Terjemahan disediakan oleh mesin penerjemah. Jika konten terjemahan yang diberikan bertentangan dengan versi bahasa Inggris aslinya, utamakan versi bahasa Inggris.
Hasil rekomendasi
Setiap hasil pekerjaan Inference Recommender mencakupInstanceType,, dan InitialInstanceCountEnvironmentParameters, yang merupakan parameter variabel lingkungan yang disetel untuk penampung Anda guna meningkatkan latensi dan throughputnya. Hasilnya juga mencakup metrik kinerja dan biaya sepertiMaxInvocations,,ModelLatency,CostPerHour, CostPerInferenceCpuUtilization, danMemoryUtilization.
Pada tabel di bawah ini kami memberikan deskripsi metrik ini. Metrik ini dapat membantu Anda mempersempit pencarian Anda untuk konfigurasi titik akhir terbaik yang sesuai dengan kasus penggunaan Anda. Misalnya, jika motivasi Anda adalah kinerja harga secara keseluruhan dengan penekanan pada throughput, maka Anda harus fokus padaCostPerInference.
| Metrik | Deskripsi | Kasus penggunaan |
|---|---|---|
|
|
Interval waktu yang dibutuhkan oleh model untuk merespons seperti yang dilihat dari SageMaker AI. Interval ini mencakup waktu komunikasi lokal yang diambil untuk mengirim permintaan dan untuk mengambil respons dari wadah model dan waktu yang dibutuhkan untuk menyelesaikan inferensi dalam wadah. Unit: Milidetik |
Beban kerja sensitif latensi seperti penayangan iklan dan diagnosis medis |
|
|
Jumlah maksimum Satuan: Tidak ada |
Beban kerja yang berfokus pada throughput seperti pemrosesan video atau inferensi batch |
|
|
Perkiraan biaya per jam untuk titik akhir real-time Anda. Unit: Dolar AS |
Beban kerja yang sensitif terhadap biaya tanpa tenggat waktu latensi |
|
|
Perkiraan biaya per panggilan inferensi untuk titik akhir real-time Anda. Unit: Dolar AS |
Maksimalkan kinerja harga secara keseluruhan dengan fokus pada throughput |
|
|
Pemanfaatan CPU yang diharapkan pada pemanggilan maksimum per menit untuk instance titik akhir. Unit: Persen |
Memahami kesehatan instance selama benchmarking dengan memiliki visibilitas ke dalam pemanfaatan CPU inti instance |
|
|
Pemanfaatan memori yang diharapkan pada pemanggilan maksimum per menit untuk instance titik akhir. Unit: Persen |
Memahami kesehatan instance selama pembandingan dengan memiliki visibilitas ke dalam pemanfaatan memori inti instance |
Dalam beberapa kasus, Anda mungkin ingin menjelajahi metrik Pemanggilan Titik Akhir SageMaker AI lainnya seperti. CPUUtilization Setiap hasil pekerjaan Inference Recommender mencakup nama-nama titik akhir yang diputar selama uji beban. Anda dapat menggunakan CloudWatch untuk meninjau log untuk titik akhir ini bahkan setelah dihapus.
