Terjemahan disediakan oleh mesin penerjemah. Jika konten terjemahan yang diberikan bertentangan dengan versi bahasa Inggris aslinya, utamakan versi bahasa Inggris.
Paralelisme Data Sharded
Paralelisme data sharded adalah teknik pelatihan terdistribusi hemat memori yang membagi status model (parameter model, gradien, dan status pengoptimal) di dalam grup paralel data. GPUs
catatan
Paralelisme data sharded tersedia untuk PyTorch di pustaka paralelisme SageMaker model v1.11.0 dan yang lebih baru.
Saat meningkatkan pekerjaan pelatihan Anda ke cluster GPU besar, Anda dapat mengurangi jejak memori per-GPU model dengan membagi status pelatihan model ke beberapa. GPUs Ini mengembalikan dua manfaat: Anda dapat memasukkan model yang lebih besar, yang jika tidak akan kehabisan memori dengan paralelisme data standar, atau Anda dapat meningkatkan ukuran batch menggunakan memori GPU yang dibebaskan.
Teknik paralelisme data standar mereplikasi status pelatihan di seluruh grup paralel data, dan melakukan agregasi gradien berdasarkan operasi. GPUs AllReduce Paralelisme data sharded memodifikasi prosedur pelatihan terdistribusi data-paralel standar untuk memperhitungkan sifat sharded dari status pengoptimal. Sekelompok peringkat di mana status model dan pengoptimal dipecah disebut grup sharding. Teknik paralelisme data sharded memecah parameter model yang dapat dilatih dan gradien serta status pengoptimal yang sesuai di seluruh dalam grup sharding. GPUs
SageMaker AI mencapai paralelisme data yang dibagi melalui implementasi MIC, yang dibahas dalam posting AWS blog Penskalaan hampirAllGather Setelah pass maju atau mundur dari setiap lapisan, MIC memecah parameter lagi untuk menghemat memori GPU. Selama lintasan mundur, MIC mengurangi gradien dan secara bersamaan memecahnya melalui operasi. GPUs ReduceScatter Terakhir, MIC menerapkan gradien lokal tereduksi dan sharded ke pecahan parameter lokal yang sesuai, menggunakan pecahan lokal status pengoptimal. Untuk menurunkan overhead komunikasi, pustaka paralelisme SageMaker model mengambil lapisan yang akan datang di pass maju atau mundur, dan tumpang tindih komunikasi jaringan dengan komputasi.
Status pelatihan model direplikasi di seluruh kelompok sharding. Ini berarti bahwa sebelum gradien diterapkan pada parameter, AllReduce operasi harus dilakukan di seluruh kelompok sharding, selain ReduceScatter operasi yang terjadi dalam grup sharding.
Akibatnya, paralelisme data sharded memperkenalkan tradeoff antara overhead komunikasi dan efisiensi memori GPU. Menggunakan paralelisme data sharded meningkatkan biaya komunikasi, tetapi jejak memori per GPU (tidak termasuk penggunaan memori karena aktivasi) dibagi dengan tingkat paralelisme data sharded, sehingga model yang lebih besar dapat dimasukkan ke dalam cluster GPU.
Memilih tingkat paralelisme data sharded
Ketika Anda memilih nilai untuk tingkat paralelisme data sharded, nilai harus membagi derajat paralelisme data secara merata. Misalnya, untuk pekerjaan paralelisme data 8 arah, pilih 2, 4, atau 8 untuk tingkat paralelisme data sharded. Saat memilih tingkat paralelisme data yang dibagikan, kami menyarankan Anda memulai dengan jumlah kecil, dan secara bertahap meningkatkannya hingga model sesuai dengan memori bersama dengan ukuran batch yang diinginkan.
Memilih ukuran batch
Setelah menyiapkan paralelisme data sharded, pastikan Anda menemukan konfigurasi pelatihan paling optimal yang berhasil dijalankan di cluster GPU. Untuk melatih model bahasa besar (LLM), mulai dari ukuran batch 1, dan secara bertahap tingkatkan hingga Anda mencapai titik untuk menerima kesalahan out-of-memory (OOM). Jika Anda menemukan kesalahan OOM bahkan dengan ukuran batch terkecil, terapkan tingkat paralelisme data sharded yang lebih tinggi atau kombinasi paralelisme data sharded dan paralelisme tensor.
Topik
Cara menerapkan paralelisme data sharded ke pekerjaan pelatihan Anda
Untuk memulai paralelisme data sharded, terapkan modifikasi yang diperlukan pada skrip pelatihan Anda, dan atur SageMaker PyTorch estimator dengan parameter. sharded-data-parallelism-specific Pertimbangkan juga untuk mengambil nilai referensi dan contoh notebook sebagai titik awal.
Sesuaikan skrip PyTorch pelatihan Anda
Ikuti instruksi di Langkah 1: Ubah Skrip PyTorch Pelatihan untuk membungkus objek model dan pengoptimal dengan smdistributed.modelparallel.torch pembungkus modul torch.nn.parallel dantorch.distributed.
