Terjemahan disediakan oleh mesin penerjemah. Jika konten terjemahan yang diberikan bertentangan dengan versi bahasa Inggris aslinya, utamakan versi bahasa Inggris.
Terapkan model dengan Inferensi Tanpa SageMaker Server Amazon
Amazon SageMaker Serverless Inference adalah opsi inferensi yang dibuat khusus yang memungkinkan Anda menerapkan dan menskalakan model ML tanpa mengonfigurasi atau mengelola infrastruktur yang mendasarinya. Inferensi Tanpa Server On-Demand sangat ideal untuk beban kerja yang memiliki periode idle antara lonjakan lalu lintas dan dapat mentolerir start dingin. Titik akhir tanpa server secara otomatis meluncurkan sumber daya komputasi dan menskalakannya masuk dan keluar tergantung pada lalu lintas, sehingga tidak perlu memilih jenis instance atau mengelola kebijakan penskalaan. Ini menghilangkan beban berat yang tidak terdiferensiasi dalam memilih dan mengelola server. Inferensi Tanpa Server terintegrasi AWS Lambda untuk menawarkan ketersediaan tinggi, toleransi kesalahan bawaan, dan penskalaan otomatis. Dengan pay-per-use model, Inferensi Tanpa Server adalah opsi hemat biaya jika Anda memiliki pola lalu lintas yang jarang atau tidak dapat diprediksi. Selama saat tidak ada permintaan, Inferensi Tanpa Server menskalakan titik akhir Anda menjadi 0, membantu Anda meminimalkan biaya. Untuk informasi selengkapnya tentang harga untuk Inferensi Tanpa Server sesuai permintaan, lihat Harga Amazon. SageMaker
Secara opsional, Anda juga dapat menggunakan Provisioned Concurrency dengan Inferensi Tanpa Server. Inferensi Tanpa Server dengan konkurensi yang disediakan adalah opsi hemat biaya ketika Anda memiliki ledakan yang dapat diprediksi dalam lalu lintas Anda. Provisioned Concurrency memungkinkan Anda menerapkan model pada titik akhir tanpa server dengan kinerja yang dapat diprediksi, dan skalabilitas tinggi dengan menjaga titik akhir tetap hangat. SageMaker AI memastikan bahwa untuk jumlah Provisioned Concurrency yang Anda alokasikan, sumber daya komputasi diinisialisasi dan siap merespons dalam milidetik. Untuk Inferensi Tanpa Server dengan Konkurensi Terketentuan, Anda membayar kapasitas komputasi yang digunakan untuk memproses permintaan inferensi, ditagih oleh milidetik, dan jumlah data yang diproses. Anda juga membayar penggunaan Provisioned Concurrency, berdasarkan memori yang dikonfigurasi, durasi yang disediakan, dan jumlah konkurensi yang diaktifkan. Untuk informasi selengkapnya tentang harga Inferensi Tanpa Server dengan Konkurensi yang Disediakan, lihat Harga Amazon. SageMaker
Inferensi Tanpa Server umumnya tersedia di 21 AWS Wilayah: AS Timur (Virginia N.), AS Timur (Ohio), AS Barat (California N.), AS Barat (Oregon), Afrika (Cape Town), Asia Pasifik (Hong Kong), Asia Pasifik (Mumbai), Asia Pasifik (Tokyo), Asia Pasifik (Seoul), Asia Pasifik (Osaka), Asia Pasifik (Singapura), Asia Pasifik (Sydney)), Kanada (Tengah), Eropa (Frankfurt), Eropa (Irlandia), Eropa (London), Eropa (Paris), Eropa (Stockholm), Eropa (Milan), Timur Tengah (Bahrain), Amerika Selatan (São Paulo). Untuk informasi selengkapnya tentang ketersediaan regional Amazon SageMaker AI, lihat Daftar Layanan AWS Regional
Cara kerjanya
Diagram berikut menunjukkan alur kerja Inferensi Tanpa Server sesuai permintaan dan manfaat menggunakan titik akhir tanpa server.
