Terjemahan disediakan oleh mesin penerjemah. Jika konten terjemahan yang diberikan bertentangan dengan versi bahasa Inggris aslinya, utamakan versi bahasa Inggris.
Laporan eksplorasi data autopilot
Amazon SageMaker Autopilot membersihkan dan memproses kumpulan data Anda secara otomatis. Data berkualitas tinggi meningkatkan efisiensi pembelajaran mesin dan menghasilkan model yang membuat prediksi yang lebih akurat.
Ada masalah dengan kumpulan data yang disediakan pelanggan yang tidak dapat diperbaiki secara otomatis tanpa manfaat dari beberapa pengetahuan domain. Nilai outlier besar di kolom target untuk masalah regresi, misalnya, dapat menyebabkan prediksi suboptimal untuk nilai non-outlier. Outlier mungkin perlu dihapus tergantung pada tujuan pemodelan. Jika kolom target dimasukkan secara tidak sengaja sebagai salah satu fitur input, model akhir akan memvalidasi dengan baik, tetapi memiliki nilai kecil untuk prediksi masa depan.
Untuk membantu pelanggan menemukan masalah semacam ini, Autopilot menyediakan laporan eksplorasi data yang berisi wawasan tentang potensi masalah dengan data mereka. Laporan ini juga menyarankan bagaimana menangani masalah.
Buku catatan eksplorasi data yang berisi laporan dibuat untuk setiap pekerjaan Autopilot. Laporan disimpan dalam bucket Amazon S3 dan dapat diakses dari jalur keluaran Anda. Jalur laporan eksplorasi data biasanya mengikuti pola berikut.
[s3 output path]/[name of the automl job]/sagemaker-automl-candidates/[name of processing job used for data analysis]/notebooks/SageMaker AIAutopilotDataExplorationNotebook.ipynb
Lokasi notebook eksplorasi data dapat diperoleh dari Autopilot API menggunakan respons DescribeAutoMLJoboperasi, yang disimpan di. DataExplorationNotebookLocation
Saat menjalankan Autopilot dari SageMaker Studio Classic, Anda dapat membuka laporan eksplorasi data menggunakan langkah-langkah berikut:
-
Pilih ikon Beranda
 dari panel navigasi kiri untuk melihat menu navigasi Amazon SageMaker Studio Classic tingkat atas.
dari panel navigasi kiri untuk melihat menu navigasi Amazon SageMaker Studio Classic tingkat atas. -
Pilih kartu AutoML dari area kerja utama. Ini membuka tab Autopilot baru.
-
Di bagian Nama, pilih pekerjaan Autopilot yang memiliki buku catatan eksplorasi data yang ingin Anda periksa. Ini membuka tab pekerjaan Autopilot baru.
-
Pilih Buka buku catatan eksplorasi data dari bagian kanan atas tab pekerjaan Autopilot.
Laporan eksplorasi data dihasilkan dari data Anda sebelum proses pelatihan dimulai. Ini memungkinkan Anda untuk menghentikan pekerjaan Autopilot yang mungkin mengarah pada hasil yang tidak berarti. Demikian juga, Anda dapat mengatasi masalah atau peningkatan apa pun dengan kumpulan data Anda sebelum menjalankan ulang Autopilot. Dengan cara ini, Anda dapat menggunakan keahlian domain Anda untuk meningkatkan kualitas data secara manual, sebelum Anda melatih model pada kumpulan data yang dikuratori dengan lebih baik.
Laporan data hanya berisi penurunan harga statis dan dapat dibuka di lingkungan Jupyter apa pun. Notebook yang berisi laporan dapat dikonversi ke format lain, seperti PDF atau HTML. Untuk informasi selengkapnya tentang konversi, lihat Menggunakan skrip nbconvert untuk mengonversi buku catatan Jupyter ke format lain
Topik
Ringkasan Dataset
Ringkasan Set Data ini menyediakan statistik utama yang mengkarakterisasi kumpulan data Anda termasuk jumlah baris, kolom, persen baris duplikat, dan nilai target yang hilang. Ini dimaksudkan untuk memberi Anda peringatan cepat ketika ada masalah dengan kumpulan data Anda yang terdeteksi Amazon SageMaker Autopilot dan yang kemungkinan memerlukan intervensi Anda. Wawasan muncul sebagai peringatan yang diklasifikasikan sebagai tingkat keparahan “tinggi” atau “rendah”. Klasifikasi tergantung pada tingkat kepercayaan bahwa masalah tersebut akan berdampak buruk pada kinerja model.
