Terjemahan disediakan oleh mesin penerjemah. Jika konten terjemahan yang diberikan bertentangan dengan versi bahasa Inggris aslinya, utamakan versi bahasa Inggris.
Identifikasi bahasa dengan pekerjaan transkripsi batch
Gunakan identifikasi bahasa batch untuk secara otomatis mengidentifikasi bahasa, atau bahasa, dalam file media Anda.
Jika media Anda hanya berisi satu bahasa, Anda dapat mengaktifkan identifikasi bahasa tunggal, yang mengidentifikasi bahasa dominan yang digunakan dalam file media Anda dan membuat transkrip Anda hanya menggunakan bahasa ini.
Jika media Anda berisi lebih dari satu bahasa, Anda dapat mengaktifkan identifikasi multi-bahasa, yang mengidentifikasi semua bahasa yang digunakan dalam file media Anda dan membuat transkrip Anda menggunakan setiap bahasa yang diidentifikasi. Perhatikan bahwa transkrip multi-bahasa diproduksi. Anda dapat menggunakan layanan lain, seperti Amazon Translate, untuk menerjemahkan transkrip Anda.
Lihat tabel bahasa yang didukung untuk daftar lengkap bahasa yang didukung dan kode bahasa terkait.
Untuk hasil terbaik, pastikan file media Anda berisi setidaknya 30 detik pidato.
Untuk contoh penggunaan dengan SDK AWS Management Console, AWS CLI, dan AWS Python, lihat. Menggunakan identifikasi bahasa dengan transkripsi batch
Mengidentifikasi bahasa dalam audio multi-bahasa
Identifikasi multi-bahasa ditujukan untuk file media multi-bahasa, dan memberi Anda transkrip yang mencerminkan semua bahasa yang didukung yang digunakan di media Anda. Ini berarti bahwa jika penutur mengubah bahasa di tengah percakapan, atau jika setiap peserta berbicara bahasa yang berbeda, output transkripsi Anda mendeteksi dan mentranskripsikan setiap bahasa dengan benar. Misalnya, jika media Anda berisi pembicara bilingual yang bergantian antara bahasa Inggris AS (en-US) dan Hindi (hi-IN), identifikasi multi-bahasa dapat mengidentifikasi dan mentranskripsikan bahasa Inggris AS lisan sebagai dan bahasa Hindi yang diucapkan sebagaien-US. hi-IN
Ini berbeda dari identifikasi bahasa tunggal, di mana hanya satu bahasa dominan yang digunakan untuk membuat transkrip. Dalam hal ini, bahasa lisan apa pun yang bukan bahasa dominan ditranskripsikan secara tidak benar.
catatan
Redaksi dan model bahasa kustom saat ini tidak didukung dengan identifikasi multi-bahasa.
catatan
Bahasa-bahasa berikut saat ini didukung dengan identifikasi multi-bahasa: En-AB, en-AU, en-GB, en-IE, en-in, en-NZ, en-US, en-WL, en-ZA, es-ES, es-US, fr-CA, fr-FR, zh-CN, zh-TW, Pt-BR, Pt-pt, de-ch, de-de, af-za, ar-Ae, da-dK, He-il, Hi-il, Dalam, Id-ID, Fa-ir, IT-it, Ja-jp, Ko-kr, MS-saya, Nl-nl, Ru-ru, Ta-in, TE-in, TH-th, Tr-tr
Transkrip multi-bahasa memberikan ringkasan bahasa yang terdeteksi dan total waktu setiap bahasa digunakan di media Anda. Inilah contohnya:
"results": { "transcripts": [ { "transcript": "welcome to Amazon transcribe. ये तो उदाहरण हैं क्या कैसे कर सकते हैं ।一つのファイルに複数の言語を書き写す" } ],..."language_codes": [ { "language_code": "en-US", "duration_in_seconds": 2.45 }, { "language_code": "hi-IN", "duration_in_seconds": 5.325 }, { "language_code": "ja-JP", "duration_in_seconds": 4.15 } ] }
Meningkatkan akurasi identifikasi bahasa
Dengan identifikasi bahasa, Anda memiliki opsi untuk memasukkan daftar bahasa yang menurut Anda mungkin ada di media Anda. Menyertakan opsi bahasa (LanguageOptions) membatasi Amazon Transcribe penggunaan hanya bahasa yang Anda tentukan saat mencocokkan audio Anda dengan bahasa yang benar, yang dapat mempercepat identifikasi bahasa dan meningkatkan akurasi yang terkait dengan penetapan dialek bahasa yang benar.
Jika Anda memilih untuk memasukkan kode bahasa, Anda harus menyertakan setidaknya dua. Tidak ada batasan jumlah kode bahasa yang dapat Anda sertakan, tetapi sebaiknya gunakan antara dua dan lima untuk efisiensi dan akurasi yang optimal.
catatan
Jika Anda menyertakan kode bahasa dengan permintaan Anda dan tidak ada kode bahasa yang Anda berikan yang cocok dengan bahasa, atau bahasa, yang diidentifikasi dalam audio Anda, Amazon Transcribe memilih kecocokan bahasa terdekat dari kode bahasa yang Anda tentukan. Kemudian menghasilkan transkrip dalam bahasa itu. Misalnya, jika media Anda dalam bahasa Inggris AS (en-US) dan Anda memberikan Amazon Transcribe kode bahasa,, dan zh-CN fr-FRde-DE, Amazon Transcribe kemungkinan akan mencocokkan media Anda dengan bahasa Jerman (de-DE) dan menghasilkan transkripsi berbahasa Jerman. Ketidakcocokan kode bahasa dan bahasa lisan dapat mengakibatkan transkrip yang tidak akurat, jadi sebaiknya berhati-hati saat menyertakan kode bahasa.
Menggabungkan identifikasi bahasa dengan Amazon Transcribe fitur lain
Anda dapat menggunakan identifikasi bahasa batch dalam kombinasi dengan Amazon Transcribe
fitur lainnya. Jika menggabungkan identifikasi bahasa dengan fitur lain, Anda terbatas pada bahasa yang didukung dengan fitur tersebut. Misalnya, jika menggunakan identifikasi bahasa dengan redaksi konten, Anda terbatas pada bahasa Inggris AS (en-US) atau Spanyol AS (es-US), karena ini hanya bahasa yang tersedia untuk redaksi. Lihat Bahasa yang didukung dan fitur khusus bahasa untuk informasi lebih lanjut.
penting
Jika Anda menggunakan identifikasi bahasa otomatis dengan redaksi konten diaktifkan dan audio Anda berisi bahasa selain bahasa Inggris AS (en-US) atau Spanyol AS (es-US), hanya konten Inggris AS atau Spanyol AS yang disunting dalam transkrip Anda. Bahasa lain tidak dapat disunting dan tidak ada peringatan atau kegagalan pekerjaan.
Model bahasa kustom, kosakata kustom, dan filter kosakata kustom
Jika Anda ingin menambahkan satu atau lebih model bahasa kustom, kosakata kustom, atau filter kosakata kustom ke permintaan identifikasi bahasa Anda, Anda harus menyertakan parameter. LanguageIdSettings Anda kemudian dapat menentukan kode bahasa dengan model bahasa kustom yang sesuai, kosakata kustom, dan filter kosakata kustom. Perhatikan bahwa identifikasi multi-bahasa tidak mendukung model bahasa khusus.
Disarankan agar Anda menyertakan LanguageOptions saat menggunakan LanguageIdSettingsuntuk memastikan bahwa dialek bahasa yang benar diidentifikasi. Misalnya, jika Anda menentukan kosakata en-US khusus, tetapi Amazon Transcribe menentukan bahwa bahasa yang digunakan di media Andaen-AU, kosakata khusus Anda tidak diterapkan pada transkripsi Anda. Jika Anda menyertakan LanguageOptions dan menentukan en-US sebagai satu-satunya dialek bahasa Inggris, kosakata khusus Anda diterapkan pada transkripsi Anda.
Untuk contoh LanguageIdSettingsdalam permintaan, lihat Opsi 2 di panel AWS CLIdan AWS SDKstarik-turun di bagianMenggunakan identifikasi bahasa dengan transkripsi batch.
Menggunakan identifikasi bahasa dengan transkripsi batch
Anda dapat menggunakan identifikasi bahasa otomatis dalam pekerjaan transkripsi batch menggunakan AWS Management Console, AWS CLI, atau AWS SDKs; lihat contoh berikut:
-
Masuk ke AWS Management Console
. -
Di panel navigasi, pilih Pekerjaan transkripsi, lalu pilih Buat pekerjaan (kanan atas). Ini membuka halaman Tentukan detail pekerjaan.
-
Di panel Pengaturan pekerjaan, temukan bagian Pengaturan bahasa dan pilih Identifikasi bahasa otomatis atau Identifikasi beberapa bahasa otomatis.
Anda memiliki opsi untuk memilih beberapa opsi bahasa (dari kotak tarik-turun Pilih bahasa) jika Anda tahu bahasa mana yang ada di file audio Anda. Menyediakan pilihan bahasa dapat meningkatkan akurasi, tetapi tidak diperlukan.