(Opsional) Modifikasi tambahan untuk mendaftarkan parameter model eksternal
Jika model Anda dibangun dengan torch.nn.Module dan menggunakan parameter yang tidak ditentukan dalam kelas modul, Anda harus mendaftarkannya ke modul secara manual untuk SMP untuk mengumpulkan parameter penuh sementara. Untuk mendaftarkan parameter ke modul, gunakansmp.register_parameter(module,
parameter).
class Module(torch.nn.Module): def __init__(self, *args): super().__init__(self, *args) self.layer1 = Layer1() self.layer2 = Layer2() smp.register_parameter(self, self.layer1.weight) def forward(self, input): x = self.layer1(input) # self.layer1.weight is required by self.layer2.forward y = self.layer2(x, self.layer1.weight) return y
Siapkan SageMaker PyTorch estimator
Saat mengonfigurasi SageMaker PyTorch estimatorLangkah 2: Luncurkan Training Job Menggunakan SageMaker Python SDK, tambahkan parameter untuk paralelisme data sharded.
Untuk mengaktifkan paralelisme data sharded, tambahkan sharded_data_parallel_degree parameter ke Estimator. SageMaker PyTorch Parameter ini menentukan jumlah GPUs di mana status pelatihan dipecah. Nilai untuk sharded_data_parallel_degree harus berupa bilangan bulat antara satu dan derajat paralelisme data dan harus membagi derajat paralelisme data secara merata. Perhatikan bahwa perpustakaan secara otomatis mendeteksi jumlah GPUs sehingga tingkat paralel data. Parameter tambahan berikut tersedia untuk mengonfigurasi paralelisme data sharded.
-
"sdp_reduce_bucket_size"(int, default: 5e8) - Menentukan ukuran ember gradien PyTorch DDPdalam jumlah elemen dtype default. -
"sdp_param_persistence_threshold"(int, default: 1e6) — Menentukan ukuran tensor parameter dalam jumlah elemen yang dapat bertahan di setiap GPU. Paralelisme data sharded membagi setiap tensor parameter di seluruh grup paralel data. GPUs Jika jumlah elemen dalam tensor parameter lebih kecil dari ambang batas ini, tensor parameter tidak terbelah; ini membantu mengurangi overhead komunikasi karena tensor parameter direplikasi di seluruh data-paralel. GPUs -
"sdp_max_live_parameters"(int, default: 1e9) — Menentukan jumlah maksimum parameter yang secara bersamaan dapat berada dalam keadaan pelatihan rekombinasi selama pass maju dan mundur. Pengambilan parameter denganAllGatheroperasi berhenti ketika jumlah parameter aktif mencapai ambang batas yang diberikan. Perhatikan bahwa meningkatkan parameter ini meningkatkan jejak memori. -
"sdp_hierarchical_allgather"(bool, default: True) - Jika disetel keTrue,AllGatheroperasi berjalan secara hierarkis: berjalan di dalam setiap node terlebih dahulu, dan kemudian berjalan melintasi node. Untuk pekerjaan pelatihan terdistribusi multi-node,AllGatheroperasi hierarkis diaktifkan secara otomatis. -
"sdp_gradient_clipping"(float, default: 1.0) — Menentukan ambang batas untuk gradien memotong norma L2 dari gradien sebelum menyebarkannya mundur melalui parameter model. Ketika paralelisme data sharded diaktifkan, kliping gradien juga diaktifkan. Ambang batas default adalah1.0. Sesuaikan parameter ini jika Anda memiliki masalah gradien yang meledak.
Kode berikut menunjukkan contoh cara mengkonfigurasi paralelisme data sharded.
import sagemaker from sagemaker.pytorch import PyTorch smp_options = { "enabled": True, "parameters": { # "pipeline_parallel_degree": 1, # Optional, default is 1 # "tensor_parallel_degree": 1, # Optional, default is 1 "ddp": True, # parameters for sharded data parallelism "sharded_data_parallel_degree":2, # Add this to activate sharded data parallelism "sdp_reduce_bucket_size": int(5e8), # Optional "sdp_param_persistence_threshold": int(1e6), # Optional "sdp_max_live_parameters": int(1e9), # Optional "sdp_hierarchical_allgather":True, # Optional "sdp_gradient_clipping":1.0# Optional } } mpi_options = { "enabled" : True, # Required "processes_per_host" :8# Required } smp_estimator = PyTorch( entry_point="your_training_script.py", # Specify your train script role=sagemaker.get_execution_role(), instance_count=1, instance_type='ml.p3.16xlarge', framework_version='1.13.1', py_version='py3', distribution={ "smdistributed": {"modelparallel": smp_options}, "mpi": mpi_options }, base_job_name="sharded-data-parallel-job" ) smp_estimator.fit('s3://my_bucket/my_training_data/')
Konfigurasi referensi
Tim pelatihan SageMaker terdistribusi menyediakan konfigurasi referensi berikut yang dapat Anda gunakan sebagai titik awal. Anda dapat mengekstrapolasi dari konfigurasi berikut untuk bereksperimen dan memperkirakan penggunaan memori GPU untuk konfigurasi model Anda.