Wawasan tingkat keparahan tinggi dan rendah muncul dalam ringkasan sebagai pop-up. Untuk sebagian besar wawasan, rekomendasi ditawarkan untuk cara mengonfirmasi bahwa ada masalah dengan kumpulan data yang memerlukan perhatian Anda. Proposal juga disediakan untuk cara menyelesaikan masalah.
Autopilot memberikan statistik tambahan tentang nilai target yang hilang atau tidak valid dalam kumpulan data kami untuk membantu Anda mendeteksi masalah lain yang mungkin tidak ditangkap oleh wawasan tingkat keparahan tinggi. Jumlah kolom yang tidak terduga dari jenis tertentu mungkin menunjukkan bahwa beberapa kolom yang ingin Anda gunakan mungkin hilang dari kumpulan data. Ini juga bisa menunjukkan bahwa ada masalah dengan bagaimana data disiapkan atau disimpan. Memperbaiki masalah data yang dibawa ke perhatian Anda oleh Autopilot dapat meningkatkan kinerja model pembelajaran mesin yang dilatih pada data Anda.
Wawasan tingkat keparahan tinggi ditampilkan di bagian ringkasan dan di bagian lain yang relevan dalam laporan. Contoh wawasan tingkat keparahan tinggi dan rendah biasanya diberikan tergantung pada bagian laporan data.
Analisis Target
Berbagai wawasan tingkat keparahan tinggi dan rendah ditampilkan di bagian ini terkait dengan distribusi nilai di kolom target. Periksa apakah kolom target berisi nilai yang benar. Nilai yang salah di kolom target kemungkinan akan menghasilkan model pembelajaran mesin yang tidak melayani tujuan bisnis yang dimaksudkan. Beberapa wawasan data tingkat keparahan tinggi dan rendah hadir di bagian ini. Berikut adalah beberapa contoh tanda.
-
Nilai target outlier - Distribusi target miring atau tidak biasa untuk regresi, seperti target berekor berat.
-
Kardinalitas target tinggi atau rendah - Jumlah label kelas yang jarang atau sejumlah besar kelas unik untuk klasifikasi.
Untuk jenis masalah regresi dan klasifikasi, nilai yang tidak valid seperti tak terhingga numerik, NaN atau ruang kosong di kolom target muncul. Tergantung pada jenis masalah, statistik dataset yang berbeda disajikan. Distribusi nilai kolom target untuk masalah regresi memungkinkan Anda memverifikasi apakah distribusi sesuai dengan yang Anda harapkan.
Tangkapan layar berikut menunjukkan laporan data Autopilot, yang mencakup statistik seperti rata-rata, median, minimum, maksimum, persentase outlier dalam kumpulan data Anda. Tangkapan layar juga menyertakan histogram yang menunjukkan distribusi label di kolom target. Histogram menunjukkan Nilai Kolom Target pada sumbu horizontal dan Hitung pada sumbu vertikal. Sebuah kotak menyoroti bagian Persentase Outliers pada tangkapan layar untuk menunjukkan di mana statistik ini muncul.