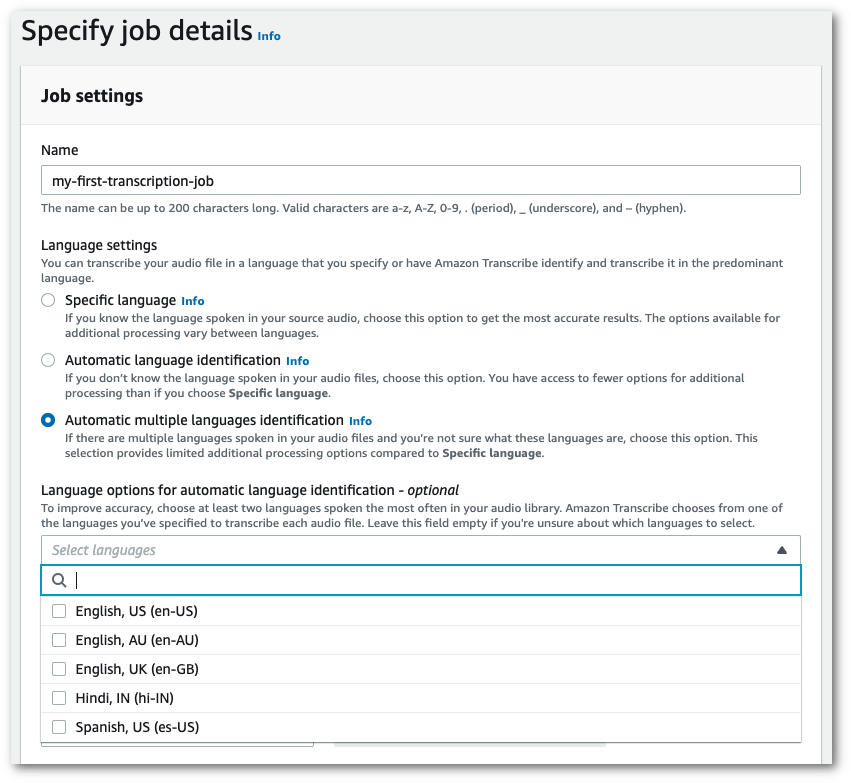
-
Isi kolom lain yang ingin Anda sertakan di halaman Tentukan detail pekerjaan, lalu pilih Berikutnya. Ini membawa Anda ke halaman Konfigurasi pekerjaan - opsional.
-
Pilih Buat pekerjaan untuk menjalankan pekerjaan transkripsi Anda.
Contoh ini menggunakan start-transcription-jobIdentifyLanguage parameter. Untuk informasi selengkapnya, lihat StartTranscriptionJob dan LanguageIdSettings.
Opsi 1: Tanpa language-id-settings parameter. Gunakan opsi ini jika Anda tidak menyertakan model bahasa khusus, kosakata khusus, atau filter kosakata khusus dalam permintaan Anda. language-optionsbersifat opsional, tetapi direkomendasikan.
aws transcribe start-transcription-job \ --regionus-west-2\ --transcription-job-namemy-first-transcription-job\ --media MediaFileUri=s3://amzn-s3-demo-bucket/my-input-files/my-media-file.flac\ --output-bucket-nameamzn-s3-demo-bucket\ --output-keymy-output-files/ \ --identify-language \ (or --identify-multiple-languages) \ --language-options "en-US" "hi-IN"
Opsi 2: Dengan language-id-settings parameter. Gunakan opsi ini jika Anda menyertakan model bahasa khusus, kosakata khusus, atau filter kosakata khusus dalam permintaan Anda.
aws transcribe start-transcription-job \ --regionus-west-2\ --transcription-job-namemy-first-transcription-job\ --media MediaFileUri=s3://amzn-s3-demo-bucket/my-input-files/my-media-file.flac\ --output-bucket-nameamzn-s3-demo-bucket\ --output-keymy-output-files/ \ --identify-language \ (or --identify-multiple-languages) --language-options "en-US" "hi-IN" \ --language-id-settingsen-US=VocabularyName=my-en-US-vocabulary,en-US=VocabularyFilterName=my-en-US-vocabulary-filter,en-US=LanguageModelName=my-en-US-language-model,hi-IN=VocabularyName=my-hi-IN-vocabulary,hi-IN=VocabularyFilterName=my-hi-IN-vocabulary-filter
Berikut contoh lain menggunakan start-transcription-job
aws transcribe start-transcription-job \ --regionus-west-2\ --cli-input-json file://filepath/my-first-language-id-job.json
File my-first-language-id-job.json berisi badan permintaan berikut.
Opsi 1: Tanpa LanguageIdSettings parameter. Gunakan opsi ini jika Anda tidak menyertakan model bahasa khusus, kosakata khusus, atau filter kosakata khusus dalam permintaan Anda. LanguageOptionsbersifat opsional, tetapi direkomendasikan.