Paralelisme data sharded dengan SMDDP Collectives
| Model/jumlah parameter | Contoh num | Jenis instans | Panjang urutan | Ukuran batch global | Ukuran batch mini | Derajat paralel data sharded |
|---|---|---|---|---|---|---|
| GPT-NEOX-20B | 2 | ml.p4d.24xlarge | 2048 | 64 | 4 | 16 |
| GPT-NEOX-20B | 8 | ml.p4d.24xlarge | 2048 | 768 | 12 | 32 |
Misalnya, jika Anda menambah panjang urutan untuk model 20 miliar parameter atau menambah ukuran model menjadi 65 miliar parameter, Anda perlu mencoba mengurangi ukuran batch terlebih dahulu. Jika model masih tidak sesuai dengan ukuran batch terkecil (ukuran batch 1), coba tingkatkan derajat paralelisme model.
Paralelisme data sharded dengan paralelisme tensor dan NCCL Collectives
| Model/jumlah parameter | Contoh num | Jenis instans | Panjang urutan | Ukuran batch global | Ukuran batch mini | Derajat paralel data sharded | Derajat paralel tensor | Pembongkaran aktivasi |
|---|---|---|---|---|---|---|---|---|
| GPT-NEOX-65B | 64 | ml.p4d.24xlarge | 2048 | 512 | 8 | 16 | 8 | T |
| GPT-NEOX-65B | 64 | ml.p4d.24xlarge | 4096 | 512 | 2 | 64 | 2 | T |
Penggunaan gabungan paralelisme data sharded dan paralelisme tensor berguna ketika Anda ingin memasukkan model bahasa besar (LLM) ke dalam cluster skala besar saat menggunakan data teks dengan panjang urutan yang lebih panjang, yang mengarah pada penggunaan ukuran batch yang lebih kecil, dan akibatnya menangani penggunaan memori GPU untuk melatih urutan teks yang lebih panjang. LLMs Untuk mempelajari selengkapnya, lihat Paralelisme data sharded dengan paralelisme tensor.
Untuk studi kasus, tolok ukur, dan contoh konfigurasi lainnya, lihat posting blog Peningkatan kinerja baru di perpustakaan paralel model Amazon SageMaker AI
Paralelisme data sharded dengan SMDDP Collectives
Perpustakaan paralelisme SageMaker data menawarkan primitif komunikasi kolektif (kolektif SMDDP) yang dioptimalkan untuk infrastruktur. AWS Ini mencapai optimasi dengan mengadopsi pola all-to-all-type komunikasi dengan memanfaatkan Elastic Fabric Adapter (
catatan
Paralelisme data sharded dengan SMDDP Collectives tersedia di perpustakaan paralelisme SageMaker model v1.13.0 dan yang lebih baru, dan perpustakaan paralelisme data v1.6.0 dan yang lebih baru. SageMaker Lihat juga Supported configurations untuk menggunakan paralelisme data sharded dengan SMDDP Collectives.
Dalam paralelisme data sharded, yang merupakan teknik yang umum digunakan dalam pelatihan terdistribusi skala besar, AllGather kolektif digunakan untuk menyusun kembali parameter lapisan sharded untuk komputasi pass maju dan mundur, secara paralel dengan komputasi GPU. Untuk model besar, melakukan AllGather operasi secara efisien sangat penting untuk menghindari masalah kemacetan GPU dan memperlambat kecepatan pelatihan. Ketika paralelisme data sharded diaktifkan, SMDDP Collectives masuk ke dalam kolektif kritis kinerja AllGather ini, meningkatkan throughput pelatihan.
Berlatih dengan SMDDP Collectives
Ketika pekerjaan pelatihan Anda telah berbagi paralelisme data diaktifkan dan memenuhiSupported configurations, SMDDP Collectives diaktifkan secara otomatis. Secara internal, SMDDP Collectives mengoptimalkan AllGather kolektif untuk berkinerja pada AWS infrastruktur dan kembali ke NCCL untuk semua kolektif lainnya. Selanjutnya, di bawah konfigurasi yang tidak didukung, semua kolektif, termasukAllGather, secara otomatis menggunakan backend NCCL.
Karena pustaka paralelisme SageMaker model versi 1.13.0, "ddp_dist_backend" parameter ditambahkan ke opsi. modelparallel Nilai default untuk parameter konfigurasi ini adalah"auto", yang menggunakan SMDDP Collectives bila memungkinkan, dan kembali ke NCCL sebaliknya. Untuk memaksa perpustakaan untuk selalu menggunakan NCCL, tentukan "nccl" ke parameter "ddp_dist_backend" konfigurasi.