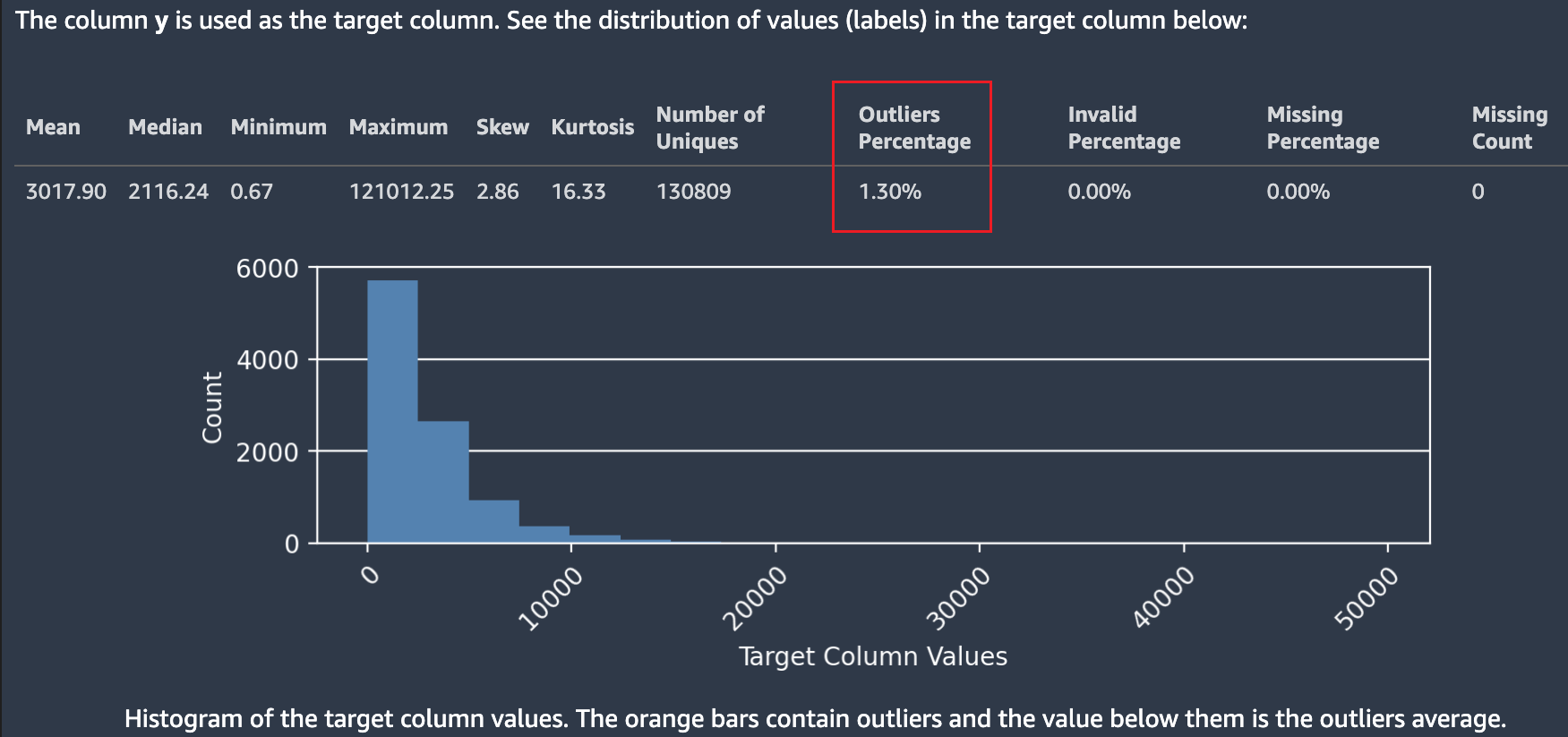
Beberapa statistik ditampilkan mengenai nilai target dan distribusinya. Jika salah satu outlier, bukan nilai yang valid, atau persentase yang hilang lebih besar dari nol, nilai ini muncul sehingga Anda dapat menyelidiki mengapa data Anda berisi nilai target yang tidak dapat digunakan. Beberapa nilai target yang tidak dapat digunakan disorot sebagai peringatan wawasan tingkat keparahan rendah.
Pada tangkapan layar berikut, simbol `ditambahkan secara tidak sengaja ke kolom target, yang mencegah nilai numerik target diurai. Wawasan tingkat keparahan rendah: Peringatan “Nilai target tidak valid” muncul. Peringatan dalam contoh ini menyatakan "0,14% label di kolom target tidak dapat dikonversi ke nilai numerik. Nilai non-numerik yang paling umum adalah: [” -3.8e-05",” -9-05",” -4.7e-05",” -1.4999999999999999e-05",” -4.3e-05"]. Itu biasanya menunjukkan bahwa ada masalah dengan pengumpulan atau pemrosesan data. Amazon SageMaker Autopilot mengabaikan semua pengamatan dengan label target yang tidak valid.

