Terjemahan disediakan oleh mesin penerjemah. Jika konten terjemahan yang diberikan bertentangan dengan versi bahasa Inggris aslinya, utamakan versi bahasa Inggris.
Melatih Model
Pada langkah ini, Anda memilih algoritma pelatihan dan menjalankan pekerjaan pelatihan untuk model. Amazon SageMaker Python SDK
Pilih Algoritma Pelatihan
Untuk memilih algoritme yang tepat untuk kumpulan data Anda, Anda biasanya perlu mengevaluasi model yang berbeda untuk menemukan model yang paling sesuai dengan data Anda. Untuk kesederhanaan, algoritma XGBoost algoritma dengan Amazon SageMaker AI built-in SageMaker AI digunakan di seluruh tutorial ini tanpa pra-evaluasi model.
Tip
Jika Anda ingin SageMaker AI menemukan model yang sesuai untuk kumpulan data tabular Anda, gunakan Amazon SageMaker Autopilot yang mengotomatiskan solusi pembelajaran mesin. Untuk informasi selengkapnya, lihat SageMaker Autopilot.
Buat dan Jalankan Training Job
Setelah Anda mengetahui model mana yang akan digunakan, mulailah membuat estimator SageMaker AI untuk pelatihan. Tutorial ini menggunakan algoritma XGBoost bawaan untuk SageMaker estimator generik AI.
Untuk menjalankan pekerjaan pelatihan model
-
Impor Amazon SageMaker Python SDK
dan mulai dengan mengambil informasi dasar dari sesi AI Anda saat ini. SageMaker import sagemaker region = sagemaker.Session().boto_region_name print("AWS Region: {}".format(region)) role = sagemaker.get_execution_role() print("RoleArn: {}".format(role))Prosedur ini akan menampilkan informasi berikut.
-
region— AWS Wilayah saat ini tempat instance notebook SageMaker AI berjalan. -
role— Peran IAM yang digunakan oleh instance notebook.
catatan
Periksa versi SageMaker Python SDK dengan menjalankan.
sagemaker.__version__Tutorial ini didasarkan padasagemaker>=2.20. Jika SDK sudah usang, instal versi terbaru dengan menjalankan perintah berikut:! pip install -qU sagemakerJika Anda menjalankan instalasi ini di instance SageMaker Studio atau notebook yang keluar, Anda perlu menyegarkan kernel secara manual untuk menyelesaikan penerapan pembaruan versi.
-
-
Buat XGBoost estimator menggunakan
sagemaker.estimator.Estimatorkelas. Pada contoh berikut, nama penggunanya adalah .from sagemaker.debugger import Rule, ProfilerRule, rule_configs from sagemaker.session import TrainingInput s3_output_location='s3://{}/{}/{}'.format(bucket, prefix, 'xgboost_model') container=sagemaker.image_uris.retrieve("xgboost", region, "1.2-1") print(container) xgb_model=sagemaker.estimator.Estimator( image_uri=container, role=role, instance_count=1, instance_type='ml.m4.xlarge', volume_size=5, output_path=s3_output_location, sagemaker_session=sagemaker.Session(), rules=[ Rule.sagemaker(rule_configs.create_xgboost_report()), ProfilerRule.sagemaker(rule_configs.ProfilerReport()) ] )Untuk membangun estimator SageMaker AI, tentukan parameter berikut:
-
image_uri— Tentukan URI gambar wadah pelatihan. Dalam contoh ini, URI wadah XGBoost pelatihan SageMaker AI ditentukan menggunakansagemaker.image_uris.retrieve. -
role— Peran AWS Identity and Access Management (IAM) yang digunakan SageMaker AI untuk melakukan tugas atas nama Anda (misalnya, membaca hasil pelatihan, memanggil artefak model dari Amazon S3, dan menulis hasil pelatihan ke Amazon S3). -
instance_countdaninstance_type— Jenis dan jumlah instans komputasi Amazon EC2 ML yang akan digunakan untuk pelatihan model. Untuk latihan ini, Anda menggunakan satuml.m4.xlargeinstans, yang memiliki memori 4, 16 GB CPUs, penyimpanan Amazon Elastic Block Store (Amazon EBS) Elastic Block Store (Amazon EBS), dan kinerja jaringan yang tinggi. Untuk informasi selengkapnya tentang tipe instans yang didukung, lihat EC2 Tipe Instans Amazon EC2. Untuk informasi selengkapnya tentang penagihan, lihat SageMaker harga Amazon. -
Ukuran, dalam GB, volume penyimpanan ML yang akan dilampirkan ke instans notebook. Ini harus cukup besar untuk menyimpan data pelatihan jika Anda menggunakan
Filemode (Filemode aktif secara default). Jika Anda tidak menentukan parameter ini, maka nilai default adalah . -
output_path— Jalur ke ember S3 tempat SageMaker AI menyimpan artefak model dan hasil pelatihan. -
sagemaker_sessionObjek sesi yang mengelola interaksi dengan operasi SageMaker API dan AWS layanan lain yang digunakan oleh pekerjaan pelatihan. -
rules— Tentukan daftar aturan bawaan SageMaker Debugger. Dalam contoh ini,create_xgboost_report()aturan membuat XGBoost laporan yang memberikan wawasan tentang kemajuan dan hasil pelatihan, danProfilerReport()aturan membuat laporan mengenai pemanfaatan sumber daya EC2 komputasi. Untuk informasi selengkapnya, lihat SageMaker Laporan interaktif debugger untuk XGBoost.