Contoh kode berikut menunjukkan cara mengatur PyTorch estimator menggunakan paralelisme data sharded dengan "ddp_dist_backend" parameter, yang diatur ke default dan, "auto" oleh karena itu, opsional untuk ditambahkan.
import sagemaker from sagemaker.pytorch import PyTorch smp_options = { "enabled":True, "parameters": { "partitions": 1, "ddp": True, "sharded_data_parallel_degree":64"bf16": True, "ddp_dist_backend": "auto" # Specify "nccl" to force to use NCCL. } } mpi_options = { "enabled" : True, # Required "processes_per_host" : 8 # Required } smd_mp_estimator = PyTorch( entry_point="your_training_script.py", # Specify your train script source_dir="location_to_your_script", role=sagemaker.get_execution_role(), instance_count=8, instance_type='ml.p4d.24xlarge', framework_version='1.13.1', py_version='py3', distribution={ "smdistributed": {"modelparallel": smp_options}, "mpi": mpi_options }, base_job_name="sharded-data-parallel-demo", ) smd_mp_estimator.fit('s3://my_bucket/my_training_data/')
Konfigurasi yang didukung
AllGatherOperasi dengan SMDDP Collectives diaktifkan dalam pekerjaan pelatihan ketika semua persyaratan konfigurasi berikut terpenuhi.
-
Tingkat paralelisme data sharded lebih besar dari 1
-
Instance_countlebih besar dari 1 -
Instance_typesama denganml.p4d.24xlarge -
SageMaker wadah pelatihan untuk PyTorch v1.12.1 atau yang lebih baru
-
Pustaka paralelisme SageMaker data v1.6.0 atau yang lebih baru
-
Pustaka paralelisme SageMaker model v1.13.0 atau yang lebih baru
Kinerja dan penyetelan memori
SMDDP Collectives menggunakan memori GPU tambahan. Ada dua variabel lingkungan untuk mengonfigurasi penggunaan memori GPU tergantung pada kasus penggunaan pelatihan model yang berbeda.
-
SMDDP_AG_SCRATCH_BUFFER_SIZE_BYTES— SelamaAllGatheroperasi SMDDP, bufferAllGatherinput disalin ke buffer sementara untuk komunikasi antar simpul.SMDDP_AG_SCRATCH_BUFFER_SIZE_BYTESVariabel mengontrol ukuran (dalam byte) dari buffer sementara ini. Jika ukuran buffer sementara lebih kecil dari ukuran bufferAllGatherinput,AllGatherkolektif akan kembali menggunakan NCCL.-
Nilai default: 16 * 1024 * 1024 (16 MB)
-
Nilai yang dapat diterima: kelipatan 8192
-
-
SMDDP_AG_SORT_BUFFER_SIZE_BYTESSMDDP_AG_SORT_BUFFER_SIZE_BYTESVariabelnya adalah untuk mengukur buffer sementara (dalam byte) untuk menyimpan data yang dikumpulkan dari komunikasi antar simpul. Jika ukuran buffer sementara ini lebih kecil dari1/8 * sharded_data_parallel_degree * AllGather input size,AllGatherkolektif akan kembali menggunakan NCCL.-
Nilai default: 128 * 1024 * 1024 (128 MB)
-
Nilai yang dapat diterima: kelipatan 8192
-
Panduan penyetelan pada variabel ukuran buffer
Nilai default untuk variabel lingkungan harus berfungsi dengan baik untuk sebagian besar kasus penggunaan. Kami merekomendasikan untuk menyetel variabel-variabel ini hanya jika pelatihan mengalami kesalahan out-of-memory (OOM).
Daftar berikut membahas beberapa tips penyetelan untuk mengurangi jejak memori GPU SMDDP Collectives sambil mempertahankan keuntungan kinerja dari mereka.
-
Penyetelan
SMDDP_AG_SCRATCH_BUFFER_SIZE_BYTES-
Ukuran buffer
AllGatherinput lebih kecil untuk model yang lebih kecil. Oleh karena itu, ukuran yang diperlukan untukSMDDP_AG_SCRATCH_BUFFER_SIZE_BYTESbisa lebih kecil untuk model dengan parameter lebih sedikit. -
Ukuran buffer
AllGatherinput berkurang seiringsharded_data_parallel_degreebertambahnya, karena model akan lebih banyak dipecah. GPUs Oleh karena itu, ukuran yang diperlukan untukSMDDP_AG_SCRATCH_BUFFER_SIZE_BYTESbisa lebih kecil untuk pekerjaan pelatihan dengan nilai besar untuksharded_data_parallel_degree.
-
-
Penyetelan
SMDDP_AG_SORT_BUFFER_SIZE_BYTES-
Jumlah data yang dikumpulkan dari komunikasi antar simpul lebih sedikit untuk model dengan parameter yang lebih sedikit. Oleh karena itu, ukuran yang diperlukan untuk
SMDDP_AG_SORT_BUFFER_SIZE_BYTESbisa lebih kecil untuk model tersebut dengan jumlah parameter yang lebih sedikit.
-
Beberapa kolektif mungkin kembali menggunakan NCCL; karenanya, Anda mungkin tidak mendapatkan keuntungan kinerja dari kolektif SMDDP yang dioptimalkan. Jika memori GPU tambahan tersedia untuk digunakan, Anda dapat mempertimbangkan untuk meningkatkan nilai SMDDP_AG_SCRATCH_BUFFER_SIZE_BYTES dan SMDDP_AG_SORT_BUFFER_SIZE_BYTES untuk mendapatkan keuntungan dari peningkatan kinerja.