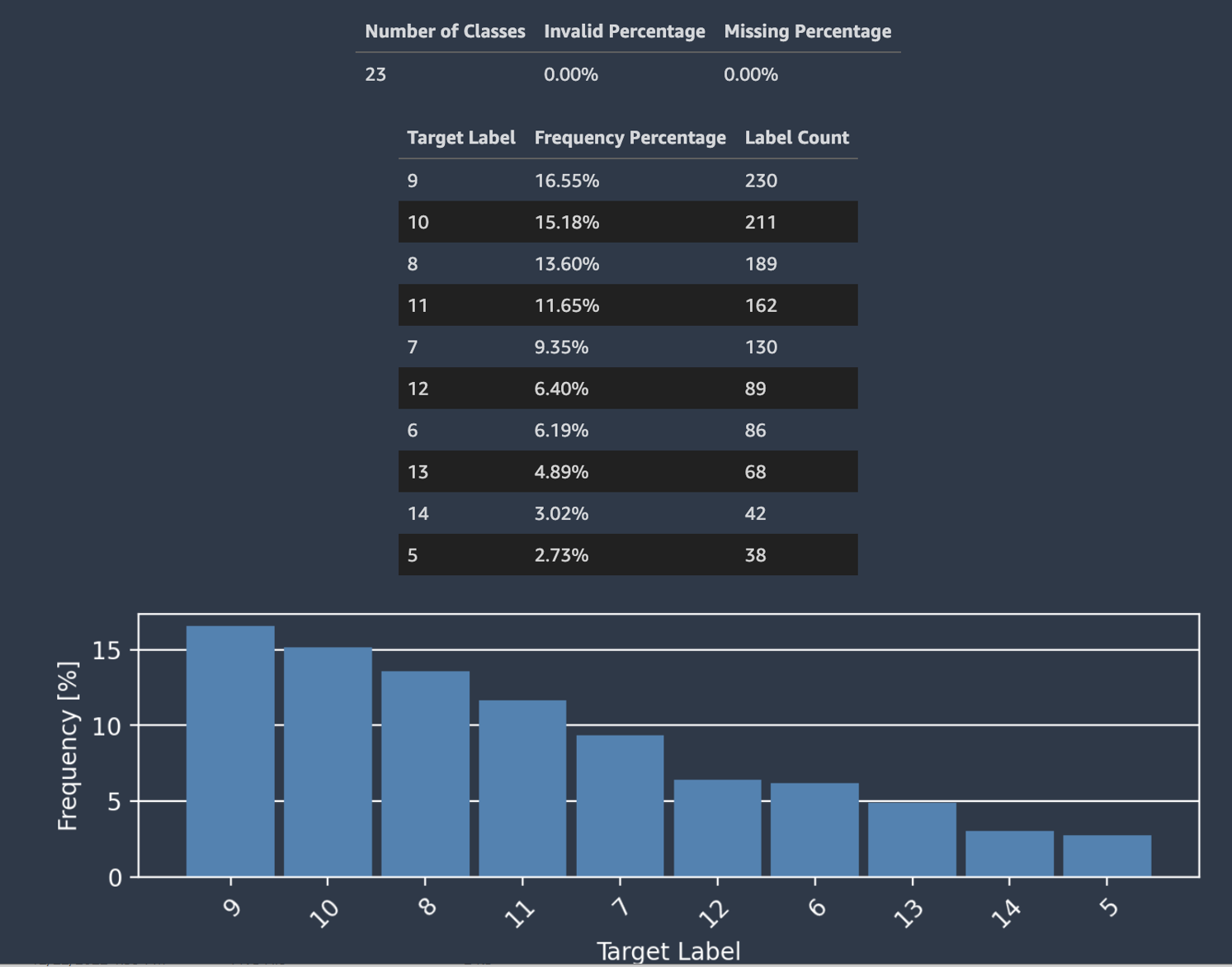
Autopilot juga menyediakan histogram yang menunjukkan distribusi label untuk klasifikasi.