Tip
Jika Anda ingin menjalankan pelatihan terdistribusi model pembelajaran mendalam berukuran besar, seperti model jaringan saraf konvolusional (CNN) dan pemrosesan bahasa alami (NLP), gunakan SageMaker AI Distributed untuk paralelisme data atau paralelisme model. Untuk informasi selengkapnya, lihat Pelatihan terdistribusi di Amazon SageMaker AI.
-
-
Atur hyperparameters untuk XGBoost algoritma dengan memanggil
set_hyperparametersmetode estimator. Untuk daftar lengkap XGBoost hyperparameters, lihatXGBoost hiperparameter.xgb_model.set_hyperparameters( max_depth = 5, eta = 0.2, gamma = 4, min_child_weight = 6, subsample = 0.7, objective = "binary:logistic", num_round = 1000 )Tip
Anda juga dapat menyetel hyperparameters menggunakan fitur pengoptimalan hyperparameter SageMaker AI. Untuk informasi selengkapnya, lihat Penyetelan model otomatis dengan AI SageMaker .
-
Gunakan
TrainingInputkelas untuk mengkonfigurasi aliran input data untuk pelatihan. Kode contoh berikut menunjukkan cara mengonfigurasiTrainingInputobjek untuk menggunakan kumpulan data pelatihan dan validasi yang Anda unggah ke Amazon S3 di bagian tersebut. Memisahkan data ke dalam pelatihan, validasi, dan set tes.from sagemaker.session import TrainingInput train_input = TrainingInput( "s3://{}/{}/{}".format(bucket, prefix, "data/train.csv"), content_type="csv" ) validation_input = TrainingInput( "s3://{}/{}/{}".format(bucket, prefix, "data/validation.csv"), content_type="csv" ) -
Untuk memulai pelatihan model, hubungi
fitmetode estimator dengan kumpulan data pelatihan dan validasi. Dengan pengaturanwait=True,fitmetode ini menampilkan log kemajuan dan menunggu hingga pelatihan selesai.xgb_model.fit({"train": train_input, "validation": validation_input}, wait=True)Untuk informasi selengkapnya tentang melatih model Anda, lihat Latih Model dengan Amazon SageMaker. Pekerjaan pelatihan tutorial ini mungkin memakan waktu hingga 10 menit.
Setelah pekerjaan pelatihan selesai, Anda dapat mengunduh laporan XGBoost pelatihan dan laporan pembuatan profil yang dihasilkan oleh SageMaker Debugger. Laporan XGBoost pelatihan menawarkan Anda wawasan tentang kemajuan dan hasil pelatihan, seperti fungsi kerugian sehubungan dengan iterasi, kepentingan fitur, matriks kebingungan, kurva akurasi, dan hasil statistik pelatihan lainnya. Misalnya, Anda dapat menemukan kurva kerugian berikut dari laporan XGBoost pelatihan yang dengan jelas menunjukkan bahwa ada masalah overfitting.