Kode berikut menunjukkan bagaimana Anda dapat mengkonfigurasi variabel lingkungan dengan menambahkannya ke mpi_options dalam parameter distribusi untuk PyTorch estimator.
import sagemaker from sagemaker.pytorch import PyTorch smp_options = { .... # All modelparallel configuration options go here } mpi_options = { "enabled" : True, # Required "processes_per_host" : 8 # Required } # Use the following two lines to tune values of the environment variables for buffer mpioptions += " -x SMDDP_AG_SCRATCH_BUFFER_SIZE_BYTES=8192" mpioptions += " -x SMDDP_AG_SORT_BUFFER_SIZE_BYTES=8192" smd_mp_estimator = PyTorch( entry_point="your_training_script.py", # Specify your train script source_dir="location_to_your_script", role=sagemaker.get_execution_role(), instance_count=8, instance_type='ml.p4d.24xlarge', framework_version='1.13.1', py_version='py3', distribution={ "smdistributed": {"modelparallel": smp_options}, "mpi": mpi_options }, base_job_name="sharded-data-parallel-demo-with-tuning", ) smd_mp_estimator.fit('s3://my_bucket/my_training_data/')
Pelatihan presisi campuran dengan paralelisme data sharded
Untuk lebih menghemat memori GPU dengan angka floating point setengah presisi dan paralelisme data sharded, Anda dapat mengaktifkan format floating point 16-bit (FP16) atau Brain floating point format
catatan
Pelatihan presisi campuran dengan paralelisme data sharded tersedia di perpustakaan paralelisme SageMaker model v1.11.0 dan yang lebih baru.
Untuk FP16 Pelatihan dengan Paralelisme Data Sharded
Untuk menjalankan FP16 pelatihan dengan paralelisme data sharded, tambahkan "fp16": True" ke kamus konfigurasi. smp_options Dalam skrip pelatihan Anda, Anda dapat memilih antara opsi penskalaan kerugian statis dan dinamis melalui smp.DistributedOptimizer modul. Untuk informasi selengkapnya, lihat FP16 Pelatihan dengan Model Paralelisme.
smp_options = { "enabled":True, "parameters": { "ddp":True, "sharded_data_parallel_degree":2, "fp16":True} }
Untuk BF16 Pelatihan dengan Paralelisme Data Sharded
Fitur paralelisme data sharded SageMaker AI mendukung pelatihan tipe data. BF16 Tipe BF16 data menggunakan 8 bit untuk mewakili eksponen nomor floating point, sedangkan tipe FP16 data menggunakan 5 bit. Mempertahankan 8 bit untuk eksponen memungkinkan untuk mempertahankan representasi yang sama dari eksponen nomor floating point () presisi tunggal 32-bit. FP32 Hal ini membuat konversi antara FP32 dan BF16 lebih sederhana dan secara signifikan kurang rentan menyebabkan masalah overflow dan underflow yang sering muncul dalam FP16 pelatihan, terutama saat melatih model yang lebih besar. Sementara kedua tipe data menggunakan total 16 bit, rentang representasi yang meningkat untuk eksponen dalam BF16 format ini mengorbankan presisi yang berkurang. Untuk melatih model besar, presisi yang berkurang ini sering dianggap sebagai trade-off yang dapat diterima untuk jangkauan dan stabilitas pelatihan.
catatan
Saat ini, BF16 pelatihan hanya berfungsi ketika paralelisme data sharded diaktifkan.
Untuk menjalankan BF16 pelatihan dengan paralelisme data sharded, tambahkan "bf16": True ke kamus konfigurasi. smp_options
smp_options = { "enabled":True, "parameters": { "ddp":True, "sharded_data_parallel_degree":2, "bf16":True} }
Paralelisme data sharded dengan paralelisme tensor
Jika Anda menggunakan paralelisme data sharded dan juga perlu mengurangi ukuran batch global, pertimbangkan untuk menggunakan paralelisme tensor dengan paralelisme data sharded. Saat melatih model besar dengan paralelisme data sharded pada cluster komputasi yang sangat besar (biasanya 128 node atau lebih), bahkan ukuran batch kecil per GPU menghasilkan ukuran batch global yang sangat besar. Ini mungkin menyebabkan masalah konvergensi atau masalah kinerja komputasi yang rendah. Mengurangi ukuran batch per GPU terkadang tidak dimungkinkan dengan paralelisme data sharded saja ketika satu batch sudah besar dan tidak dapat dikurangi lebih lanjut. Dalam kasus seperti itu, menggunakan paralelisme data sharded dalam kombinasi dengan paralelisme tensor membantu mengurangi ukuran batch global.