Tangkapan layar berikut menunjukkan contoh statistik yang diberikan untuk kolom target Anda termasuk jumlah kelas, nilai yang hilang atau tidak valid. Histogram dengan Label Target pada sumbu horizontal dan Frekuensi pada sumbu vertikal menunjukkan distribusi setiap kategori label.
catatan
Anda dapat menemukan definisi dari semua istilah yang disajikan dalam bagian ini dan lainnya di bagian Definisi di bagian bawah buku catatan laporan.
Sampel Data
Autopilot menyajikan sampel aktual data Anda untuk membantu Anda menemukan masalah dengan kumpulan data Anda. Tabel sampel bergulir secara horizontal. Periksa data sampel untuk memverifikasi bahwa semua kolom yang diperlukan ada dalam kumpulan data.
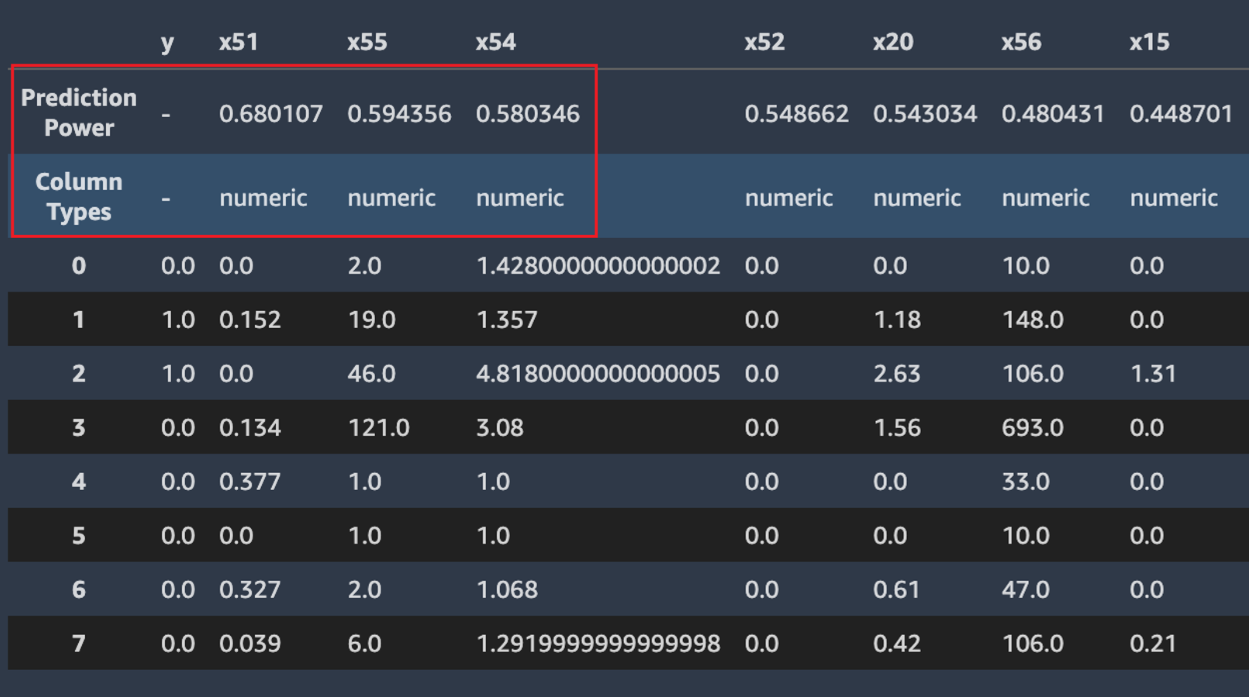
Autopilot juga menghitung ukuran daya prediksi, yang dapat digunakan untuk mengidentifikasi hubungan linier atau nonlinier antara fitur dan variabel target. Nilai 0 menunjukkan bahwa fitur tersebut tidak memiliki nilai prediktif dalam memprediksi variabel target. Nilai 1 menunjukkan daya prediksi tertinggi untuk variabel target. Untuk informasi lebih lanjut tentang kekuatan prediktif, lihat bagian Definisi.
catatan
Tidak disarankan Anda menggunakan kekuatan prediksi sebagai pengganti kepentingan fitur. Gunakan hanya jika Anda yakin bahwa kekuatan prediksi adalah ukuran yang tepat untuk kasus penggunaan Anda.
