Terjemahan disediakan oleh mesin penerjemah. Jika konten terjemahan yang diberikan bertentangan dengan versi bahasa Inggris aslinya, utamakan versi bahasa Inggris.
Mekanisme Pemeringkatan Saat Menggunakan Kombinasi Paralelisme Pipa dan Paralelisme Tensor
Bagian ini menjelaskan bagaimana mekanisme peringkat paralelisme model bekerja dengan paralelisme tensor. Ini diperpanjang dari Dasar-Dasar Rankingsmp.tp_rank() tensor, APIs untuk peringkat paralel smp.pp_rank() pipa, dan untuk smp.rdp_rank() peringkat paralel data yang dikurangi. Kelompok proses komunikasi yang sesuai adalah tensor parallel group (TP_GROUP), pipeline parallel group (PP_GROUP), dan reduced-data parallel group RDP_GROUP (). Kelompok-kelompok ini didefinisikan sebagai berikut:
-
Gugus paralel tensor (
TP_GROUP) adalah subset yang dapat dibagi secara merata dari kelompok paralel data, di mana distribusi paralel tensor modul berlangsung. Ketika derajat paralelisme pipa adalah 1,TP_GROUPsama dengan model parallel group ()MP_GROUP. -
Pipeline parallel group (
PP_GROUP) adalah kelompok proses di mana paralelisme pipa terjadi. Ketika derajat paralelisme tensor adalah 1,PP_GROUPsama dengan.MP_GROUP -
Reduced-data parallel group (
RDP_GROUP) adalah serangkaian proses yang memegang partisi paralelisme pipa yang sama dan partisi paralelisme tensor yang sama, dan melakukan paralelisme data di antara mereka sendiri. Ini disebut grup paralelisme data tereduksi karena merupakan bagian dari seluruh kelompok paralelisme data,.DP_GROUPUntuk parameter model yang didistribusikan di dalamTP_GROUP,allreduceoperasi gradien dilakukan hanya untuk grup paralel data tereduksi, sedangkan untuk parameter yang tidak didistribusikan,allreducegradien berlangsung di seluruh.DP_GROUP -
Model parallel group (
MP_GROUP) mengacu pada sekelompok proses yang secara kolektif menyimpan seluruh model. Ini terdiri dari penyatuanPP_GROUPs dari semua peringkat yang ada dalamTP_GROUPproses saat ini. Ketika derajat paralelisme tensor adalah 1,MP_GROUPsetara dengan.PP_GROUPHal ini juga konsisten dengan definisi yang ada dariMP_GROUPdarismdistributedrilis sebelumnya. Perhatikan bahwa arusTP_GROUPadalah bagian dari arusDP_GROUPdan arus.MP_GROUP