Memilih paralel data sharded optimal dan derajat paralel tensor bergantung pada skala model, jenis instance, dan ukuran batch global yang masuk akal untuk model untuk bertemu. Kami menyarankan Anda memulai dari derajat paralel tensor rendah agar sesuai dengan ukuran batch global ke dalam cluster komputasi untuk mengatasi out-of-memory kesalahan CUDA dan mencapai kinerja terbaik. Lihat dua contoh kasus berikut untuk mempelajari bagaimana kombinasi paralelisme tensor dan paralelisme data sharded membantu Anda menyesuaikan ukuran batch global dengan mengelompokkan GPUs paralelisme model, menghasilkan jumlah replika model yang lebih rendah dan ukuran batch global yang lebih kecil.
catatan
Fitur ini tersedia dari pustaka paralelisme SageMaker model v1.15, dan mendukung v1.13.1. PyTorch
catatan
Fitur ini tersedia untuk model yang didukung oleh fungsionalitas paralelisme tensor perpustakaan. Untuk menemukan daftar model yang didukung, lihat Support for Hugging Face Transformer Models. Perhatikan juga bahwa Anda harus tensor_parallelism=True meneruskan smp.model_creation argumen sambil memodifikasi skrip pelatihan Anda. Untuk mempelajari lebih lanjut, lihat skrip pelatihan train_gpt_simple.py
Contoh 1
Asumsikan bahwa kita ingin melatih model di atas cluster 1536 GPUs (192 node dengan masing-masing 8 GPUs ), mengatur tingkat paralelisme data sharded menjadi 32 (sharded_data_parallel_degree=32) dan ukuran batch per GPU menjadi 1, di mana setiap batch memiliki panjang urutan 4096 token. Dalam hal ini, ada 1536 replika model, ukuran batch global menjadi 1536, dan setiap batch global berisi sekitar 6 juta token.
(1536 GPUs) * (1 batch per GPU) = (1536 global batches) (1536 batches) * (4096 tokens per batch) = (6,291,456 tokens)
Menambahkan paralelisme tensor ke dalamnya dapat menurunkan ukuran batch global. Salah satu contoh konfigurasi dapat mengatur derajat paralel tensor ke 8 dan ukuran batch per GPU menjadi 4. Ini membentuk 192 kelompok paralel tensor atau 192 replika model, di mana setiap replika model didistribusikan di 8. GPUs Ukuran batch 4 adalah jumlah data pelatihan per iterasi dan per kelompok paralel tensor; yaitu, setiap replika model mengkonsumsi 4 batch per iterasi. Dalam hal ini, ukuran batch global menjadi 768, dan setiap batch global berisi sekitar 3 juta token. Oleh karena itu, ukuran batch global berkurang setengahnya dibandingkan dengan kasus sebelumnya dengan paralelisme data sharded saja.
(1536 GPUs) / (8 tensor parallel degree) = (192 tensor parallelism groups) (192 tensor parallelism groups) * (4 batches per tensor parallelism group) = (768 global batches) (768 batches) * (4096 tokens per batch) = (3,145,728 tokens)
Contoh 2
Ketika paralelisme data sharded dan paralelisme tensor diaktifkan, perpustakaan pertama-tama menerapkan paralelisme tensor dan memecah model di seluruh dimensi ini. Untuk setiap peringkat paralel tensor, paralelisme data diterapkan sesuai. sharded_data_parallel_degree
Misalnya, asumsikan bahwa kita ingin mengatur 32 GPUs dengan derajat paralel tensor 4 (membentuk kelompok 4 GPUs), derajat paralel data sharded 4, berakhir dengan derajat replikasi 2. Penugasan tersebut membuat delapan grup GPU berdasarkan derajat paralel tensor sebagai berikut(0,1,2,3):(4,5,6,7),,,,(8,9,10,11),(12,13,14,15), (16,17,18,19)(20,21,22,23),(24,25,26,27). (28,29,30,31) Artinya, empat GPUs membentuk satu kelompok paralel tensor. Dalam hal ini, kelompok paralel data tereduksi untuk peringkat 0 GPUs dari kelompok paralel tensor adalah. (0,4,8,12,16,20,24,28) Kelompok paralel data tereduksi dipecah berdasarkan derajat paralel data sharded 4, menghasilkan dua kelompok replikasi untuk paralelisme data. GPUs(0,4,8,12)membentuk satu kelompok sharding, yang secara kolektif menyimpan salinan lengkap semua parameter untuk peringkat paralel tensor ke-0, dan GPUs (16,20,24,28) membentuk kelompok lain seperti itu. Peringkat paralel tensor lainnya juga memiliki kelompok sharding dan replikasi yang serupa.