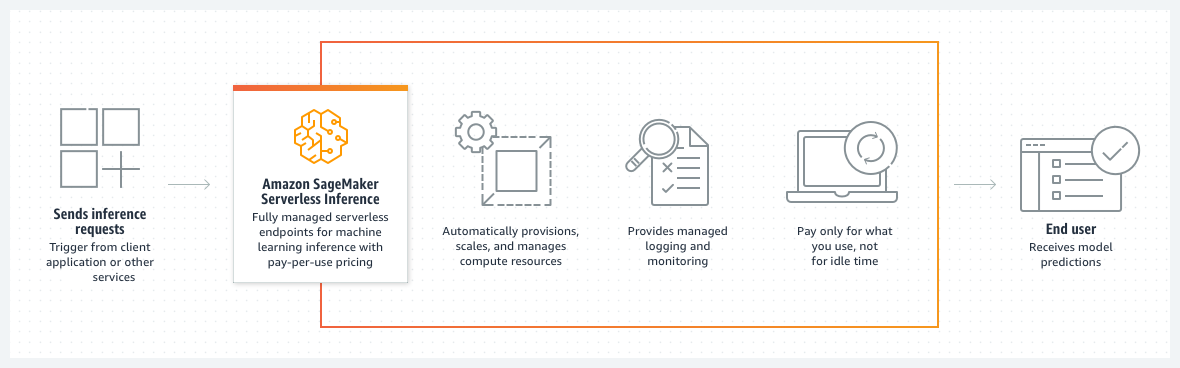
Saat Anda membuat titik akhir tanpa server sesuai permintaan, SageMaker AI menyediakan dan mengelola sumber daya komputasi untuk Anda. Kemudian, Anda dapat membuat permintaan inferensi ke titik akhir dan menerima prediksi model sebagai tanggapan. SageMaker AI menskalakan sumber daya komputasi naik dan turun sesuai kebutuhan untuk menangani lalu lintas permintaan Anda, dan Anda hanya membayar untuk apa yang Anda gunakan.
Untuk Provisioned Concurrency, Serverless Inference juga terintegrasi dengan Application Auto Scaling, sehingga Anda dapat mengelola Provisioned Concurrency berdasarkan metrik target atau jadwal. Untuk informasi selengkapnya, lihat Secara otomatis menskalakan Konkurensi yang Disediakan untuk titik akhir tanpa server.
Bagian berikut memberikan rincian tambahan tentang Inferensi Tanpa Server dan cara kerjanya.
Dukungan kontainer
Untuk wadah endpoint Anda, Anda dapat memilih wadah yang SageMaker disediakan AI atau membawanya sendiri. SageMaker AI menyediakan wadah untuk algoritme bawaan dan gambar Docker bawaan untuk beberapa kerangka kerja pembelajaran mesin yang paling umum, seperti Apache MXNet,,, dan Chainer. TensorFlow PyTorch Untuk daftar gambar yang tersedia, lihat SageMaker Gambar Deep Learning Containers yang Tersedia
Ukuran maksimum gambar kontainer yang dapat Anda gunakan adalah 10 GB. Untuk titik akhir tanpa server, kami sarankan untuk membuat hanya satu pekerja di wadah dan hanya memuat satu salinan model. Perhatikan bahwa ini tidak seperti titik akhir waktu nyata, di mana beberapa kontainer SageMaker AI dapat membuat pekerja untuk setiap vCPU untuk memproses permintaan inferensi dan memuat model di setiap pekerja.
Jika Anda sudah memiliki wadah untuk titik akhir real-time, Anda dapat menggunakan wadah yang sama untuk titik akhir tanpa server Anda, meskipun beberapa kemampuan dikecualikan. Untuk mempelajari lebih lanjut tentang kemampuan container yang tidak didukung dalam Inferensi Tanpa Server, lihat. Pengecualian fitur Jika Anda memilih untuk menggunakan wadah yang sama, SageMaker AI akan menyimpan salinan gambar kontainer Anda hingga Anda menghapus semua titik akhir yang menggunakan gambar tersebut. SageMaker AI mengenkripsi gambar yang disalin saat istirahat dengan kunci milik AI. SageMaker AWS KMS
Ukuran memori
Endpoint tanpa server Anda memiliki ukuran RAM minimum 1024 MB (1 GB), dan ukuran RAM maksimum yang dapat Anda pilih adalah 6144 MB (6 GB). Ukuran memori yang dapat Anda pilih adalah 1024 MB, 2048 MB, 3072 MB, 4096 MB, 5120 MB, atau 6144 MB. Inferensi Tanpa Server secara otomatis menetapkan sumber daya komputasi sebanding dengan memori yang Anda pilih. Jika Anda memilih ukuran memori yang lebih besar, wadah Anda memiliki akses ke lebih banyak vCPUs. Pilih ukuran memori endpoint Anda sesuai dengan ukuran model Anda. Umumnya, ukuran memori harus setidaknya sebesar ukuran model Anda. Anda mungkin perlu melakukan benchmark untuk memilih pilihan memori yang tepat untuk model Anda berdasarkan latensi SLAs Anda. Untuk panduan langkah demi langkah untuk benchmark, lihat Memperkenalkan Toolkit Benchmarking Inferensi SageMaker Tanpa Server Amazon
Terlepas dari ukuran memori yang Anda pilih, titik akhir tanpa server Anda memiliki 5 GB penyimpanan disk sementara yang tersedia. Untuk bantuan terkait masalah izin kontainer saat bekerja dengan penyimpanan, lihatPemecahan Masalah.
Doa bersamaan
On-Demand Serverless Inference mengelola kebijakan dan kuota penskalaan yang telah ditentukan sebelumnya untuk kapasitas titik akhir Anda. Endpoint tanpa server memiliki kuota untuk berapa banyak pemanggilan bersamaan yang dapat diproses pada saat yang bersamaan. Jika titik akhir dipanggil sebelum selesai memproses permintaan pertama, maka ia menangani permintaan kedua secara bersamaan.
Total konkurensi yang dapat Anda bagikan di antara semua titik akhir tanpa server di akun Anda bergantung pada wilayah Anda:
-
Untuk Wilayah AS Timur (Ohio), Timur AS (Virginia N.), AS Barat (Oregon), Asia Pasifik (Singapura), Asia Pasifik (Sydney), Asia Pasifik (Tokyo), Eropa (Frankfurt), dan Eropa (Irlandia), total konkurensi yang dapat Anda bagikan antara semua titik akhir tanpa server per Wilayah di akun Anda adalah 1000.
-
Untuk Wilayah AS Barat (California N.), Afrika (Cape Town), Asia Pasifik (Hong Kong), Asia Pasifik (Mumbai), Asia Pasifik (Osaka), Asia Pasifik (Seoul), Kanada (Tengah), Eropa (London), Eropa (Milan), Eropa (Paris), Eropa (Stockholm), Timur Tengah (Bahrain), dan Wilayah Amerika Selatan (São Paulo), total konkurensi per Wilayah di akun Anda adalah 500.
Anda dapat mengatur konkurensi maksimum untuk satu titik akhir hingga 200, dan jumlah total titik akhir tanpa server yang dapat Anda host di Wilayah adalah 50. Konkurensi maksimum untuk titik akhir individu mencegah titik akhir tersebut mengambil semua pemanggilan yang diizinkan untuk akun Anda, dan pemanggilan titik akhir apa pun di luar maksimum dibatasi.
catatan
Konkurensi yang disediakan yang Anda tetapkan ke titik akhir tanpa server harus selalu kurang dari atau sama dengan konkurensi maksimum yang Anda tetapkan ke titik akhir tersebut.
Untuk mempelajari cara mengatur konkurensi maksimum untuk titik akhir Anda, lihat. Buat konfigurasi titik akhir Untuk informasi selengkapnya tentang kuota dan batasan, lihat titik akhir dan kuota Amazon SageMaker AI di. Referensi Umum AWS Untuk meminta peningkatan batas layanan, hubungi AWS Support
Meminimalkan awal dingin
Jika titik akhir Inferensi Tanpa Server sesuai permintaan Anda tidak menerima lalu lintas untuk sementara waktu dan kemudian titik akhir Anda tiba-tiba menerima permintaan baru, perlu beberapa waktu bagi titik akhir Anda untuk memutar sumber daya komputasi untuk memproses permintaan. Ini disebut awal yang dingin. Karena penyediaan titik akhir tanpa server menghitung sumber daya sesuai permintaan, titik akhir Anda mungkin mengalami awal yang dingin. Cold start juga dapat terjadi jika permintaan bersamaan Anda melebihi penggunaan permintaan bersamaan saat ini. Waktu mulai dingin tergantung pada ukuran model Anda, berapa lama waktu yang dibutuhkan untuk mengunduh model Anda, dan waktu start-up wadah Anda.
Untuk memantau berapa lama waktu mulai dingin Anda, Anda dapat menggunakan CloudWatch metrik Amazon OverheadLatency untuk memantau titik akhir tanpa server Anda. Metrik ini melacak waktu yang diperlukan untuk meluncurkan sumber daya komputasi baru untuk titik akhir Anda. Untuk mempelajari selengkapnya tentang menggunakan CloudWatch metrik dengan titik akhir tanpa server, lihat. Alarm dan log untuk melacak metrik dari titik akhir tanpa server
Anda dapat meminimalkan start dingin dengan menggunakan Provisioned Concurrency. SageMaker AI menjaga titik akhir tetap hangat dan siap merespons dalam milidetik, untuk jumlah Konkurensi Tertentu yang Anda alokasikan.
Pengecualian fitur
Beberapa fitur yang saat ini tersedia untuk Inferensi Real-Time SageMaker AI tidak didukung untuk Inferensi Tanpa Server, termasuk, paket model AWS pasar GPUs, pendaftar Docker pribadi, Titik Akhir Multi-Model, konfigurasi VPC, isolasi jaringan, pengambilan data, beberapa varian produksi, Monitor Model, dan saluran pipa inferensi.
Anda tidak dapat mengonversi titik akhir real-time berbasis instans menjadi titik akhir tanpa server. Jika Anda mencoba memperbarui titik akhir real-time Anda ke tanpa server, Anda menerima pesan. ValidationError Anda dapat mengonversi titik akhir tanpa server menjadi real-time, tetapi setelah Anda melakukan pembaruan, Anda tidak dapat mengembalikannya ke tanpa server.
Memulai
Anda dapat membuat, memperbarui, mendeskripsikan, dan menghapus titik akhir tanpa server menggunakan konsol SageMaker AI, SDK AWS SDKs Amazon SageMaker Python
catatan
Application Auto Scaling untuk Inferensi Tanpa Server dengan Konkurensi yang Disediakan saat ini tidak didukung pada. AWS CloudFormation
Contoh notebook dan blog
