Terjemahan disediakan oleh mesin penerjemah. Jika konten terjemahan yang diberikan bertentangan dengan versi bahasa Inggris aslinya, utamakan versi bahasa Inggris.
Bagaimana Object2Vec Bekerja
Saat menggunakan algoritma Amazon SageMaker AI Object2Vec, Anda mengikuti alur kerja standar: memproses data, melatih model, dan menghasilkan kesimpulan.
Langkah 1: Proses Data
Selama pra-pemrosesan, konversi data ke format file teks JSON Linesnp.random.shuffle; untuk Unix,. shuf
Langkah 2: Latih Model
Algoritma SageMaker AI Object2Vec memiliki komponen utama berikut:
-
Dua saluran input — Saluran input mengambil sepasang objek dari jenis yang sama atau berbeda sebagai input, dan meneruskannya ke encoder independen dan dapat disesuaikan.
-
Dua encoder — Dua encoder, enc0 dan enc1, mengubah setiap objek menjadi vektor embedding dengan panjang tetap. Embeddings yang dikodekan dari benda-benda dalam pasangan kemudian diteruskan ke komparator.
-
Komparator — Komparator membandingkan penyematan dengan cara yang berbeda dan menghasilkan skor yang menunjukkan kekuatan hubungan antara objek yang dipasangkan. Dalam skor output untuk pasangan kalimat. Misalnya, 1 menunjukkan hubungan yang kuat antara pasangan kalimat, dan 0 mewakili hubungan yang lemah.
Selama pelatihan, algoritme menerima pasangan objek dan label atau skor hubungannya sebagai input. Objek di setiap pasangan dapat dari jenis yang berbeda, seperti yang dijelaskan sebelumnya. Jika input ke kedua encoder terdiri dari unit tingkat token yang sama, Anda dapat menggunakan lapisan penyematan token bersama dengan menyetel tied_token_embedding_weight hyperparameter saat Anda membuat pekerjaan pelatihan. True Ini dimungkinkan, misalnya, ketika membandingkan kalimat yang keduanya memiliki satuan tingkat token kata. Untuk menghasilkan sampel negatif pada tingkat tertentu, atur negative_sampling_rate hiperparameter ke rasio sampel negatif dan positif yang diinginkan. Hiperparameter ini mempercepat pembelajaran bagaimana membedakan antara sampel positif yang diamati dalam data pelatihan dan sampel negatif yang tidak mungkin diamati.
Pasangan objek dilewatkan melalui encoder independen dan dapat disesuaikan yang kompatibel dengan jenis input objek yang sesuai. Encoder mengubah setiap objek berpasangan menjadi vektor penyematan dengan panjang tetap dengan panjang yang sama. Pasangan vektor diteruskan ke operator komparator, yang merakit vektor menjadi satu vektor menggunakan nilai yang ditentukan dalam hyperparameter he. comparator_list Vektor yang dirakit kemudian melewati lapisan multilayer perceptron (MLP), yang menghasilkan output yang dibandingkan fungsi kerugian dengan label yang Anda berikan. Perbandingan ini mengevaluasi kekuatan hubungan antara objek dalam pasangan seperti yang diprediksi oleh model. Gambar berikut menunjukkan alur kerja ini.