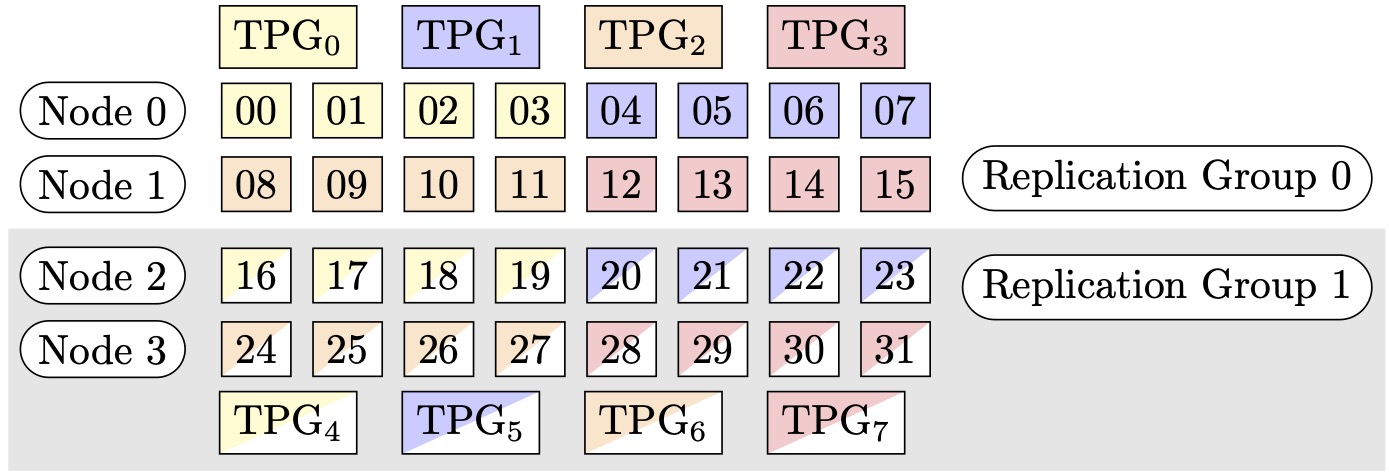
Gambar 1: Kelompok paralelisme tensor untuk (node, derajat paralel data sharded, derajat paralel tensor) = (4, 4, 4), di mana setiap persegi panjang mewakili GPU dengan indeks dari 0 hingga 31. GPUs Bentuk kelompok paralelisme tensor dari TPG ke 0 TPG. 7 Grup replikasi adalah ({TPG0, TPG4}, {TPG, TPG}1, {TPG, TPG5} dan {TPG 23, TPG 67}); setiap pasangan grup replikasi berbagi warna yang sama tetapi diisi secara berbeda.
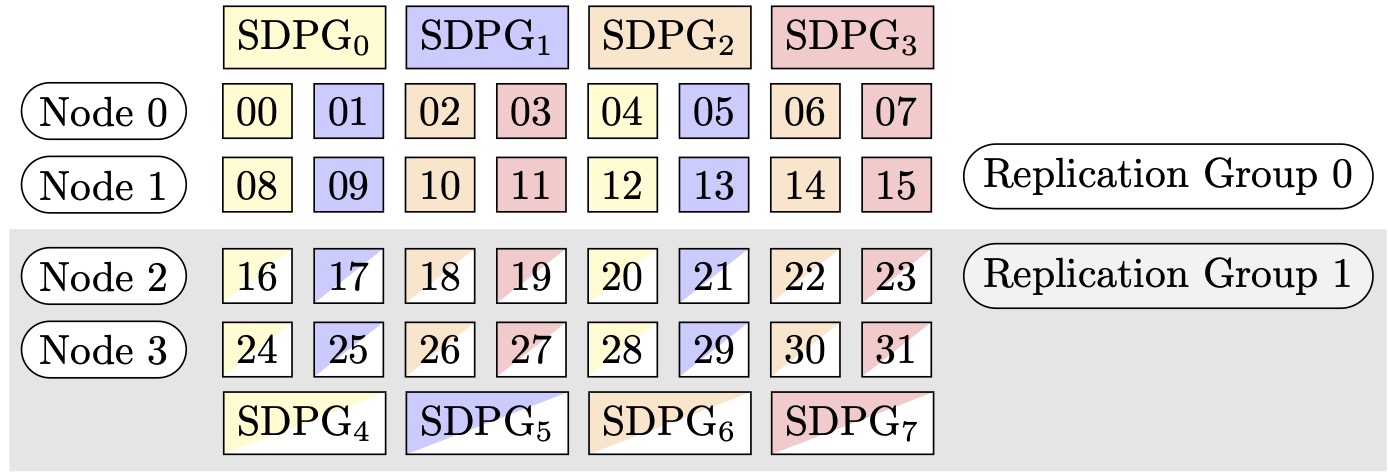
Gambar 2: Kelompok paralelisme data sharded untuk (node, derajat paralel data sharded, derajat paralel tensor) = (4, 4, 4), di mana setiap persegi panjang mewakili GPU dengan indeks dari 0 hingga 31. GPUs Formulir berbagi kelompok paralelisme data dari SDPG ke 0 SDPG. 7 Grup replikasi adalah ({SDPG0, SDPG4}, {SDPG, SDPG}1, {SDPG, SDPG5} dan {SDPG 23, SDPG 67}); setiap pasangan grup replikasi berbagi warna yang sama tetapi diisi secara berbeda.
