanfaatan disk. Operasi pemeliharaan seperti VACUUM dan COPY menggunakan ruang penyimpanan sementara menengah untuk operasi penyortiran mereka, sehingga lonjakan penggunaan disk diharapkan.

-
Baca throughput — Menunjukkan jumlah rata-rata megabyte yang dibaca dari disk per detik. Anda dapat mengevaluasi bagan ini untuk memantau aspek fisik cluster yang sesuai. Throughput ini tidak termasuk lalu lintas jaringan antara instance di cluster dan volumenya.

-
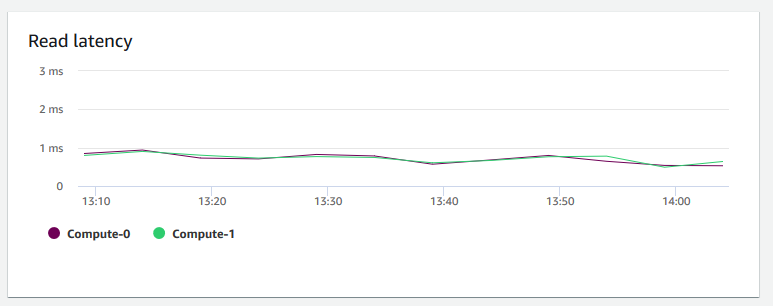
Baca latensi - Menunjukkan jumlah rata-rata waktu yang dibutuhkan untuk I/O operasi pembacaan disk per milidetik. Anda dapat melihat waktu respons untuk mengembalikan data. Ketika latensi tinggi, itu berarti bahwa pengirim menghabiskan lebih banyak waktu idle (tidak mengirim paket baru), yang mengurangi seberapa cepat throughput tumbuh.
-
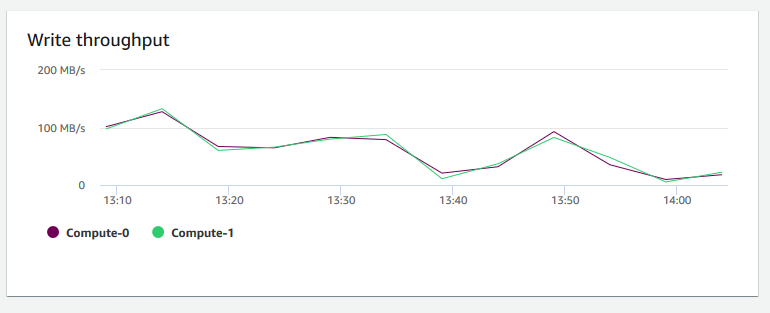
Tulis throughput — Menunjukkan jumlah rata-rata megabyte yang ditulis ke disk per detik. Anda dapat mengevaluasi metrik ini untuk memantau aspek fisik cluster yang sesuai. Throughput ini tidak termasuk lalu lintas jaringan antara instance di cluster dan volumenya.
-
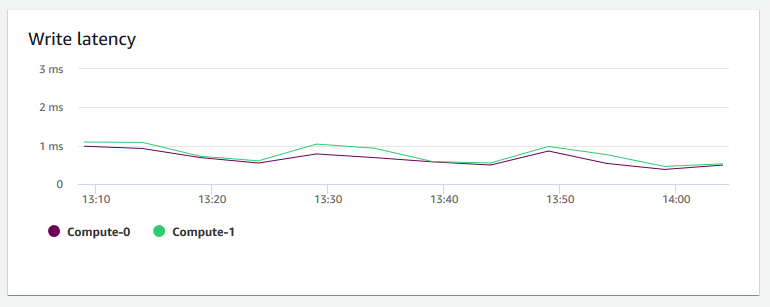
Latensi tulis - Menunjukkan jumlah waktu rata-rata dalam milidetik yang diambil untuk operasi penulisan I/O disk. Anda dapat mengevaluasi waktu untuk pengakuan tulis untuk kembali. Ketika latensi tinggi, itu berarti bahwa pengirim menghabiskan lebih banyak waktu idle (tidak mengirim paket baru), yang mengurangi seberapa cepat throughput tumbuh.
-
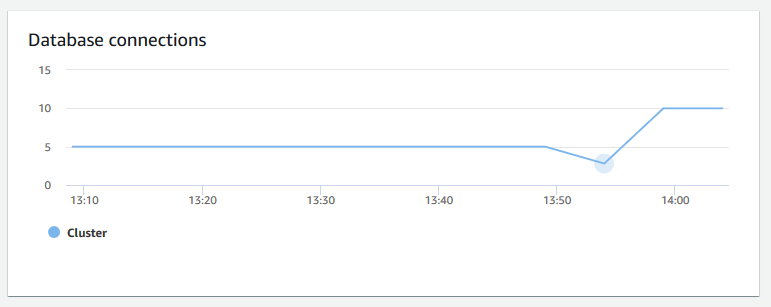
Koneksi database - Menunjukkan jumlah koneksi database ke sebuah cluster. Anda dapat menggunakan bagan ini untuk melihat berapa banyak koneksi yang dibuat ke database dan menemukan waktu ketika penggunaan cluster terendah.
-
Jumlah tabel total - Menunjukkan jumlah tabel pengguna yang terbuka pada titik waktu tertentu dalam sebuah cluster. Anda dapat memantau kinerja cluster saat jumlah tabel terbuka tinggi.
-
Status Kesehatan — Menunjukkan kesehatan cluster sebagai
HealthyatauUnhealthy. Jika cluster dapat terhubung ke database dan melakukan query sederhana berhasil, cluster dianggap sehat. Kalau tidak, cluster tidak sehat. Status yang tidak sehat dapat terjadi ketika database cluster berada di bawah beban yang sangat berat atau jika ada masalah konfigurasi dengan database di cluster.
-
Durasi kueri - Menunjukkan jumlah waktu rata-rata untuk menyelesaikan kueri dalam mikrodetik. Anda dapat membandingkan data pada bagan ini untuk mengukur I/O kinerja dalam cluster dan menyetel kueri yang paling memakan waktu jika perlu.

-
Throughput kueri - Menunjukkan jumlah rata-rata kueri yang diselesaikan per detik. Anda dapat menganalisis data pada bagan ini untuk mengukur kinerja database dan mengkarakterisasi kemampuan sistem untuk mendukung beban kerja multipengguna secara seimbang.
-
Durasi kueri per antrian WLM - Menunjukkan jumlah waktu rata-rata untuk menyelesaikan kueri dalam mikrodetik. Anda dapat membandingkan data pada bagan ini untuk mengukur I/O kinerja per antrian WLM dan menyetel kueri yang paling memakan waktu jika perlu.

-
Throughput kueri per antrian WLM - Menunjukkan jumlah rata-rata kueri yang diselesaikan per detik. Anda dapat menganalisis data pada bagan ini untuk mengukur kinerja database per antrian WLM.

-
Aktivitas penskalaan konkurensi — Menunjukkan jumlah cluster penskalaan konkurensi aktif. Saat penskalaan konkurensi diaktifkan, Amazon Redshift secara otomatis menambahkan kapasitas klaster tambahan saat Anda membutuhkannya untuk memproses peningkatan kueri baca bersamaan.

