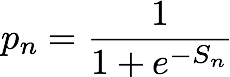Terjemahan disediakan oleh mesin penerjemah. Jika konten terjemahan yang diberikan bertentangan dengan versi bahasa Inggris aslinya, utamakan versi bahasa Inggris.
Bagaimana IP Insights Bekerja
Amazon SageMaker AI IP Insights adalah algoritma tanpa pengawasan yang mengkonsumsi data yang diamati dalam bentuk pasangan (entitas, IPv4 alamat) yang mengaitkan entitas dengan alamat IP. IP Insights menentukan seberapa besar kemungkinan suatu entitas akan menggunakan alamat IP tertentu dengan mempelajari representasi vektor laten untuk entitas dan alamat IP. Jarak antara kedua representasi ini kemudian dapat berfungsi sebagai proxy untuk seberapa besar kemungkinan asosiasi ini.
Algoritma IP Insights menggunakan jaringan saraf untuk mempelajari representasi vektor laten untuk entitas dan alamat IP. Entitas pertama kali di-hash ke ruang hash yang besar tetapi tetap dan kemudian dikodekan oleh lapisan penyematan sederhana. String karakter seperti nama pengguna atau akun IDs dapat dimasukkan langsung ke IP Insights saat muncul di file log. Anda tidak perlu melakukan pra-proses data untuk pengidentifikasi entitas. Anda dapat memberikan entitas sebagai nilai string arbitrer selama pelatihan dan inferensi. Ukuran hash harus dikonfigurasi dengan nilai yang cukup tinggi untuk memastikan bahwa jumlah tabrakan, yang terjadi ketika entitas yang berbeda dipetakan ke vektor laten yang sama, tetap tidak signifikan. Untuk informasi selengkapnya tentang cara memilih ukuran hash yang sesuai, lihat Fitur Hashing untuk Pembelajaran Multitask Skala Besar
Selama pelatihan, IP Insights secara otomatis menghasilkan sampel negatif dengan memasangkan entitas dan alamat IP secara acak. Sampel negatif ini mewakili data yang kecil kemungkinannya terjadi dalam kenyataan. Model dilatih untuk membedakan antara sampel positif yang diamati dalam data pelatihan dan sampel negatif yang dihasilkan ini. Lebih khusus lagi, model dilatih untuk meminimalkan entropi silang, juga dikenal sebagai kehilangan log, didefinisikan sebagai berikut:
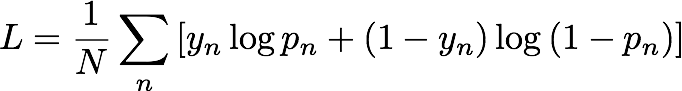
y n adalah label yang menunjukkan apakah sampel berasal dari distribusi nyata yang mengatur data yang diamati (y n = 1) atau dari distribusi yang menghasilkan sampel negatif (y n = 0). p n adalah probabilitas bahwa sampel berasal dari distribusi nyata, seperti yang diprediksi oleh model.
Menghasilkan sampel negatif adalah proses penting yang digunakan untuk mencapai model akurat dari data yang diamati. Jika sampel negatif sangat tidak mungkin, misalnya, jika semua alamat IP dalam sampel negatif adalah 10.0.0.0, maka model secara sepele belajar membedakan sampel negatif dan gagal mengkarakterisasi kumpulan data yang diamati secara akurat. Untuk menjaga sampel negatif lebih realistis, IP Insights menghasilkan sampel negatif baik dengan menghasilkan alamat IP secara acak dan memilih alamat IP secara acak dari data pelatihan. Anda dapat mengonfigurasi jenis pengambilan sampel negatif dan tingkat di mana sampel negatif dihasilkan dengan random_negative_sampling_rate dan shuffled_negative_sampling_rate hiperparameter.
Diberikan nth (entitas, pasangan alamat IP), model IP Insights mengeluarkan skor, Sn, yang menunjukkan seberapa kompatibel entitas dengan alamat IP. Skor ini sesuai dengan rasio odds log untuk (entitas, alamat IP) tertentu dari pasangan yang berasal dari distribusi nyata dibandingkan dengan berasal dari distribusi negatif. Ini didefinisikan sebagai berikut:
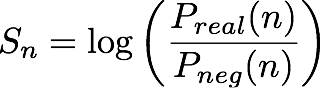
Skor pada dasarnya adalah ukuran kesamaan antara representasi vektor dari entitas ke-n dan alamat IP. Ini dapat diartikan sebagai seberapa besar kemungkinan untuk mengamati peristiwa ini dalam kenyataan daripada dalam kumpulan data yang dihasilkan secara acak. Selama pelatihan, algoritme menggunakan skor ini untuk menghitung perkiraan probabilitas sampel yang berasal dari distribusi riil, pn, untuk digunakan dalam minimisasi entropi silang, di mana: