Terjemahan disediakan oleh mesin penerjemah. Jika konten terjemahan yang diberikan bertentangan dengan versi bahasa Inggris aslinya, utamakan versi bahasa Inggris.
SageMaker Pemecahan Masalah Kompiler Pelatihan
penting
Amazon Web Services (AWS) mengumumkan bahwa tidak akan ada rilis baru atau versi SageMaker Training Compiler. Anda dapat terus menggunakan SageMaker Training Compiler melalui AWS Deep Learning Containers (DLCs) for SageMaker Training yang ada. Penting untuk dicatat bahwa meskipun yang ada DLCs tetap dapat diakses, mereka tidak akan lagi menerima tambalan atau pembaruan AWS, sesuai dengan Kebijakan Dukungan Framework AWS Deep Learning Containers.
Jika Anda mengalami kesalahan, Anda dapat menggunakan daftar berikut untuk mencoba memecahkan masalah pekerjaan pelatihan Anda. Jika Anda membutuhkan dukungan lebih lanjut, hubungi SageMaker tim melalui AWS Support
Pekerjaan pelatihan tidak konvergen seperti yang diharapkan jika dibandingkan dengan pekerjaan pelatihan kerangka kerja asli
Masalah konvergensi berkisar dari “model tidak belajar saat SageMaker Training Compiler dihidupkan” hingga “model sedang belajar tetapi lebih lambat dari kerangka kerja asli”. Dalam panduan pemecahan masalah ini, kami menganggap konvergensi Anda baik-baik saja tanpa SageMaker Training Compiler (dalam kerangka kerja asli) dan menganggap ini sebagai baseline.
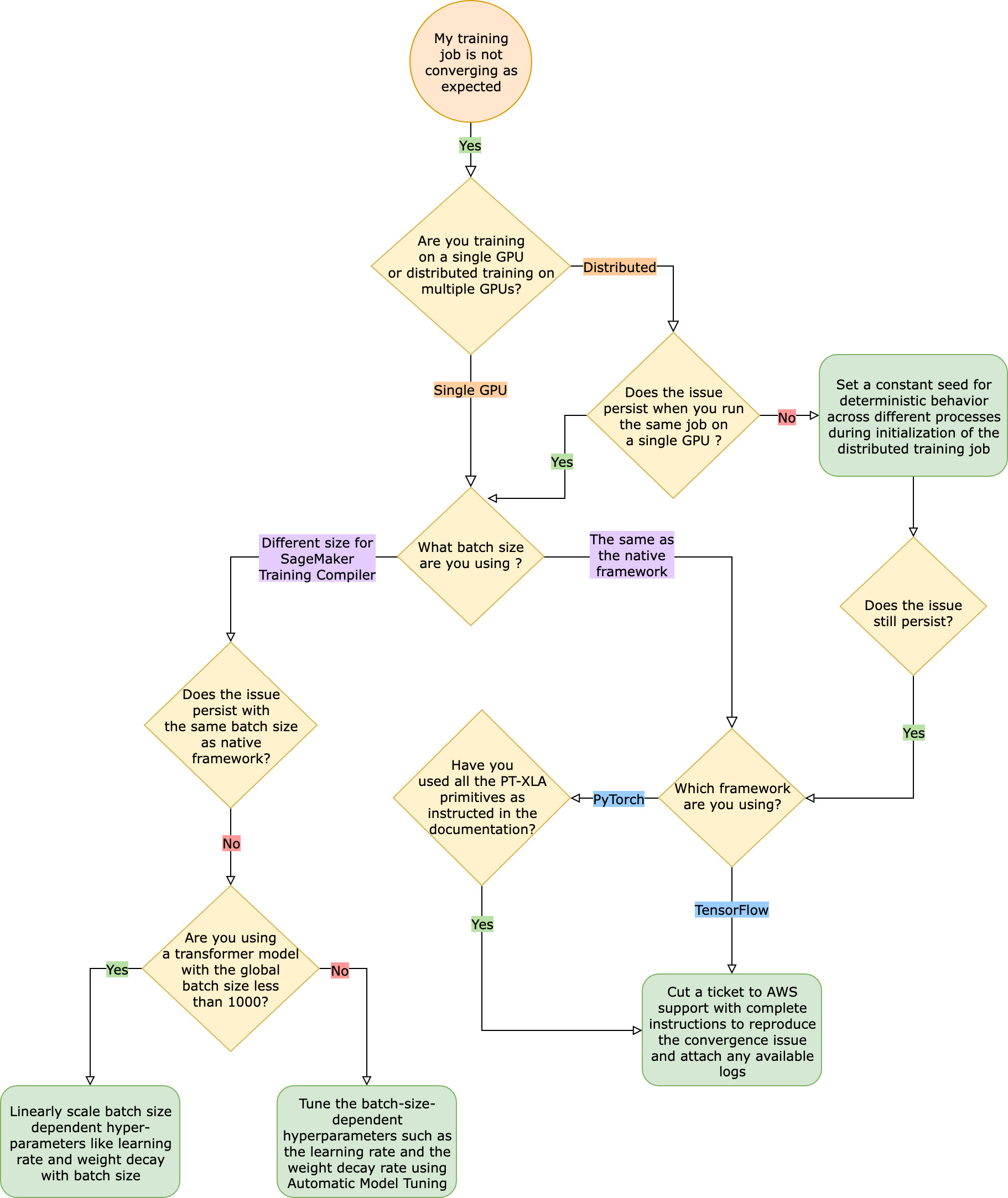
Ketika dihadapkan dengan masalah konvergensi seperti itu, langkah pertama adalah mengidentifikasi apakah masalah ini terbatas pada pelatihan terdistribusi atau berasal dari GPU pelatihan tunggal. Pelatihan terdistribusi dengan SageMaker Training Compiler adalah perpanjangan dari GPU pelatihan tunggal dengan langkah-langkah tambahan.
-
Siapkan cluster dengan beberapa instance atauGPUs.
-
Mendistribusikan data input ke semua pekerja.
-
Sinkronkan pembaruan model dari semua pekerja.
Oleh karena itu, setiap masalah konvergensi dalam GPU pelatihan tunggal menyebar ke pelatihan terdistribusi dengan banyak pekerja.
Masalah konvergensi yang terjadi dalam pelatihan tunggal GPU