Tangkapan layar berikut menunjukkan contoh sampel data. Baris atas berisi kekuatan prediksi setiap kolom dalam kumpulan data Anda. Baris kedua berisi tipe data kolom. Baris berikutnya berisi label. Kolom berisi kolom target diikuti oleh setiap kolom fitur. Setiap kolom fitur memiliki kekuatan prediksi terkait, disorot dalam tangkapan layar ini, dengan sebuah kotak. Dalam contoh ini, kolom yang berisi fitur x51 memiliki kekuatan prediksi 0.68 untuk variabel y target. Fitur x55 ini sedikit kurang prediktif dengan kekuatan prediksi. 0.59
Baris duplikat
Jika baris duplikat ada dalam kumpulan data, Amazon SageMaker Autopilot menampilkan sampelnya.
catatan
Tidak disarankan untuk menyeimbangkan kumpulan data dengan up-sampling sebelum memberikannya ke Autopilot. Hal ini dapat mengakibatkan skor validasi yang tidak akurat untuk model yang dilatih oleh Autopilot, dan model yang diproduksi mungkin tidak dapat digunakan.
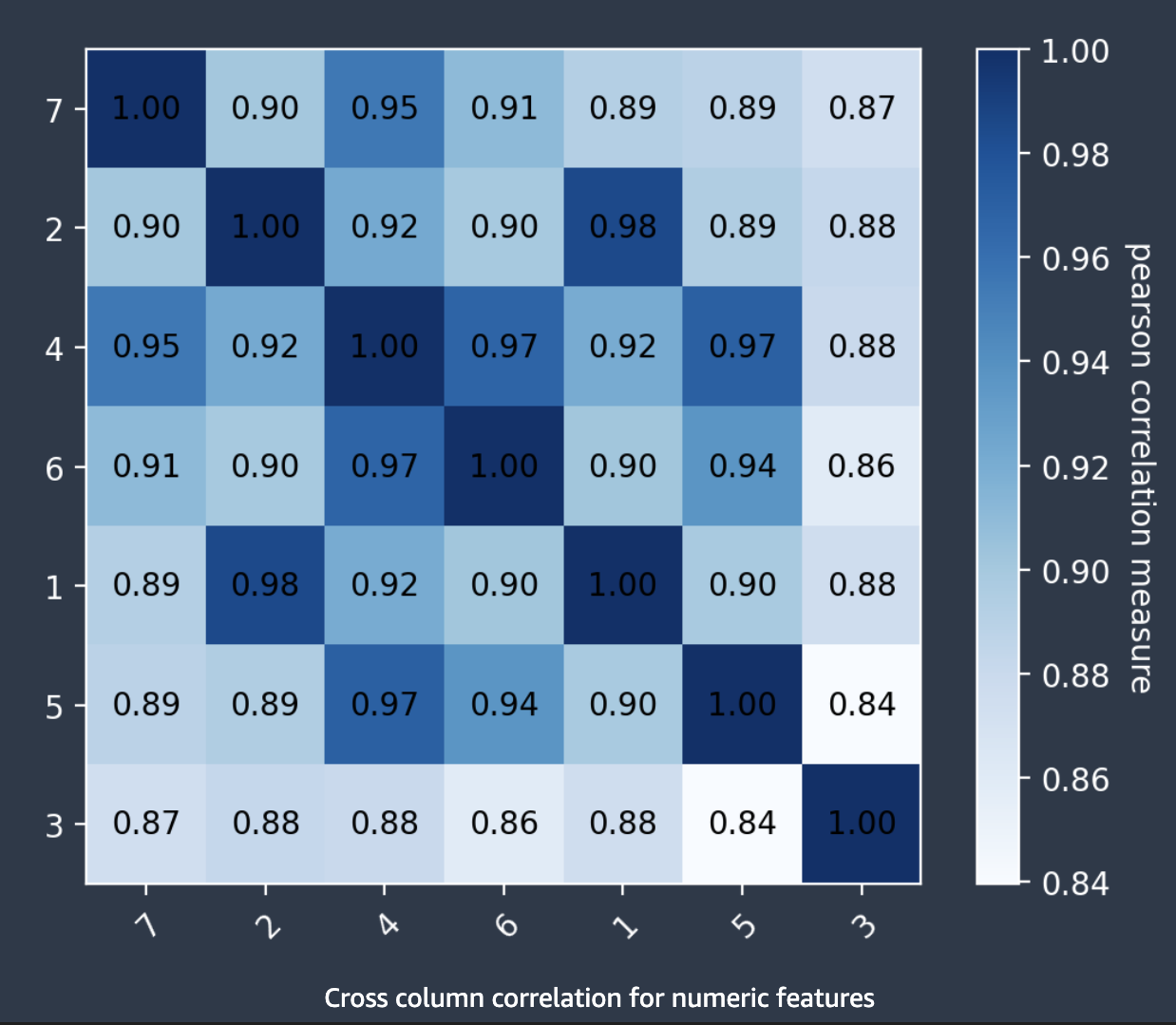
Korelasi kolom silang
Autopilot menggunakan koefisien korelasi Pearson, ukuran korelasi linier antara dua fitur, untuk mengisi matriks korelasi. Dalam matriks korelasi, fitur numerik diplot pada sumbu horizontal dan vertikal, dengan koefisien korelasi Pearson diplot di persimpangan mereka. Semakin tinggi korelasi antara dua fitur, semakin tinggi koefisiennya, dengan nilai maksimum. |1|