Gambar berikut adalah contoh CloudWatch metrik dan bagan yang dapat Anda tinjau untuk satu titik akhir dari hasil rekomendasi Anda. Hasil rekomendasi ini berasal dari pekerjaan Default. Cara untuk menafsirkan nilai skalar dari hasil rekomendasi adalah bahwa mereka didasarkan pada titik waktu ketika grafik Invocations pertama kali mulai naik level. Misalnya, ModelLatency nilai yang dilaporkan berada di awal dataran tinggi sekitar. 03:00:31
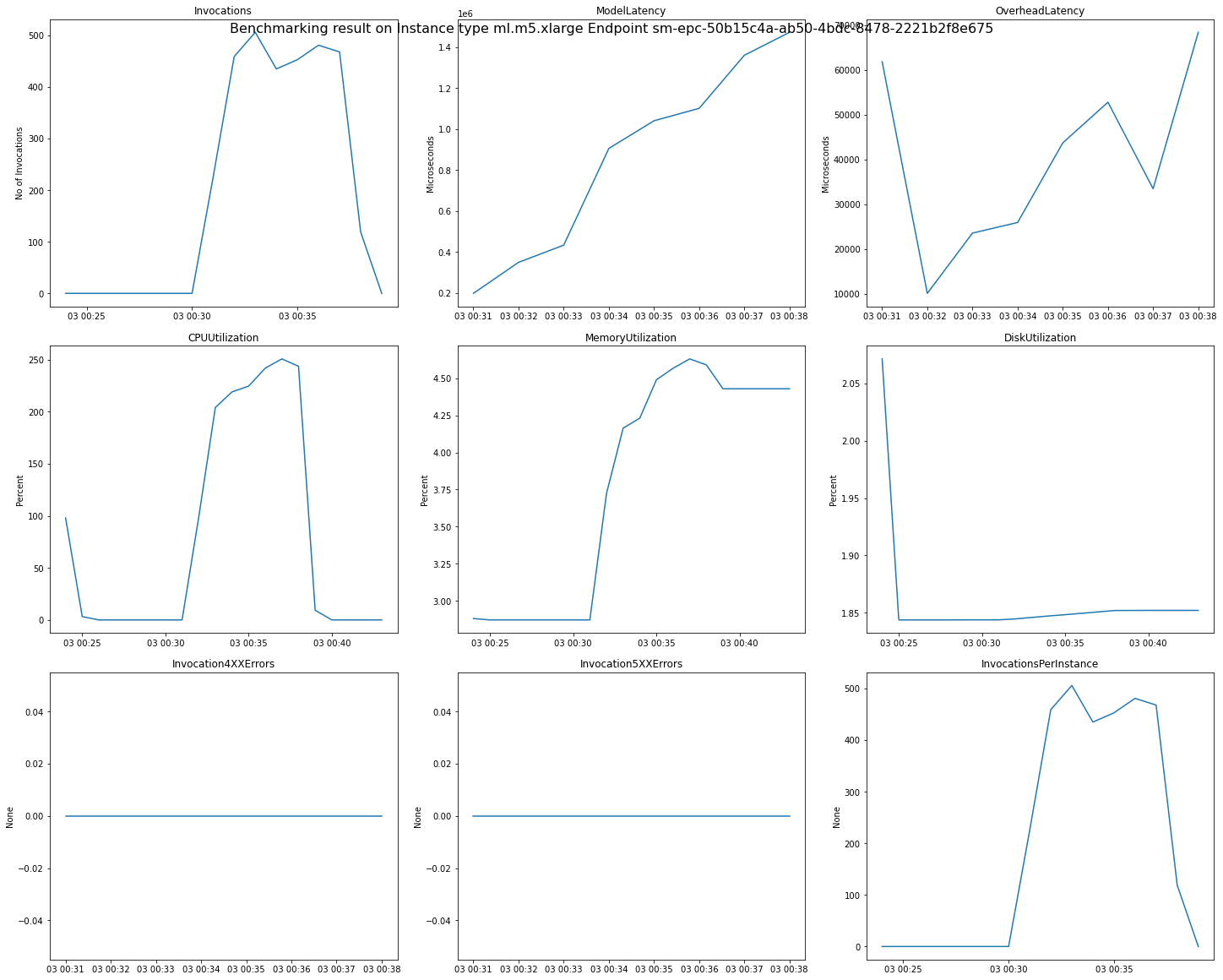
Untuk deskripsi lengkap tentang CloudWatch metrik yang digunakan dalam bagan sebelumnya, lihat Metrik Pemanggilan Titik Akhir SageMaker AI.
Anda juga dapat melihat metrik kinerja seperti ClientInvocations dan NumberOfUsers diterbitkan oleh Inference Recommender di namespace. /aws/sagemaker/InferenceRecommendationsJobs Untuk daftar lengkap metrik dan deskripsi yang diterbitkan oleh Inference Recommender, lihat. SageMaker Metrik pekerjaan Inference Recommender
Lihat Amazon SageMaker Inference Recommender - CloudWatch Metrics