Jika masalah konvergensi Anda berasal dari GPU pelatihan tunggal, ini kemungkinan karena pengaturan yang tidak tepat untuk hiperparameter atau. torch_xla APIs
Periksa hiperparameter
SageMaker Pelatihan dengan Training Compiler menyebabkan perubahan jejak memori model. Kompiler secara cerdas menengahi antara penggunaan kembali dan komputasi ulang yang mengarah ke peningkatan atau penurunan konsumsi memori yang sesuai. Untuk memanfaatkan ini, penting untuk menyetel ulang ukuran batch dan hyperparameter terkait saat memigrasikan pekerjaan pelatihan ke SageMaker Training Compiler. Namun, pengaturan hiperparameter yang salah sering menyebabkan osilasi dalam kehilangan pelatihan dan mungkin konvergensi yang lebih lambat sebagai hasilnya. Dalam kasus yang jarang terjadi, hiperparameter agresif dapat mengakibatkan model tidak belajar (metrik kehilangan pelatihan tidak berkurang atau kembaliNaN). Untuk mengidentifikasi apakah masalah konvergensi disebabkan oleh hiperparameter, lakukan side-by-side pengujian dua pekerjaan pelatihan dengan dan tanpa SageMaker Training Compiler sambil menjaga semua hyperparameter tetap sama.
Periksa apakah torch_xla APIs sudah diatur dengan benar untuk GPU pelatihan tunggal
Jika masalah konvergensi berlanjut dengan hiperparameter dasar, Anda perlu memeriksa apakah ada penggunaan yang tidak tepat torch_xlaAPIs, khususnya yang untuk memperbarui model. Pada dasarnya, torch_xla terus mengakumulasi instruksi (menunda eksekusi) dalam bentuk grafik hingga secara eksplisit diinstruksikan untuk menjalankan grafik akumulasi. torch_xla.core.xla_model.mark_step()Fungsi ini memfasilitasi pelaksanaan grafik yang terakumulasi. Eksekusi grafik harus disinkronkan menggunakan fungsi ini setelah setiap pembaruan model dan sebelum mencetak dan mencatat variabel apa pun. Jika tidak memiliki langkah sinkronisasi, model mungkin menggunakan nilai basi dari memori selama pencetakan, log, dan penerusan berikutnya, alih-alih menggunakan nilai terbaru yang harus disinkronkan setelah setiap iterasi dan pembaruan model.