-
Nilai
-1menunjukkan bahwa fitur berkorelasi negatif sempurna. -
Nilai
1, yang terjadi ketika suatu fitur berkorelasi dengan dirinya sendiri, menunjukkan korelasi positif yang sempurna.
Anda dapat menggunakan informasi dalam matriks korelasi untuk menghapus fitur yang sangat berkorelasi. Sejumlah kecil fitur mengurangi kemungkinan overfitting model dan dapat mengurangi biaya produksi dengan dua cara. Ini mengurangi runtime Autopilot yang dibutuhkan dan, untuk beberapa aplikasi, dapat membuat prosedur pengumpulan data lebih murah.
Tangkapan layar berikut menunjukkan contoh matriks korelasi antar 7 fitur. Setiap fitur ditampilkan dalam matriks pada sumbu horizontal dan vertikal. Koefisien korelasi Pearson ditampilkan di persimpangan antara dua fitur. Setiap persimpangan fitur memiliki nada warna yang terkait dengannya. Semakin tinggi korelasinya, semakin gelap nadanya. Nada paling gelap menempati diagonal matriks, di mana setiap fitur berkorelasi dengan dirinya sendiri, mewakili korelasi sempurna.
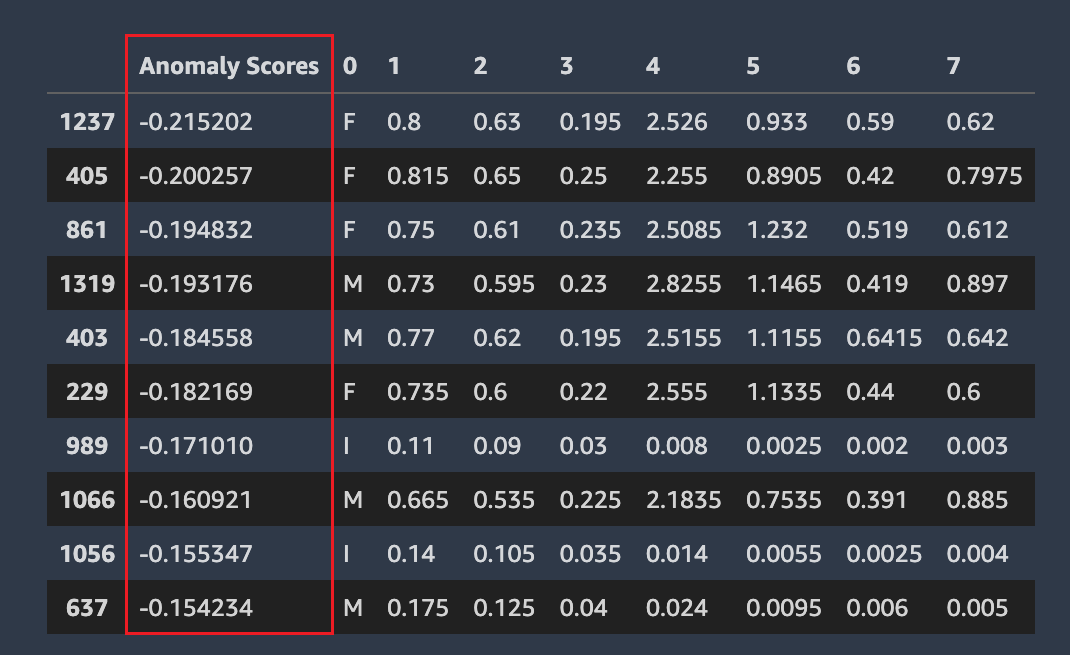
Baris Anomali
