Terjemahan disediakan oleh mesin penerjemah. Jika konten terjemahan yang diberikan bertentangan dengan versi bahasa Inggris aslinya, utamakan versi bahasa Inggris.
Membuat Endpoint Multi-Model
Anda dapat menggunakan konsol SageMaker AI atau AWS SDK for Python (Boto) untuk membuat titik akhir multi-model. Untuk membuat titik akhir yang didukung CPU atau GPU melalui konsol, lihat prosedur konsol di bagian berikut. Jika Anda ingin membuat endpoint multi-model dengan AWS SDK for Python (Boto), gunakan prosedur CPU atau GPU di bagian berikut. Alur kerja CPU dan GPU serupa tetapi memiliki beberapa perbedaan, seperti persyaratan wadah.
Topik
Buat titik akhir multi-model (konsol)
Anda dapat membuat titik akhir multi-model yang didukung CPU dan GPU melalui konsol. Gunakan prosedur berikut untuk membuat titik akhir multi-model melalui konsol SageMaker AI.
Untuk membuat titik akhir multi-model (konsol)
-
Buka konsol Amazon SageMaker AI di https://console.aws.amazon.com/sagemaker/
. -
Pilih Model, dan kemudian dari grup Inferensi, pilih Buat model.
-
Untuk nama Model, masukkan nama.
-
Untuk peran IAM, pilih atau buat peran IAM yang memiliki kebijakan
AmazonSageMakerFullAccessIAM terlampir. -
Di bagian Definisi kontainer, untuk Menyediakan artefak model dan opsi gambar inferensi, pilih Gunakan beberapa model.
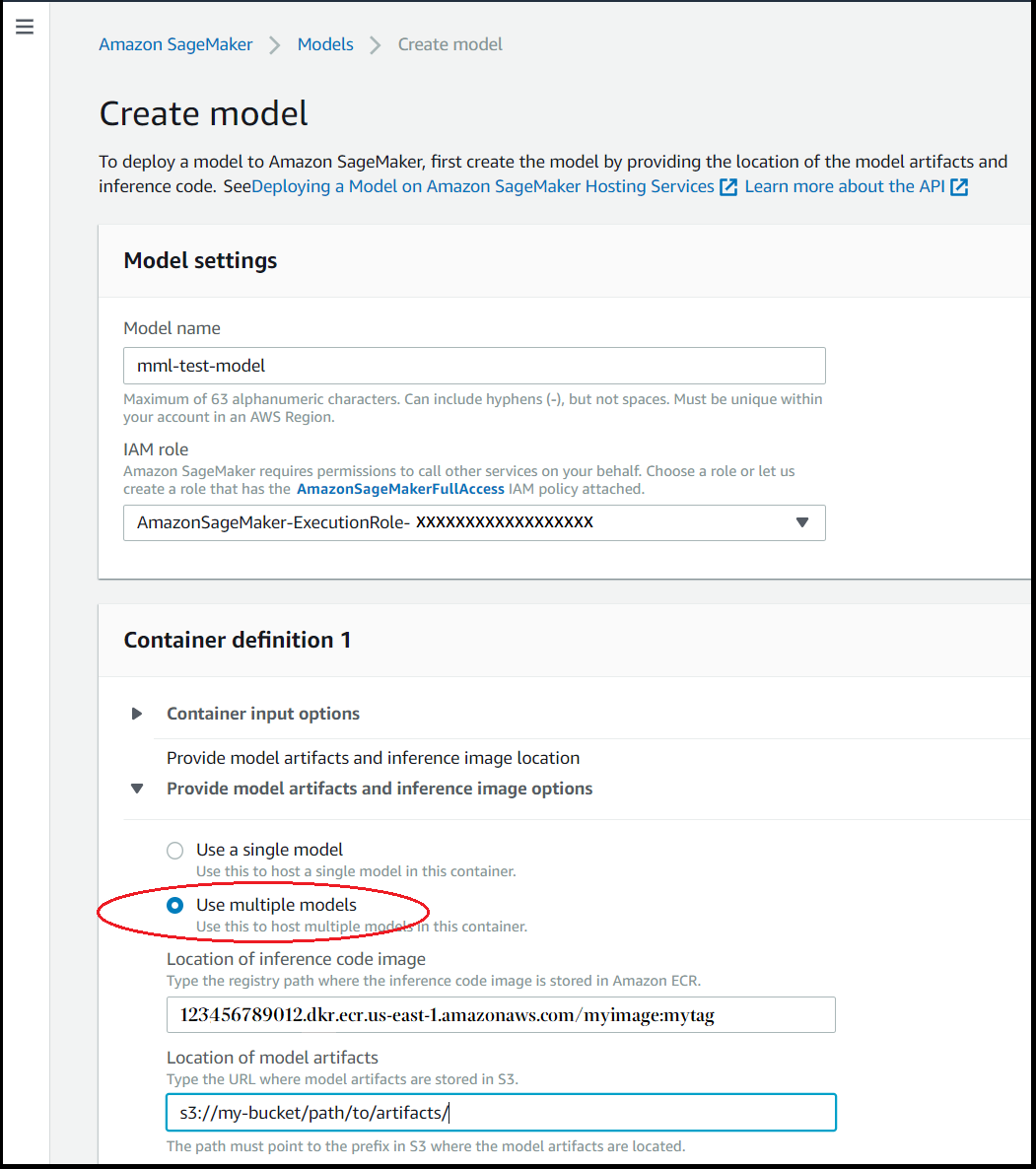
-
Untuk gambar kontainer Inferensi, masukkan jalur Amazon ECR untuk gambar kontainer yang Anda inginkan.
Untuk model GPU, Anda harus menggunakan wadah yang didukung oleh NVIDIA Triton Inference Server. Untuk daftar gambar kontainer yang berfungsi dengan titik akhir yang didukung GPU, lihat NVIDIA Triton Inference Containers (
khusus dukungan SM). Untuk informasi selengkapnya tentang Server Inferensi Triton NVIDIA, lihat Menggunakan Server Inferensi Triton dengan AI. SageMaker -
Pilih Buat model.
-