Ini bisa lebih rumit saat menggunakan SageMaker Training Compiler dengan penskalaan gradien (mungkin dari penggunaanAMP) atau teknik kliping gradien. Urutan perhitungan gradien yang sesuai dengan AMP adalah sebagai berikut.
-
Komputasi gradien dengan penskalaan
-
Gradien un-scaling, kliping gradien, dan kemudian penskalaan
-
Pembaruan model
-
Menyinkronkan eksekusi grafik dengan
mark_step()
Untuk menemukan yang tepat APIs untuk operasi yang disebutkan dalam daftar, lihat panduan untuk memigrasikan skrip pelatihan Anda ke SageMaker Training Compiler.
Pertimbangkan untuk menggunakan Penyetelan Model Otomatis
Jika masalah konvergensi muncul saat menyetel ulang ukuran batch dan hiperparameter terkait seperti kecepatan pembelajaran saat menggunakan Kompiler SageMaker Pelatihan, pertimbangkan untuk menggunakan Penyetelan Model Otomatis untuk menyetel hiperparameter Anda. Anda dapat merujuk ke contoh notebook tentang tuning hyperparameters dengan SageMaker Training
Masalah konvergensi yang terjadi dalam pelatihan terdistribusi
Jika masalah konvergensi Anda berlanjut dalam pelatihan terdistribusi, ini kemungkinan karena pengaturan yang tidak tepat untuk inisialisasi berat badan atau. torch_xla APIs
Periksa inisialisasi berat di seluruh pekerja
Jika masalah konvergensi muncul saat menjalankan pekerjaan pelatihan terdistribusi dengan banyak pekerja, pastikan ada perilaku deterministik yang seragam di semua pekerja dengan menetapkan benih konstan jika berlaku. Waspadalah terhadap teknik seperti inisialisasi berat badan, yang melibatkan pengacakan. Setiap pekerja mungkin akhirnya melatih model yang berbeda tanpa adanya benih yang konstan.
Periksa apakah torch_xla APIs sudah diatur dengan benar untuk pelatihan terdistribusi
Jika masalah masih berlanjut, ini kemungkinan karena penggunaan yang tidak tepat torch_xla APIs untuk pelatihan terdistribusi. Pastikan Anda menambahkan yang berikut ini di estimator Anda untuk menyiapkan klaster untuk pelatihan terdistribusi dengan SageMaker Training Compiler.
distribution={'torchxla': {'enabled': True}}
Ini harus disertai dengan fungsi _mp_fn(index) dalam skrip pelatihan Anda, yang dipanggil sekali per pekerja. Tanpa mp_fn(index) fungsi, Anda mungkin akhirnya membiarkan setiap pekerja melatih model secara mandiri tanpa berbagi pembaruan model.
Selanjutnya, pastikan bahwa Anda menggunakan torch_xla.distributed.parallel_loader.MpDeviceLoader API bersama dengan sampler data terdistribusi, seperti yang dipandu dalam dokumentasi tentang memigrasi skrip pelatihan Anda ke SageMaker Training Compiler, seperti pada contoh berikut.
torch.utils.data.distributed.DistributedSampler()
Ini memastikan bahwa data input didistribusikan dengan benar di semua pekerja.
Terakhir, untuk menyinkronkan pembaruan model dari semua pekerja, gunakan torch_xla.core.xla_model._fetch_gradients untuk mengumpulkan gradien dari semua pekerja dan torch_xla.core.xla_model.all_reduce untuk menggabungkan semua gradien yang dikumpulkan menjadi satu pembaruan.
Ini bisa lebih rumit saat menggunakan SageMaker Training Compiler dengan penskalaan gradien (mungkin dari penggunaanAMP) atau teknik kliping gradien. Urutan perhitungan gradien yang sesuai dengan AMP adalah sebagai berikut.