{ "TranscriptionJobName": "my-first-transcription-job", "Media": { "MediaFileUri": "s3://amzn-s3-demo-bucket/my-input-files/my-media-file.flac" }, "OutputBucketName": "amzn-s3-demo-bucket", "OutputKey": "my-output-files/", "IdentifyLanguage":true, (or "IdentifyMultipleLanguages":true), "LanguageOptions": [ "en-US", "hi-IN" ] }
Opsi 2: Dengan LanguageIdSettings parameter. Gunakan opsi ini jika Anda menyertakan model bahasa khusus, kosakata khusus, atau filter kosakata khusus dalam permintaan Anda.
{ "TranscriptionJobName": "my-first-transcription-job", "Media": { "MediaFileUri": "s3://amzn-s3-demo-bucket/my-input-files/my-media-file.flac" }, "OutputBucketName": "amzn-s3-demo-bucket", "OutputKey": "my-output-files/", "IdentifyLanguage":true, (or "IdentifyMultipleLanguages":true) "LanguageOptions": [ "en-US", "hi-IN" ], "LanguageIdSettings": { "en-US" : { "LanguageModelName": "my-en-US-language-model", "VocabularyFilterName": "my-en-US-vocabulary-filter", "VocabularyName": "my-en-US-vocabulary" }, "hi-IN": { "VocabularyName": "my-hi-IN-vocabulary", "VocabularyFilterName": "my-hi-IN-vocabulary-filter" } } }
Contoh ini menggunakan AWS SDK untuk Python (Boto3) untuk mengidentifikasi bahasa file Anda menggunakan IdentifyLanguage argumen untuk metode start_transcription_jobStartTranscriptionJob dan LanguageIdSettings.
Untuk contoh tambahan menggunakan AWS SDKs, termasuk contoh khusus fitur, skenario, dan lintas layanan, lihat bagian ini. Contoh kode untuk Amazon Transcribe menggunakan AWS SDKs
Opsi 1: Tanpa LanguageIdSettings parameter. Gunakan opsi ini jika Anda tidak menyertakan model bahasa khusus, kosakata khusus, atau filter kosakata khusus dalam permintaan Anda. LanguageOptionsbersifat opsional, tetapi direkomendasikan.
from __future__ import print_function import time import boto3 transcribe = boto3.client('transcribe', 'us-west-2') job_name = "my-first-transcription-job" job_uri = "s3://amzn-s3-demo-bucket/my-input-files/my-media-file.flac" transcribe.start_transcription_job( TranscriptionJobName = job_name, Media = { 'MediaFileUri': job_uri }, OutputBucketName = 'amzn-s3-demo-bucket', OutputKey = 'my-output-files/', MediaFormat = 'flac', IdentifyLanguage =True, (or IdentifyMultipleLanguages =True), LanguageOptions = [ 'en-US', 'hi-IN' ] ) while True: status = transcribe.get_transcription_job(TranscriptionJobName = job_name) if status['TranscriptionJob']['TranscriptionJobStatus'] in ['COMPLETED', 'FAILED']: break print("Not ready yet...") time.sleep(5) print(status)
Opsi 2: Dengan LanguageIdSettings parameter. Gunakan opsi ini jika Anda menyertakan model bahasa khusus, kosakata khusus, atau filter kosakata khusus dalam permintaan Anda.
from __future__ import print_function import time import boto3 transcribe = boto3.client('transcribe') job_name = "my-first-transcription-job" job_uri = "s3://amzn-s3-demo-bucket/my-input-files/my-media-file.flac" transcribe.start_transcription_job( TranscriptionJobName = job_name, Media = { 'MediaFileUri': job_uri }, OutputBucketName = 'amzn-s3-demo-bucket', OutputKey = 'my-output-files/', MediaFormat='flac', IdentifyLanguage=True, (or IdentifyMultipleLanguages=True) LanguageOptions = [ 'en-US', 'hi-IN' ], LanguageIdSettings={ 'en-US': { 'VocabularyName': 'my-en-US-vocabulary', 'VocabularyFilterName': 'my-en-US-vocabulary-filter', 'LanguageModelName': 'my-en-US-language-model' }, 'hi-IN': { 'VocabularyName': 'my-hi-IN-vocabulary', 'VocabularyFilterName': 'my-hi-IN-vocabulary-filter' } } ) while True: status = transcribe.get_transcription_job(TranscriptionJobName = job_name) if status['TranscriptionJob']['TranscriptionJobStatus'] in ['COMPLETED', 'FAILED']: break print("Not ready yet...") time.sleep(5) print(status)