Amazon SageMaker Autopilot mendeteksi baris mana dalam kumpulan data Anda yang mungkin anomali. Kemudian memberikan skor anomali untuk setiap baris. Baris dengan skor anomali negatif dianggap anomali.
Tangkapan layar berikut menunjukkan output dari analisis Autopilot untuk baris yang berisi anomali. Kolom yang berisi skor anomali muncul di sebelah kolom dataset untuk setiap baris.
Nilai yang hilang, kardinalitas, dan statistik deskriptif
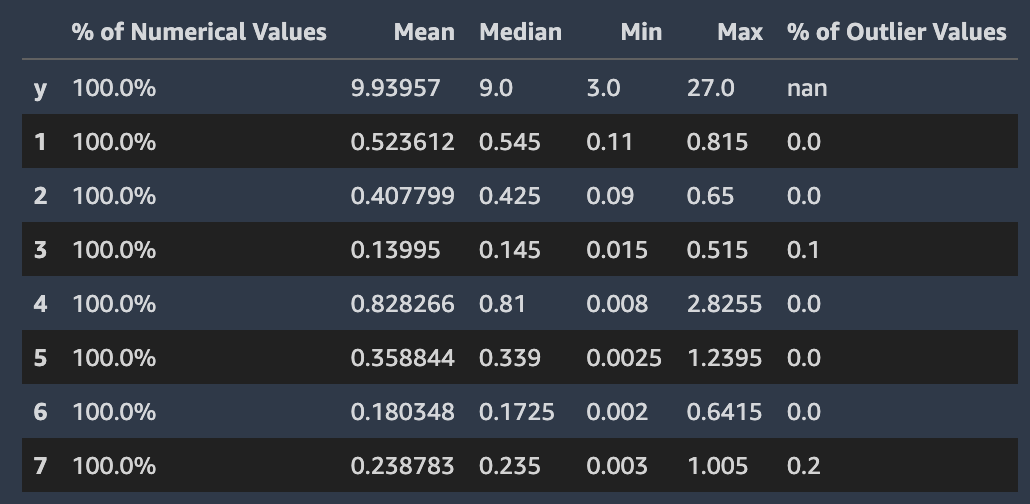
Amazon SageMaker Autopilot memeriksa dan melaporkan properti masing-masing kolom kumpulan data Anda. Di setiap bagian laporan data yang menyajikan analisis ini, konten disusun secara berurutan. Ini agar Anda dapat memeriksa nilai yang paling “mencurigakan” terlebih dahulu. Dengan menggunakan statistik ini Anda dapat meningkatkan konten kolom individual, dan meningkatkan kualitas model yang dihasilkan oleh Autopilot.
Autopilot menghitung beberapa statistik pada nilai kategoris dalam kolom yang berisi mereka. Ini termasuk jumlah entri unik dan, untuk teks, jumlah kata unik.
Autopilot menghitung beberapa statistik standar pada nilai numerik dalam kolom yang berisi mereka. Gambar berikut menggambarkan statistik ini, termasuk nilai rata-rata, median, minimum dan maksimum, dan persentase jenis numerik dan nilai outlier.