Untuk mempelajari lebih lanjut tentang proses komunikasi APIs di pustaka paralelisme SageMaker model, lihat Common API
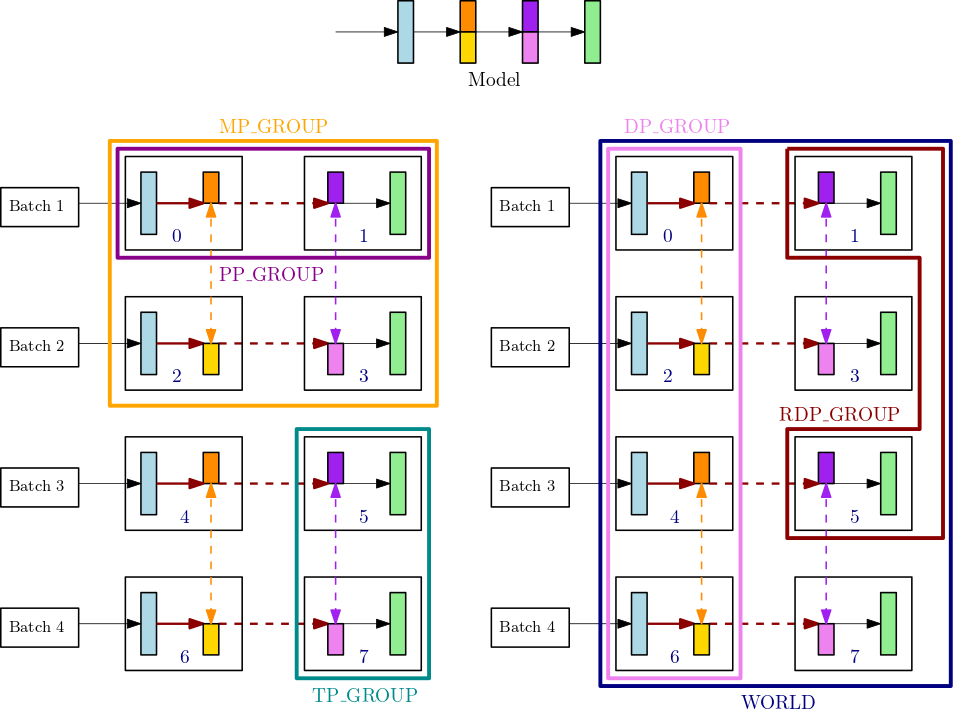
Misalnya, pertimbangkan kelompok proses untuk satu simpul dengan 8 GPUs, di mana derajat paralelisme tensor adalah 2, derajat paralelisme pipa adalah 2, dan tingkat paralelisme data adalah 4. Bagian tengah atas dari gambar sebelumnya menunjukkan contoh model dengan 4 lapisan. Bagian kiri bawah dan kanan bawah gambar menggambarkan model 4-lapisan yang didistribusikan di 4 GPUs menggunakan paralelisme pipa dan paralelisme tensor, di mana paralelisme tensor digunakan untuk dua lapisan tengah. Kedua angka yang lebih rendah ini adalah salinan sederhana untuk menggambarkan garis batas kelompok yang berbeda. Model yang dipartisi direplikasi untuk paralelisme data di 0-3 dan 4-7. GPUs Gambar kiri bawah menunjukkan definisiMP_GROUP,PP_GROUP, danTP_GROUP. Angka kanan bawah menunjukkanRDP_GROUP,DP_GROUP, dan WORLD di atas set yang sama GPUs. Gradien untuk lapisan dan irisan lapisan yang memiliki warna yang sama adalah allreduce d bersama-sama untuk paralelisme data. Misalnya, lapisan pertama (biru muda) mendapatkan allreduce operasiDP_GROUP, sedangkan irisan oranye gelap di lapisan kedua hanya mendapatkan allreduce operasi dalam prosesnyaRDP_GROUP. Panah merah tua yang berani mewakili tensor dengan batch keseluruhannya. TP_GROUP
GPU0: pp_rank 0, tp_rank 0, rdp_rank 0, dp_rank 0, mp_rank 0 GPU1: pp_rank 1, tp_rank 0, rdp_rank 0, dp_rank 0, mp_rank 1 GPU2: pp_rank 0, tp_rank 1, rdp_rank 0, dp_rank 1, mp_rank 2 GPU3: pp_rank 1, tp_rank 1, rdp_rank 0, dp_rank 1, mp_rank 3 GPU4: pp_rank 0, tp_rank 0, rdp_rank 1, dp_rank 2, mp_rank 0 GPU5: pp_rank 1, tp_rank 0, rdp_rank 1, dp_rank 2, mp_rank 1 GPU6: pp_rank 0, tp_rank 1, rdp_rank 1, dp_rank 3, mp_rank 2 GPU7: pp_rank 1, tp_rank 1, rdp_rank 1, dp_rank 3, mp_rank 3
Dalam contoh ini, paralelisme pipa terjadi di seluruh pasangan GPU (0,1); (2,3); (4,5) dan (6,7). Selain itu, paralelisme data (allreduce) terjadi di GPUs 0, 2, 4, 6, dan secara independen di atas GPUs 1, 3, 5, 7. Paralelisme tensor terjadi pada himpunan bagian dari DP_GROUP s, di seluruh pasangan GPU (0,2); (1,3); (4,6) dan (5,7).