Cara mengaktifkan paralelisme data sharded dengan paralelisme tensor
Untuk menggunakan paralelisme data sharded dengan paralelisme tensor, Anda perlu mengatur keduanya sharded_data_parallel_degree dan tensor_parallel_degree dalam konfigurasi distribution saat membuat objek dari kelas estimator. SageMaker PyTorch
Anda juga perlu mengaktifkanprescaled_batch. Ini berarti bahwa, alih-alih setiap GPU membaca kumpulan datanya sendiri, setiap grup paralel tensor secara kolektif membaca kumpulan gabungan dari ukuran batch yang dipilih. Secara efektif, alih-alih membagi dataset menjadi bagian-bagian yang sama dengan jumlah GPUs (atau ukuran paralel data,smp.dp_size()), ia membagi menjadi bagian-bagian yang sama dengan jumlah GPUs dibagi dengan tensor_parallel_degree (juga disebut ukuran paralel data tereduksi,). smp.rdp_size() Untuk detail selengkapnya tentang batch pra-skala, lihat Batch Prescaled dalam dokumentasi SageMaker train_gpt_simple.py
Cuplikan kode berikut menunjukkan contoh pembuatan objek PyTorch estimator berdasarkan skenario yang disebutkan di atas. Contoh 2
mpi_options = "-verbose --mca orte_base_help_aggregate 0 " smp_parameters = { "ddp": True, "fp16": True, "prescaled_batch": True, "sharded_data_parallel_degree":4, "tensor_parallel_degree":4} pytorch_estimator = PyTorch( entry_point="your_training_script.py", role=role, instance_type="ml.p4d.24xlarge", volume_size=200, instance_count=4, sagemaker_session=sagemaker_session, py_version="py3", framework_version="1.13.1", distribution={ "smdistributed": { "modelparallel": { "enabled": True, "parameters": smp_parameters, } }, "mpi": { "enabled": True, "processes_per_host": 8, "custom_mpi_options": mpi_options, }, }, source_dir="source_directory_of_your_code", output_path=s3_output_location)
Kiat dan pertimbangan untuk menggunakan paralelisme data sharded
Pertimbangkan hal berikut saat menggunakan paralelisme data sharded pustaka paralelisme SageMaker model.
-
Paralelisme data sharded kompatibel dengan pelatihan. FP16 Untuk menjalankan FP16 pelatihan, lihat FP16 Pelatihan dengan Model Paralelisme bagian.
-
Paralelisme data sharded kompatibel dengan paralelisme tensor. Item berikut adalah apa yang mungkin perlu Anda pertimbangkan untuk menggunakan paralelisme data sharded dengan paralelisme tensor.
-
Saat menggunakan paralelisme data sharded dengan paralelisme tensor, lapisan penyematan juga didistribusikan secara otomatis di seluruh grup paralel tensor. Dengan kata lain,
distribute_embeddingparameter secara otomatis diatur keTrue. Untuk informasi lebih lanjut tentang paralelisme tensor, lihat. Paralelisme Tensor -
Perhatikan bahwa paralelisme data sharded dengan paralelisme tensor saat ini menggunakan kolektif NCCL sebagai backend dari strategi pelatihan terdistribusi.
Untuk mempelajari lebih lanjut, lihat Paralelisme data sharded dengan paralelisme tensor bagian.
-
-
Paralelisme data sharded saat ini tidak kompatibel dengan paralelisme pipa atau sharding status pengoptimal. Untuk mengaktifkan paralelisme data sharded, matikan sharding status pengoptimal dan atur derajat paralel pipeline ke 1.
-
Fitur checkpointing aktivasi dan pembongkaran aktivasi kompatibel dengan paralelisme data sharded.
-
Untuk menggunakan paralelisme data sharded dengan akumulasi gradien, setel
backward_passes_per_stepargumen ke jumlah langkah akumulasi sambil membungkus model Anda dengan modul.smdistributed.modelparallel.torch.DistributedModelIni memastikan bahwa AllReduceoperasi gradien di seluruh grup replikasi model (grup sharding) berlangsung pada batas akumulasi gradien. -
Anda dapat memeriksa model Anda yang dilatih dengan paralelisme data sharded menggunakan pos pemeriksaan perpustakaan, dan. APIs
smp.save_checkpointsmp.resume_from_checkpointUntuk informasi selengkapnya, lihat Checkpointing PyTorch model terdistribusi (untuk pustaka paralelisme SageMaker model v1.10.0 dan yang lebih baru). -
Perilaku parameter
delayed_parameter_initializationkonfigurasi berubah di bawah paralelisme data sharded. Ketika kedua fitur ini diaktifkan secara bersamaan, parameter segera diinisialisasi pada pembuatan model secara sharded alih-alih menunda inisialisasi parameter, sehingga setiap peringkat menginisialisasi dan menyimpan pecahan parameternya sendiri. -
Saat paralelisme data sharded diaktifkan, pustaka melakukan kliping gradien secara internal saat panggilan berjalan.
optimizer.step()Anda tidak perlu menggunakan utilitas APIs untuk kliping gradien, seperti.torch.nn.utils.clip_grad_norm_()Untuk menyesuaikan nilai ambang batas untuk kliping gradien, Anda dapat mengaturnya melalui sdp_gradient_clippingparameter untuk konfigurasi parameter distribusi saat Anda membuat SageMaker PyTorch estimator, seperti yang ditunjukkan di bagian. Cara menerapkan paralelisme data sharded ke pekerjaan pelatihan Anda