Terapkan titik akhir multi-model Anda seperti yang Anda lakukan pada titik akhir model tunggal. Untuk petunjuk, silakan lihat Menyebarkan Model ke Layanan Hosting SageMaker AI.
Buat titik akhir multi-model menggunakan dengan CPUs AWS SDK untuk Python (Boto3)
Gunakan bagian berikut untuk membuat titik akhir multi-model yang didukung oleh instance CPU. Anda membuat titik akhir multi-model menggunakan Amazon SageMaker AI create_modelcreate_endpoint_configcreate_endpointMode parameter baru,MultiModel. Anda juga harus melewati ModelDataUrl bidang yang menentukan awalan di Amazon S3 tempat artefak model berada, alih-alih jalur ke artefak model tunggal, seperti yang Anda lakukan saat menerapkan satu model.
Untuk contoh notebook yang menggunakan SageMaker AI untuk menerapkan beberapa XGBoost model ke titik akhir, lihat Notebook Contoh Titik Akhir Multi-Model
Prosedur berikut menguraikan langkah-langkah kunci yang digunakan dalam sampel tersebut untuk membuat titik akhir multi-model yang didukung CPU.
Untuk menyebarkan model (AWS SDK untuk Python (Boto 3))
-
Dapatkan wadah dengan gambar yang mendukung penerapan titik akhir multi-model. Untuk daftar algoritme bawaan dan wadah kerangka kerja yang mendukung titik akhir multi-model, lihat. Algoritma, kerangka kerja, dan instance yang didukung untuk titik akhir multi-model Untuk contoh ini, kami menggunakan algoritma Algoritma K-Nearest Neighbors (k-NN) bawaan. Kami memanggil fungsi utilitas SageMaker Python SDK
image_uris.retrieve()untuk mendapatkan alamat untuk image algoritma bawaan K-Nearest Neighbors.import sagemaker region = sagemaker_session.boto_region_name image = sagemaker.image_uris.retrieve("knn",region=region) container = { 'Image': image, 'ModelDataUrl': 's3://<BUCKET_NAME>/<PATH_TO_ARTIFACTS>', 'Mode': 'MultiModel' } -
Dapatkan klien AWS SDK untuk Python (Boto3) SageMaker AI dan buat model yang menggunakan wadah ini.