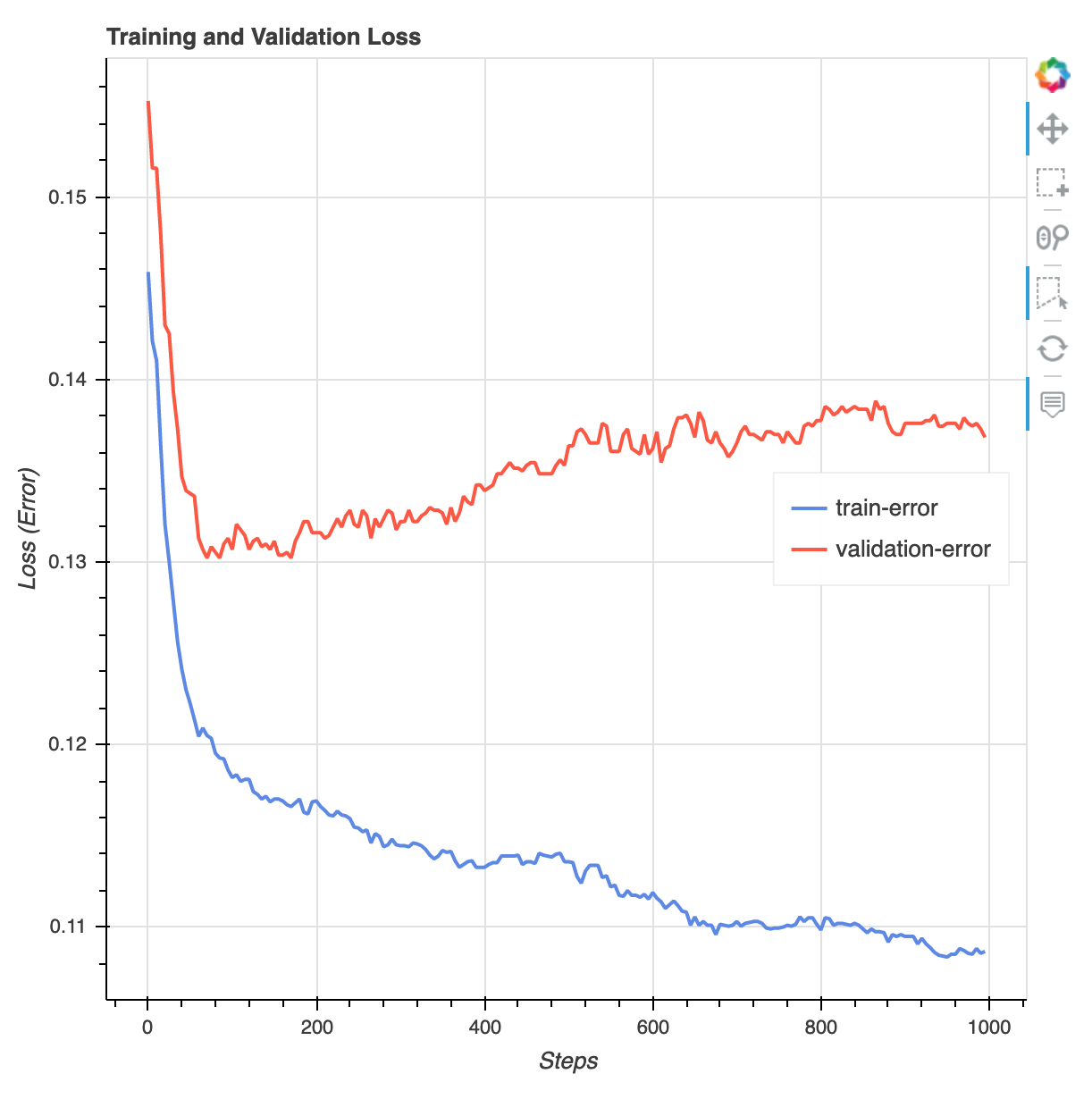
Jalankan kode berikut untuk menentukan URI bucket S3 tempat laporan pelatihan Debugger dibuat dan periksa apakah laporan tersebut ada.
rule_output_path = xgb_model.output_path + "/" + xgb_model.latest_training_job.job_name + "/rule-output" ! aws s3 ls {rule_output_path} --recursiveUnduh laporan XGBoost pelatihan dan pembuatan profil Debugger ke ruang kerja saat ini:
! aws s3 cp {rule_output_path} ./ --recursiveJalankan IPython skrip berikut untuk mendapatkan tautan file dari laporan XGBoost pelatihan:
from IPython.display import FileLink, FileLinks display("Click link below to view the XGBoost Training report", FileLink("CreateXgboostReport/xgboost_report.html"))IPython Skrip berikut mengembalikan tautan file dari laporan pembuatan profil Debugger yang menunjukkan ringkasan dan detail pemanfaatan sumber daya EC2 instance, hasil deteksi kemacetan sistem, dan hasil pembuatan profil operasi python:
profiler_report_name = [rule["RuleConfigurationName"] for rule in xgb_model.latest_training_job.rule_job_summary() if "Profiler" in rule["RuleConfigurationName"]][0] profiler_report_name display("Click link below to view the profiler report", FileLink(profiler_report_name+"/profiler-output/profiler-report.html"))Tip
Jika laporan HTML tidak membuat plot dalam JupyterLab tampilan, Anda harus memilih Trust HTML di bagian atas laporan.
Untuk mengidentifikasi masalah pelatihan, seperti overfitting, gradien menghilang, dan masalah lain yang mencegah model Anda dari konvergen, gunakan SageMaker Debugger dan lakukan tindakan otomatis saat membuat prototipe dan melatih model ML Anda. Untuk informasi selengkapnya, lihat Amazon SageMaker Debugger. Untuk menemukan analisis lengkap parameter model, lihat buku catatan contoh Explainability with Amazon SageMaker Debugger
.
Sekarang Anda memiliki XGBoost model yang terlatih. SageMaker AI menyimpan artefak model di bucket S3 Anda. Untuk menemukan lokasi artefak model, jalankan kode berikut untuk mencetak atribut model_data estimator: xgb_model
xgb_model.model_data
Tip
Untuk mengukur bias yang dapat terjadi selama setiap tahap siklus hidup ML (pengumpulan data, pelatihan dan penyetelan model, dan pemantauan model ML yang digunakan untuk prediksi), gunakan Clarify. SageMaker Untuk informasi selengkapnya, lihat Penjelasan Model. end-to-endSebagai contoh, lihat contoh Keadilan dan Keterjelasan dengan SageMaker Clarify