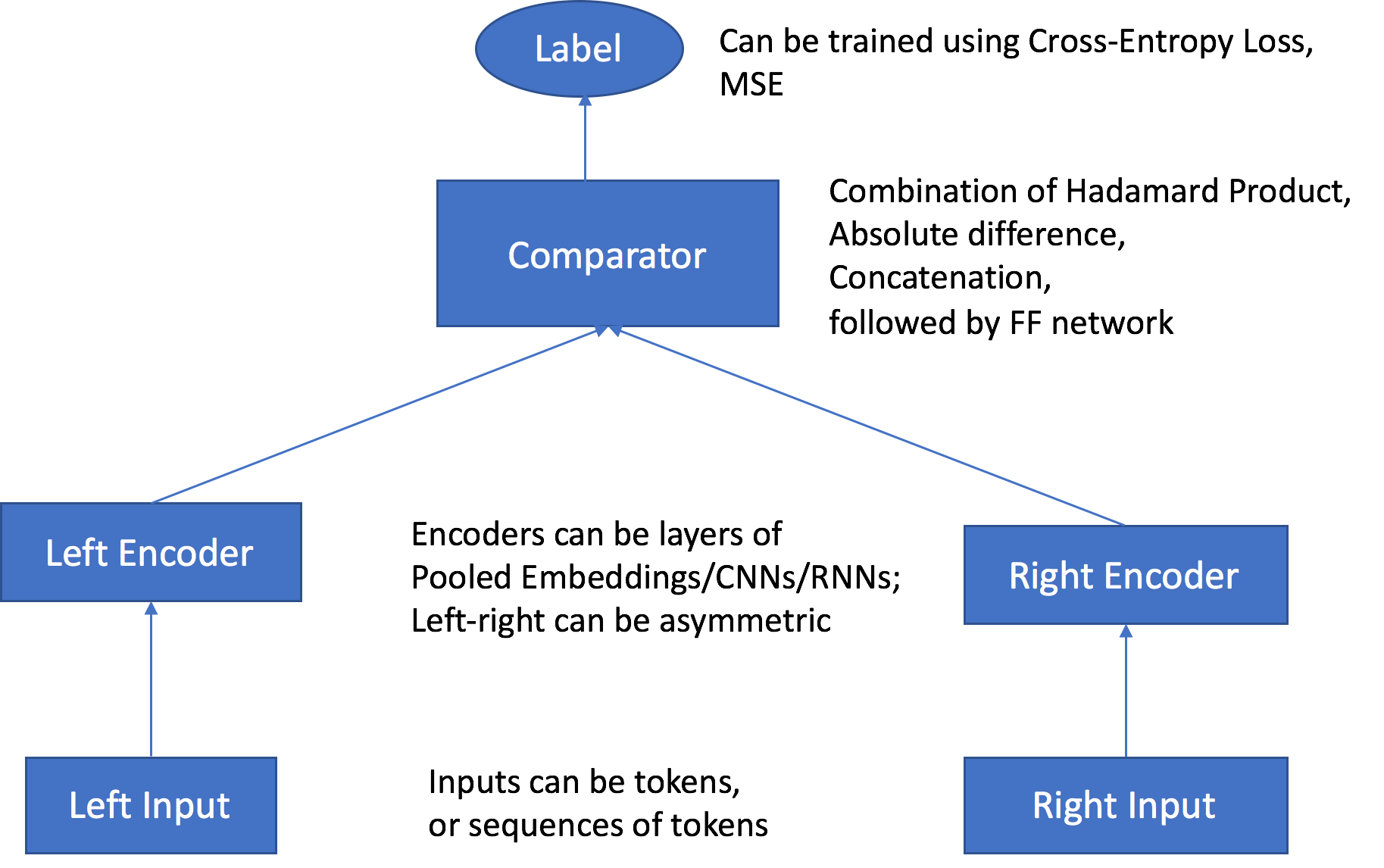
Arsitektur Algoritma Object2Vec dari Input Data ke Skor
Langkah 3: Menghasilkan Inferensi
Setelah model dilatih, Anda dapat menggunakan encoder terlatih untuk memproses objek input atau untuk melakukan dua jenis inferensi:
-
Untuk mengubah objek masukan tunggal menjadi embeddings dengan panjang tetap menggunakan encoder yang sesuai
-
Untuk memprediksi label hubungan atau skor antara sepasang objek masukan
Server inferensi secara otomatis mencari tahu jenis mana yang diminta berdasarkan data input. Untuk mendapatkan embeddings sebagai output, berikan hanya satu input. Untuk memprediksi label hubungan atau skor, berikan kedua input dalam pasangan.