import boto3 sagemaker_client = boto3.client('sagemaker') response = sagemaker_client.create_model( ModelName ='<MODEL_NAME>', ExecutionRoleArn = role, Containers = [container]) -
(Opsional) Jika Anda menggunakan pipeline inferensi serial, dapatkan wadah tambahan untuk disertakan dalam pipeline, dan sertakan dalam
Containersargumen:CreateModelpreprocessor_container = { 'Image': '<ACCOUNT_ID>.dkr.ecr.<REGION_NAME>.amazonaws.com/<PREPROCESSOR_IMAGE>:<TAG>' } multi_model_container = { 'Image': '<ACCOUNT_ID>.dkr.ecr.<REGION_NAME>.amazonaws.com/<IMAGE>:<TAG>', 'ModelDataUrl': 's3://<BUCKET_NAME>/<PATH_TO_ARTIFACTS>', 'Mode': 'MultiModel' } response = sagemaker_client.create_model( ModelName ='<MODEL_NAME>', ExecutionRoleArn = role, Containers = [preprocessor_container, multi_model_container] )catatan
Anda hanya dapat menggunakan satu multi-model-enabled titik akhir dalam pipeline inferensi serial.
-
(Opsional) Jika kasus penggunaan Anda tidak mendapat manfaat dari caching model, tetapkan nilai
ModelCacheSettingbidangMultiModelConfigparameter keDisabled, dan sertakan dalamContainerargumen panggilan kecreate_model. NilaiModelCacheSettingbidang adalah secaraEnableddefault.container = { 'Image': image, 'ModelDataUrl': 's3://<BUCKET_NAME>/<PATH_TO_ARTIFACTS>', 'Mode': 'MultiModel' 'MultiModelConfig': { // Default value is 'Enabled' 'ModelCacheSetting': 'Disabled' } } response = sagemaker_client.create_model( ModelName ='<MODEL_NAME>', ExecutionRoleArn = role, Containers = [container] ) -
Konfigurasikan titik akhir multi-model untuk model. Kami menyarankan untuk mengonfigurasi titik akhir Anda dengan setidaknya dua instance. Hal ini memungkinkan SageMaker AI untuk menyediakan serangkaian prediksi yang sangat tersedia di beberapa Availability Zone untuk model.
response = sagemaker_client.create_endpoint_config( EndpointConfigName ='<ENDPOINT_CONFIG_NAME>', ProductionVariants=[ { 'InstanceType': 'ml.m4.xlarge', 'InitialInstanceCount': 2, 'InitialVariantWeight': 1, 'ModelName':'<MODEL_NAME>', 'VariantName': 'AllTraffic' } ] )catatan
Anda hanya dapat menggunakan satu multi-model-enabled titik akhir dalam pipeline inferensi serial.
-
Buat titik akhir multi-model menggunakan parameter
EndpointNamedanEndpointConfigName.response = sagemaker_client.create_endpoint( EndpointName ='<ENDPOINT_NAME>', EndpointConfigName ='<ENDPOINT_CONFIG_NAME>')
Buat titik akhir multi-model menggunakan dengan GPUs AWS SDK untuk Python (Boto3)
Gunakan bagian berikut untuk membuat titik akhir multi-model yang didukung GPU. Anda membuat titik akhir multi-model menggunakan Amazon SageMaker AI create_modelcreate_endpoint_configcreate_endpointMode parameter baru,MultiModel. Anda juga harus melewati ModelDataUrl bidang yang menentukan awalan di Amazon S3 tempat artefak model berada, alih-alih jalur ke artefak model tunggal, seperti yang Anda lakukan saat menerapkan satu model. Untuk titik akhir multi-model yang didukung GPU, Anda juga harus menggunakan wadah dengan NVIDIA Triton Inference Server yang dioptimalkan untuk berjalan pada instance GPU. Untuk daftar gambar kontainer yang berfungsi dengan titik akhir yang didukung GPU, lihat NVIDIA Triton Inference Containers (
Untuk contoh notebook yang mendemonstrasikan cara membuat titik akhir multi-model yang didukung oleh GPUs, lihat Menjalankan model pembelajaran mendalam mulitple dengan GPUs Amazon SageMaker AI Multi-model
Prosedur berikut menguraikan langkah-langkah kunci untuk membuat titik akhir multi-model yang didukung GPU.