-
Komputasi gradien dengan penskalaan
-
Sinkronisasi gradien di semua pekerja
-
Gradien un-scaling, kliping gradien, dan kemudian penskalaan gradien
-
Pembaruan model
-
Menyinkronkan eksekusi grafik dengan
mark_step()
Perhatikan bahwa daftar periksa ini memiliki item tambahan untuk menyinkronkan semua pekerja, dibandingkan dengan daftar periksa untuk pelatihan tunggal. GPU
Pekerjaan pelatihan gagal karena PyTorch XLA hilang/konfigurasi
Jika tugas pelatihan gagal dengan pesan Missing XLA configuration kesalahan, itu mungkin karena kesalahan konfigurasi dalam jumlah GPUs per instance yang Anda gunakan.
XLAmembutuhkan variabel lingkungan tambahan untuk menyusun pekerjaan pelatihan. Variabel lingkungan hilang yang paling umum adalahGPU_NUM_DEVICES. Agar kompiler berfungsi dengan baik, Anda harus mengatur variabel lingkungan ini sama dengan jumlah GPUs per instance.
Ada tiga pendekatan untuk mengatur variabel GPU_NUM_DEVICES lingkungan:
-
Pendekatan 1 — Gunakan
environmentargumen kelas SageMaker estimator. Misalnya, jika Anda menggunakanml.p3.8xlargeinstance yang memiliki empatGPUs, lakukan hal berikut:# Using the SageMaker Python SDK's HuggingFace estimator hf_estimator=HuggingFace( ... instance_type="ml.p3.8xlarge", hyperparameters={...}, environment={ ... "GPU_NUM_DEVICES": "4" # corresponds to number of GPUs on the specified instance }, ) -
Pendekatan 2 — Gunakan
hyperparametersargumen kelas SageMaker estimator dan uraikan dalam skrip pelatihan Anda.-
Untuk menentukan jumlahGPUs, tambahkan pasangan kunci-nilai ke argumen.
hyperparametersMisalnya, jika Anda menggunakan
ml.p3.8xlargeinstance yang memiliki empatGPUs, lakukan hal berikut:# Using the SageMaker Python SDK's HuggingFace estimator hf_estimator=HuggingFace( ... entry_point = "train.py" instance_type= "ml.p3.8xlarge", hyperparameters = { ... "n_gpus":4# corresponds to number of GPUs on specified instance } ) hf_estimator.fit() -
Dalam skrip pelatihan Anda, parse
n_gpushyperparameter dan tentukan sebagai input untuk variabelGPU_NUM_DEVICESlingkungan.# train.py import os, argparse if __name__ == "__main__": parser = argparse.ArgumentParser() ... # Data, model, and output directories parser.add_argument("--output_data_dir", type=str, default=os.environ["SM_OUTPUT_DATA_DIR"]) parser.add_argument("--model_dir", type=str, default=os.environ["SM_MODEL_DIR"]) parser.add_argument("--training_dir", type=str, default=os.environ["SM_CHANNEL_TRAIN"]) parser.add_argument("--test_dir", type=str, default=os.environ["SM_CHANNEL_TEST"]) parser.add_argument("--n_gpus", type=str, default=os.environ["SM_NUM_GPUS"]) args, _ = parser.parse_known_args() os.environ["GPU_NUM_DEVICES"] = args.n_gpus
-
-
Pendekatan 3 — Hard-code variabel
GPU_NUM_DEVICESlingkungan dalam skrip pelatihan Anda. Misalnya, tambahkan berikut ini ke skrip Anda jika Anda menggunakan instance yang memiliki empatGPUs.# train.py import os os.environ["GPU_NUM_DEVICES"] =4
Tip
Untuk mengetahui jumlah GPU perangkat pada instance pembelajaran mesin yang ingin Anda gunakan, lihat Komputasi Akselerasi
SageMaker Training Compiler tidak mengurangi total waktu pelatihan
Jika total waktu pelatihan tidak berkurang dengan SageMaker Training Compiler, kami sangat menyarankan Anda untuk memeriksa SageMaker Praktik dan Pertimbangan Terbaik Kompiler Pelatihan halaman untuk memeriksa konfigurasi pelatihan Anda, strategi padding untuk bentuk tensor input, dan hyperparameters.