Untuk menyebarkan model (AWS SDK untuk Python (Boto 3))
-
Tentukan gambar kontainer. Untuk membuat endpoint multi-model dengan dukungan GPU untuk ResNet model, tentukan wadah untuk menggunakan image NVIDIA Triton Server. Wadah ini mendukung titik akhir multi-model dan dioptimalkan untuk berjalan pada instance GPU. Kami memanggil fungsi utilitas SageMaker AI Python SDK
image_uris.retrieve()untuk mendapatkan alamat gambar. Sebagai contoh:import sagemaker region = sagemaker_session.boto_region_name // Find the sagemaker-tritonserver image at // https://github.com/aws/amazon-sagemaker-examples/blob/main/sagemaker-triton/resnet50/triton_resnet50.ipynb // Find available tags at https://github.com/aws/deep-learning-containers/blob/master/available_images.md#nvidia-triton-inference-containers-sm-support-only image = "<ACCOUNT_ID>.dkr.ecr.<REGION_NAME>.amazonaws.com/sagemaker-tritonserver:<TAG>".format( account_id=account_id_map[region], region=region ) container = { 'Image': image, 'ModelDataUrl': 's3://<BUCKET_NAME>/<PATH_TO_ARTIFACTS>', 'Mode': 'MultiModel', "Environment": {"SAGEMAKER_TRITON_DEFAULT_MODEL_NAME": "resnet"}, } -
Dapatkan klien AWS SDK untuk Python (Boto3) SageMaker AI dan buat model yang menggunakan wadah ini.
import boto3 sagemaker_client = boto3.client('sagemaker') response = sagemaker_client.create_model( ModelName ='<MODEL_NAME>', ExecutionRoleArn = role, Containers = [container]) -
(Opsional) Jika Anda menggunakan pipeline inferensi serial, dapatkan wadah tambahan untuk disertakan dalam pipeline, dan sertakan dalam
Containersargumen:CreateModelpreprocessor_container = { 'Image': '<ACCOUNT_ID>.dkr.ecr.<REGION_NAME>.amazonaws.com/<PREPROCESSOR_IMAGE>:<TAG>' } multi_model_container = { 'Image': '<ACCOUNT_ID>.dkr.ecr.<REGION_NAME>.amazonaws.com/<IMAGE>:<TAG>', 'ModelDataUrl': 's3://<BUCKET_NAME>/<PATH_TO_ARTIFACTS>', 'Mode': 'MultiModel' } response = sagemaker_client.create_model( ModelName ='<MODEL_NAME>', ExecutionRoleArn = role, Containers = [preprocessor_container, multi_model_container] )catatan
Anda hanya dapat menggunakan satu multi-model-enabled titik akhir dalam pipeline inferensi serial.
-
(Opsional) Jika kasus penggunaan Anda tidak mendapat manfaat dari caching model, tetapkan nilai
ModelCacheSettingbidangMultiModelConfigparameter keDisabled, dan sertakan dalamContainerargumen panggilan kecreate_model. NilaiModelCacheSettingbidang adalah secaraEnableddefault.container = { 'Image': image, 'ModelDataUrl': 's3://<BUCKET_NAME>/<PATH_TO_ARTIFACTS>', 'Mode': 'MultiModel' 'MultiModelConfig': { // Default value is 'Enabled' 'ModelCacheSetting': 'Disabled' } } response = sagemaker_client.create_model( ModelName ='<MODEL_NAME>', ExecutionRoleArn = role, Containers = [container] ) -
Konfigurasikan titik akhir multi-model dengan instans yang didukung GPU untuk model. Sebaiknya konfigurasi titik akhir Anda dengan lebih dari satu instance untuk memungkinkan ketersediaan tinggi dan klik cache yang lebih tinggi.
response = sagemaker_client.create_endpoint_config( EndpointConfigName ='<ENDPOINT_CONFIG_NAME>', ProductionVariants=[ { 'InstanceType': 'ml.g4dn.4xlarge', 'InitialInstanceCount': 2, 'InitialVariantWeight': 1, 'ModelName':'<MODEL_NAME>', 'VariantName': 'AllTraffic' } ] ) -
Buat titik akhir multi-model menggunakan parameter
EndpointNamedanEndpointConfigName.response = sagemaker_client.create_endpoint( EndpointName ='<ENDPOINT_NAME>', EndpointConfigName ='<ENDPOINT_CONFIG_NAME>')
